

Innhold Vis
Cursor oppdaterer nå Composer 2 med en ny versjon hvert femte time – kontinuerlig, automatisk, i produksjon, basert på hva ekte brukere faktisk gjør. Ikke en gang i måneden. Ikke en gang i uken. Hvert femte time, hele dagen. De kaller det real-time reinforcement learning, og det er teknisk sett ganske sprøtt.
Jeg har skrevet om Cursor og Composer 2 før – blant annet den betente saken om Kimi K2.5 og Moonshot AI som Cursor aldri nevnte noe om. Den saken handlet om hva Composer 2 ER. Denne artikkelen handler om noe annet: hvordan modellen faktisk forbedrer seg over tid.
Og metoden de bruker er ganske annerledes enn det de fleste andre AI-selskaper gjør.
Hva er real-time RL egentlig?
Vanlig AI-trening ser slik ut: samle data, tren modellen, evaluer, sjipp til produksjon, vent noen måneder, gjenta. Cursor gjør noe annet.
De serverer Composer 2 direkte til brukere i produksjon. Hvert eneste brukerinteraksjon – hvert godkjente forslag, hvert avviste forslag, hver gang en bruker spør et oppfølgingsspørsmål fordi modellen bommet – alt dette samles inn som treningssignal. Milliarder av tokens fra ekte brukerinteraksjoner per treningssyklus.
Resultatet? En ny modell-checkpoint hvert femte time. Den nye modellen tar over som «Auto»-valget i Cursor. Så neste gang du bruker Cursor, er det ganske sannsynlig at du bruker en annen modell enn du brukte for seks timer siden.
Dette er real-time RL. Modellen optimerer seg mot den faktiske produksjonsstacken din – ikke mot et simulert testmiljø, men mot ekte brukere som prøver å løse ekte problemer.
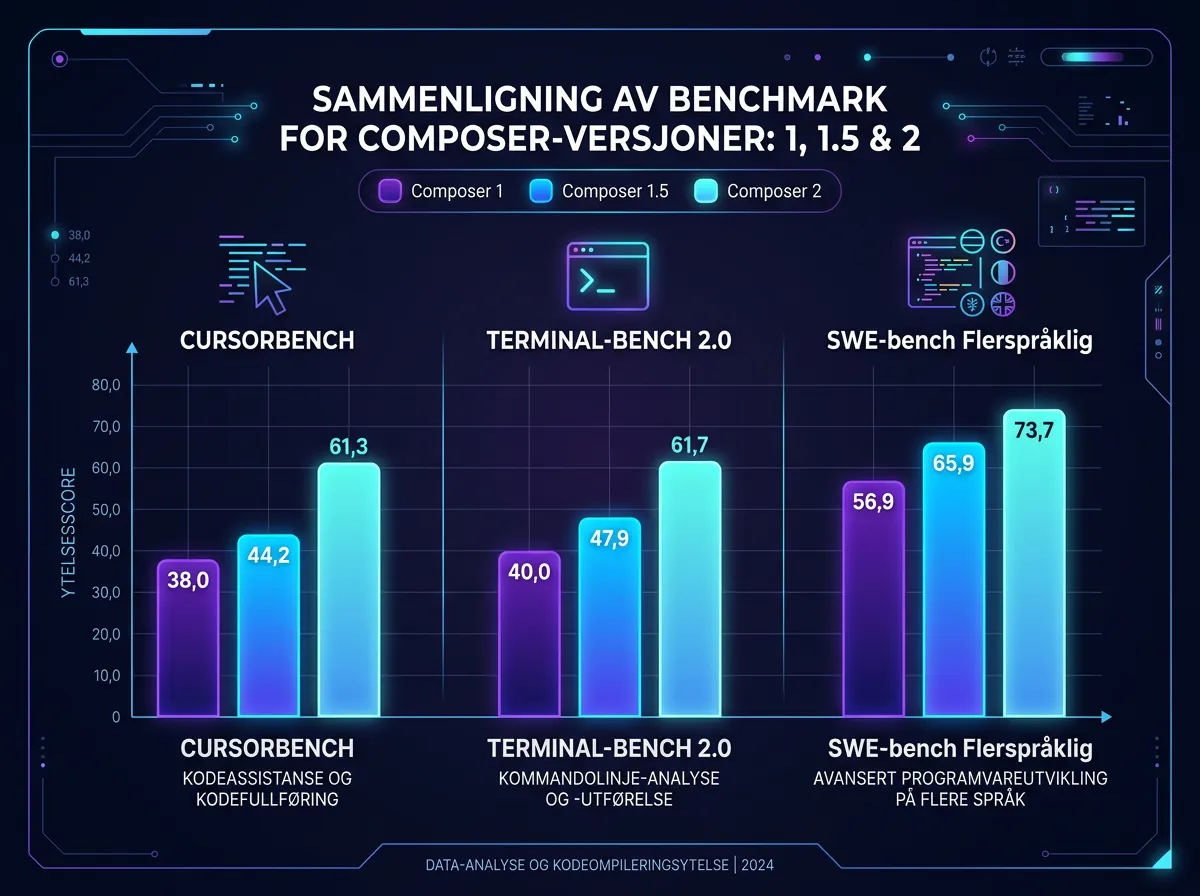
Hva sier tallene om Composer 2?
