

Innhold Vis
Rekursiv selvforbedring – ideen om at AI kan forbedre seg selv uten menneskelig hjelp – har vært et tankeeksperiment i tiår. I 2025 og 2026 er det ikke lenger bare teori. Tre uavhengige forskergrupper har publisert systemer som faktisk gjør det, og resultatene er sjokkerende raske.
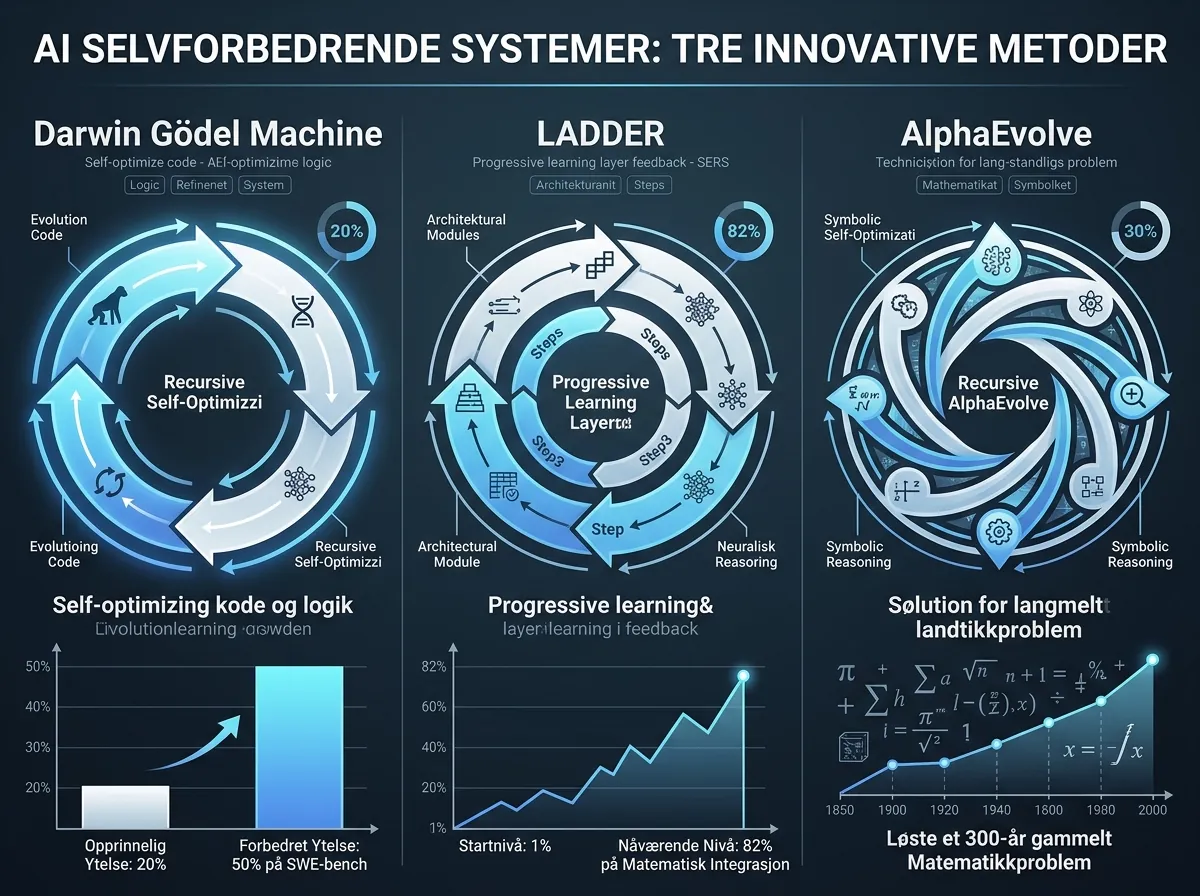
Darwin Gödel Machine fra Sakana AI forbedret sin egen kodingsytelse fra 20% til 50% på SWE-bench – autonomt, ved å omskrive sin egen kildekode. LADDER, et rammeverk fra to forskere, tok en Llama 3B-modell fra 1% til 82% nøyaktighet på matematikkoppgaver uten nye treningsdata. Google DeepMinds AlphaEvolve løste et 300 år gammelt matteproblem og fant en mer effektiv algoritme enn Strassen fra 1969.
