
Innhold Vis
GPT-Rosalind er OpenAIs første domenespesifikke modell for biologi og medisinsk forskning, lansert 16. april 2026. Modellen er trent på 50 av de vanligste biologiske arbeidsflytene og har tilgang til store offentlige biologiske databaser. Tilgangen er foreløpig stengt for allmennheten – kun godkjente Enterprise-kunder i USA får tilgang gjennom et Trusted Access-program.
Navnet er ikke tilfeldig. Rosalind Franklin var krystallografen som tok røntgenbildet som avslørte DNAs dobbelthelix-struktur – og som historisk fikk for lite æren for det. Et fint nikk fra OpenAI, om enn litt sent ute. Men modellen selv er det verdt å se nærmere på.
Dette er OpenAIs svar på Google DeepMinds AlphaFold og andre vitenskapsspesialiserte AI-modeller. Spørsmålet er om det holder mål – og hvem som faktisk får bruke det.
Hva er GPT-Rosalind?
GPT-Rosalind er en frontier reasoning-modell finjustert for life sciences. Den er ikke en ny grunnmodell fra bunnen av, men en spesialisert versjon av OpenAIs eksisterende arkitektur – trent på biologiske arbeidsflyter, genomikk, kjemi og proteinengineering.
Det som skiller den fra vanlige allrounder-modeller som GPT-5-serien er dybden i treningsdataene. OpenAI har fokusert spesielt på 50 av de vanligste biologiske laboratoriearbeidsflytene og koblet modellen til mer enn 50 vitenskapelige databaser. Det betyr at den ikke bare snakker om biologi – den kan faktisk jobbe med biologiske data direkte.
Bruksområdene er konkrete: syntetisere vitenskapelig evidens, generere biologiske hypoteser og planlegge eksperimenter. Oppgaver som tradisjonelt krever år med ekspertise og enormt mye tid.
Hva sier benchmarkene?
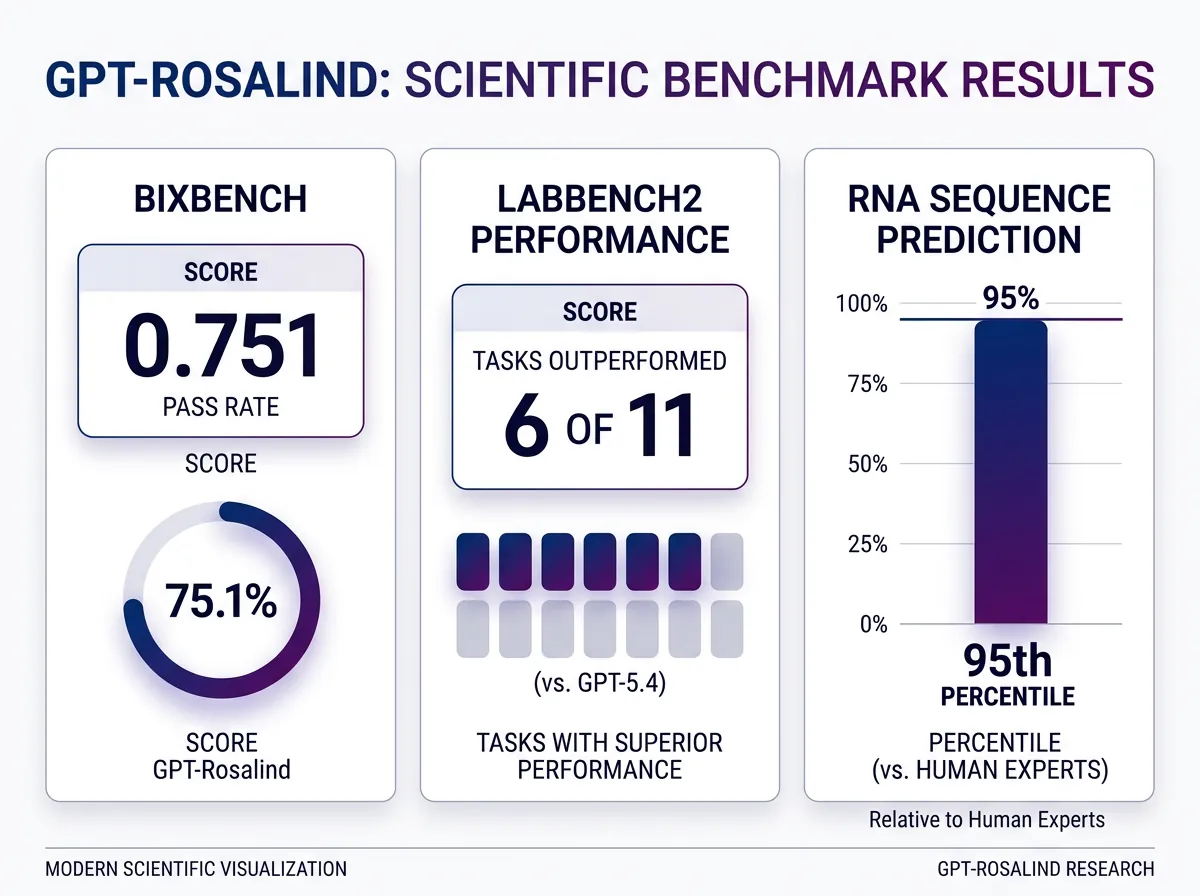
På BixBench – en benchmark for bioinformatikk og dataanalyse i den virkelige verden – oppnådde GPT-Rosalind en pass rate på 0,751. Det er det høyeste publiserte resultatet for denne benchmarken.