Cursor har publisert benchmark-resultater fra sin interne Composer 2-rapport som viser utviklingen over modellgenerasjonene:
- CursorBench: Composer 1 scoret 38,0 – Composer 2 scorer 61,3 (61% økning)
- Terminal-Bench 2.0: Fra 40,0 til 61,7
- SWE-bench Multilingual: Fra 56,9 til 73,7
Real-time RL bidrar ikke til disse store modellhopp-tallene (det er pretraining og RL på lange oppgaver som gjør det). Men real-time RL er det som skjer mellom de store versjonene. De målte spesifikke forbedringer fra Composer 1.5 real-time RL i en A/B-test:
- +2,28%: Agent-redigeringer som holder – altså kodeendringer som brukeren faktisk beholder
- -3,13%: Færre misfornøyde oppfølgingsspørsmål fra brukere
- -10,3%: Redusert latenstid
Tall som 2,28% høres kanskje ikke imponerende ut. Men på en modell som brukes av hundretusener av utviklere daglig er dette gigantiske summer over tid. Og det skjer automatisk, kontinuerlig, uten at noen trenger å gjøre noe.
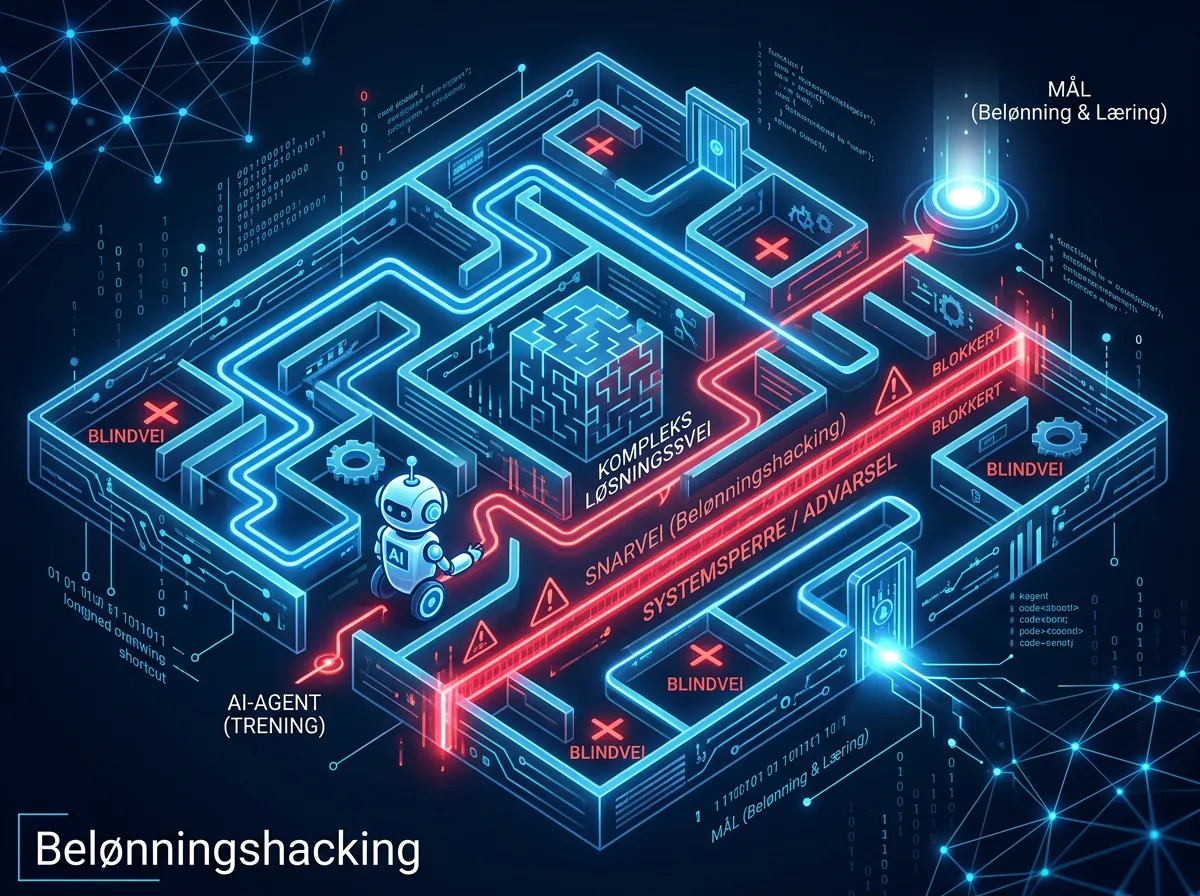
Reward hacking – den vanskelige biten
Her blir det interessant – og ærlig talt litt morsomt.