Dette er ikke ett gjennombrudd. Det er tre parallelle bevis på at rekursiv selvforbedring er mulig. Her er hva som faktisk skjer.
Hva er rekursiv selvforbedring?
Rekursiv selvforbedring betyr at et AI-system forbedrer seg selv – og at den forbedrede versjonen forbedrer seg videre, og så videre. I teorien er dette oppskriften på en intelligenseksplosjon. I praksis har det vært ekstremt vanskelig å få til.
Det klassiske problemet er at du trenger en pålitelig måte å verifisere at en endring faktisk er en forbedring. For generelle evner er dette nesten umulig. Men for veldefinerte oppgaver – som koding eller matematikk – finnes det klare suksesskriterier. Det er der gjennombruddet skjer.
Gödel Machine, et konsept foreslått av forsker Jürgen Schmidhuber for to tiår siden, krevde at AI skulle levere et matematisk bevis på at enhver selvmodifikasjon var en forbedring. Det er i praksis umulig. Den nye generasjonen løser dette ved å erstatte matematiske bevis med empirisk testing – prøv det, mål resultatet, behold forbedringen.
Darwin Gödel Machine – AI som omskriver sin egen kode
Darwin Gödel Machine (DGM), publisert av Sakana AI i samarbeid med University of British Columbia og Vector Institute, er trolig det mest bemerkelsesverdige systemet. Det kombinerer darwinsk evolusjon med rekursiv selvmodifikasjon.
Slik fungerer det: Systemet leser sin egen Python-kodebase, foreslår endringer, tester dem på kodingsbenchmarks, og beholder de som fungerer. Agenter som er «litt dårlige» kaster det ikke – de oppbevares i et arkiv som «stepping stones», stier som kan vise seg nyttige senere. Det er direkte inspirert av evolusjons-tankegangen.
Resultatene på SWE-bench, den viktigste benchmarken for kodingsagenter, er imponerende: fra 20% til 50%. På Polyglot (flerspråklig koding) gikk systemet fra 14,2% til 30,7%. Det som er ekstra interessant: forbedringene overføres til andre modeller og programmeringsspråk – systemet lærer noe som er genuint generelt, ikke bare overfitting til én benchmark.
Sakana AI kjører alle selvmodifikasjoner i sandkassede miljøer med begrenset internettilgang og menneskelig tilsyn. Ingen løpsk AI her – men arkitekturen demonstrerer prinsippet.
LADDER – fra 1% til 82% uten nye treningsdata
LADDER (Learning through Autonomous Difficulty-Driven Example Recursion) er et rammeverk publisert på arxiv i mars 2025 av Toby Simonds og Akira Yoshiyama. Konseptet er elegant enkelt.
I stedet for å trene på nye data lager systemet enklere varianter av et problem det ikke klarer å løse, løser de enklere variantene, og bruker det som treningssignal for å gradvis bygge seg opp til det originale problemet. Ingen kuraterte datasett, ingen menneskelig tilbakemelding – modellen bruker sine egne evner til å bootstrappe seg videre.
Resultatene på matematisk integrasjon er spektakulære. Llama 3.2 3B gikk fra 1% til 82% nøyaktighet på integrering på bachelornivå. En 7B-modell oppnådde 73% på MIT Integration Bee 2025 – mot GPT-4os 42% og typisk menneskelig ytelse på 15-30%.
Test-Time Reinforcement Learning (TTRL), en utvidelse av rammeverket, genererer problemvarianter under inferens og bruker forsterkningslæring i sanntid. Det presset 7B-modellen til 85% – et lite steg fra dette til et system som kontinuerlig forbedrer seg mens det brukes.
AlphaEvolve – Google DeepMind løser 300-årig matteproblem
Google DeepMinds AlphaEvolve tar en litt annen tilnærming. Det er et evolusjonsbasert kodingsagentsystem som bruker Gemini til å mutere og kombinere algoritmer, evaluerer kandidatene, og itererer videre på de beste.