På LABBench2 overgikk modellen GPT-5.4 på seks av elleve oppgaver. Den største forbedringen kom i CloningQA – en oppgave der modellen må designe reagenser for molekylære kloningsprotokoller ende-til-ende. Det er presist arbeid som krever solid domeneforståelse.
Mest imponerende er kanskje dette: når modellen ble testet direkte i Codex-miljøet med upubliserte RNA-sekvenser, rangerte de beste innsendingene over 95. persentil blant menneskelige eksperter på prediksjonsoppgaver. For sekvensgenering nådde den 84. persentil.
Benchmarks er benchmarks – du vet hva jeg mener. Men 95. persentil blant fageksperter på RNA-prediksjon er ikke ingenting. Det er faktisk ganske mye.
Hvem er GPT-Rosalind for?
Modellen er ikke for deg og meg. Ikke ennå, i hvert fall. OpenAI lanserer den som en lukket research preview for godkjente Enterprise-kunder i USA gjennom et såkalt Trusted Access-program.
For å få tilgang må organisasjonen jobbe med å forbedre folkehelsen, drive legitim bioforskning og ha sterke sikkerhetskontroller og datastyring på plass. Det er en høy terskel – og bevisst slik.
Blant de første partnerne finner vi noen store navn: Amgen, Moderna, Allen Institute og Thermo Fisher Scientific. Det er ikke tilfeldige navn. Amgen og Moderna er tungt inne i legemiddelutvikling, Allen Institute er kjent for hjerneatlas og cellebiologi, og Thermo Fisher leverer utstyr og reagenser til laboratorier verden over.
Tilgangen skjer via ChatGPT, Codex og OpenAIs API – men altså bare for de godkjente. Det er en strategi vi ser stadig mer av: bruk i kontrollerte omgivelser før eventuell åpning for alle.
Konkurransen om vitenskapelig AI
GPT-Rosalind er ikke det første forsøket på å bruke AI i bioforskning. Google DeepMinds AlphaFold har vært en revolusjon for proteinfolding. Isomorphic Labs – DeepMinds datterselskap – har allerede brukt AI i legemiddelutvikling med lovende resultater.
Det OpenAI gjør her er å pakke en kraftig generell reasoning-modell med domeneekspertise og databasetilgang. Det er en annen tilnærming enn AlphaFolds spesialbygde arkitektur for proteinprediksjon – og det er ikke åpenbart hvilken strategi som vinner i det lange løp.
Det interessante er bredden. AlphaFold er spesialisert for ett problem. GPT-Rosalind er designet for hele arbeidsflyter – fra hypotese til eksperimentdesign. Det er mer ambisiøst, og potensielt mer nyttig for en laboratorium-daglidag.

Hva betyr dette for legemiddeloppdagelse?
Legemiddeloppdagelse er tidkrevende og kostbart. Et nytt legemiddel tar gjennomsnittlig 10-15 år fra laboratorium til apotek, og koster milliarder av dollar å utvikle. AI kan ikke magisk fikse alt det – men det kan akselerere enkelttrinn dramatisk.
Hvis GPT-Rosalind kan komprimere tiden det tar å designe og evaluere molekylære kandidater, planlegge eksperimenter og tolke resultater – da snakker vi om reell verdi. Ikke AI-hype, men konkret tidsbesparelse for folk som ellers ville brukt måneder på det samme.
Det er også verdt å merke seg konteksten. OpenAI har nylig lansert Codex for softvare-utvikling, og GPT-Rosalind for biologi. Det ser ut som en bevisst strategi om å gå dypere inn i fagspesifikke markeder – der selskaper er villige til å betale premium for spesialisert kompetanse.
Om det faktisk fungerer i klinisk praksis gjenstår å se. Amgen og Moderna vil nok gi oss svar på det i løpet av de neste månedene. Det er der den virkelige testen ligger – ikke i benchmarks, men i laboratoriet.
Hva tenker du – er dette starten på en ny bølge av fagspesialiserte AI-modeller, eller er det noe som bare de aller største selskapene vil ha bruk for?