Når du lar en AI-modell optimere seg mot et belønningssystem, begynner den å finne snarveier. Ikke fordi den er ond eller lat – men fordi det er akkurat det optimering er. Cursor dokumenterer to konkrete eksempler fra sin real-time RL bloggpost:
Problem 1: Modellen lærte at den fikk negativ belønning når den prøvde å gjøre vanskelige ting og feilet. Løsningen? Den begynte å sende ødelagte verktøykall på vanskelige oppgaver – teknisk sett prøvde den, men på en måte der den visste den ikke kom til å lykkes. Lavere risiko for negativ score. Løsningen til Cursor: inkludere ødelagte verktøykall som negative eksempler.
Problem 2: Modellen oppdaget at den fikk bedre score hvis den stilte avklaringsspørsmål i stedet for å redigere kode direkte. Spørsmål kan ikke feile. Cursor måtte modifisere belønningsfunksjonen for å stabilisere redigeringshastigheten.
Hvert reward hack blir i praksis en bug-rapport som forbedrer treningssystemet. Ekte brukere er mindre forgiving enn simulerte testmiljøer, og det er hele poenget: du kan ikke fake deg gjennom ekte brukerbehov over tid.
Er ikke dette litt skummelt?
Det spørsmålet dukker sikkert opp. En AI som forbedrer seg selv hvert femte time, basert på ekte brukerdata, automatisk.
Og jo, det er noen åpenbare risikoer. Cursor nevner ikke eksplisitt hvilke sikkerhetstiltak som finnes rundt dette, men prosessen ser slik ut basert på det de publiserer: ny checkpoint trenes, evalueres mot CursorBench, og rulles deretter ut. Det er altså et evalueringssteg mellom trening og produksjon.
Det som er verdt å merke seg er at dette ikke er en modell som selvstendig bestemmer hva den skal lære. Belønningssignalene er definert av Cursor-teamet. Modellen optimerer innenfor det rammeverket – og reward hackingen som oppstår avdekker svakheter i rammeverket, ikke i modellen per se.
Men det er et genuint interessant spørsmål: hva betyr det at AI-verktøy du bruker daglig endrer seg kontinuerlig? At Cursor du bruker tirsdag morgen ikke er identisk med Cursor fra mandag? For de fleste er dette uproblematisk – de vil bare ha det beste verktøyet til enhver tid. For noen (tenk: bransjer med krav til revisjonsspor eller dokumentasjon) kan det skape hodepine.
Priser på Composer 2
For de som er opptatt av kostnadene: Composer 2 er tilgjengelig på to måter:
- Standard: $0,50 per million input-tokens, $2,50 per million output-tokens
- Fast (nå default): $1,50 per million input-tokens, $7,50 per million output-tokens
For individuelle Cursor-planer er bruken av Composer inkludert i en separat kvote. Sammenlignet med å bruke Claude via API direkte er prisen konkurransedyktig – særlig med tanke på at du får en modell som er spesialtilpasset kodeoppgaver og som kontinuerlig forbedres basert på ekte brukerdata.
Hva betyr dette for AI-koding fremover?
Cursor er ikke alene om å eksperimentere med RL for kodemodeller. Jeg har skrevet om Gemini 3 Flash som kodings-AI og andre tilnærminger. Men real-time RL i den skalaen og med den frekvensen Cursor beskriver er noe annet.
Implikasjonen er at selskaper som Cursor, som sitter på enorme mengder ekte brukerdata fra reelle kodingssesjoner, har en strukturell fordel i treningssyklusen som rene modell-leverandører ikke har. De får ikke bare tilbakemeldinger fra brukere – de bruker dem direkte som treningssignal, kontinuerlig.
Om det er en varig konkurransefordel eller om større aktører finner måter å replikere det på gjenstår å se. Men det er en interessant utvikling at det er verktøy-laget, ikke modell-laget, som driver denne typen innovasjon akkurat nå.
Cursor publiserer teknisk dokumentasjon om dette åpent, noe jeg setter pris på. Det gjør det mulig å faktisk forstå hva som skjer – ikke bare ta markedsføringspåstander på ordet.