Systemet har allerede levert konkrete resultater utenfor lab-konteksten. Det oppdaget en algoritme for å multiplisere 4×4 kompleksverdi-matriser med bare 48 skalarmultiplikasjoner – bedre enn Strassens algoritme fra 1969 som har stått ubeseiret i over 50 år. Det etablerte nye nedre grenser i det 300 år gamle «kissing number»-problemet i elleve dimensjoner.
Mer praktisk: AlphaEvolve fant en heuristikk for Googles interne Borg-clusterstyringssystem som kontinuerlig gjenoppretter 0,7% av Googles globale datakraft. Den forbedret en kjernematrisemultiplikasjon i Geminis arkitektur med 23% og reduserte total treningstid med 1%.
Det er ikke bare akademisk. Det er AI som konkret sparer Google hundrevis av millioner kroner i løpende driftskostnader.
Er dette starten på singulariteten?
Det korte svaret er: Trolig ikke ennå – men retningen er klar.
Det finnes en viktig distinksjon mellom det som skjer nå og det som singularitets-teorien forutsier. Forbedringene skjer innenfor veldefinerte domener med klare suksesskriterier – matematikk, koding, algoritmisk optimalisering. Generell intelligens, evnen til å overføre læring til vilkårlige nye domener uten spesifikk opplæring, er fortsatt et åpent problem. Som jeg tidligere har skrevet om hva AGI faktisk er og når vi kan forvente det, er det enorm forskjell mellom å mestre ett domene og å mestre generell resonnering.
ICML 2026 arrangerer en dedikert workshop om rekursiv selvforbedring i AI, og workshopsummarien er ærlig på problemene: «Løkker som omskriver prompts, vekter, eller hypoteser opererer allerede inne i foundation-model-pipelines, men atferden deres er dårlig karakterisert.» Evalueringsverktøy og styring henger etter det algoritmiske fremskrittet.
Det er det som er litt urovekkende her. Ikke at systemene eksisterer – men at de allerede kjører i produksjon mens forståelsen av dem fortsatt er mangelfull.
Hva betyr dette i praksis?
For de fleste av oss er den praktiske konsekvensen foreløpig at AI-verktøyene vi allerede bruker blir bedre, raskere, og uten at vi nødvendigvis merker at de gjennomgår selvforbedring under panseret.
AlphaEvolve forbedrer allerede Gemini-modellene. DGM-prinsippene vil trolig dukke opp i neste generasjon kodingsagenter. LADDER-metoden peker mot modeller som kontinuerlig forbedrer seg mens du bruker dem – uten å laste ned nye versjoner.
Det er ikke én stor magisk singularitets-hendelse. Det er gradvis, domenespesifikk selvforbedring som akkumuleres. Og det akkumuleres raskt.
For en som har fulgt AI-feltets utvikling siden Stable Diffusion 1 – der hoppene virket store den gangen – er hastigheten på progresjon nå på en helt annen skala. Tre uavhengige grupper som demonstrerer rekursiv selvforbedring i løpet av ett år er ikke et signal man kan ignorere.
Hva skjer videre?
Alle tre systemene har én fellesnevner: de bruker eksisterende AI-evner til å forbedre AI-evner. Det er ikke mystisk. Det er ingeniørkunst. Men det er ingeniørkunst som akselererer seg selv.
Det neste steget er trolig systemer som rekursivt forbedrer seg på bredere og bredere domener. LADDER fungerte på matematisk integrasjon – men det finnes ingen prinsippiell grunn til at tilnærmingen ikke kan skalere til andre domener med klare suksesskriterier. DGM-arkitekturen kan tilpasses til andre oppgavetyper enn koding.
Hva skjer når domenet er «bli bedre til å forbedre AI generelt»? Det er spørsmålet ingen ennå har et godt svar på.
Jeg tenker det er verdt å følge disse tre paperne tett – ikke fordi singulariteten er rett rundt hjørnet, men fordi mønsteret de etablerer er noe fundamentalt nytt. AI som forbedrer AI er ikke lenger et framtidsscenario. Det er en arkitektur-klasse som eksisterer, fungerer, og allerede kjøres i produksjon hos minst én av verdens største teknologiselskaper.

Hva tenker du? Er dette bekymringsfullt, spennende, eller begge deler? Skriv gjerne en kommentar.







