

Innhold Vis
David Silver – mannen bak AlphaGo – mener at vi er på feil spor med dagens AI. Han forlot Google DeepMind i slutten av 2025 og har nå hentet inn 1,1 milliard dollar (rundt 12 milliarder kroner) for å bevise det. Selskapet heter Ineffable Intelligence, og dette er den største seed-runden i Europas historie.
Tesen er like enkel som den er kontroversiell: store språkmodeller kan bare remikse og syntetisere menneskelig kunnskap – de kan ikke oppdage noe genuint nytt. Silver og hans mentor Richard Sutton, betraktet som selve «faderen til reinforcement learning», la frem dette synet i et paper i 2025. Det kalles «the era of experience» – en epoke der AI lærer gjennom egne erfaringer, ikke gjennom å gjengi internett.
Det er et standpunkt som treffer rett i hjertet av debatten om hva AI egentlig er – og hva det kan bli. Her er hva du trenger å vite.
Hva er feil med dagens AI, ifølge David Silver?
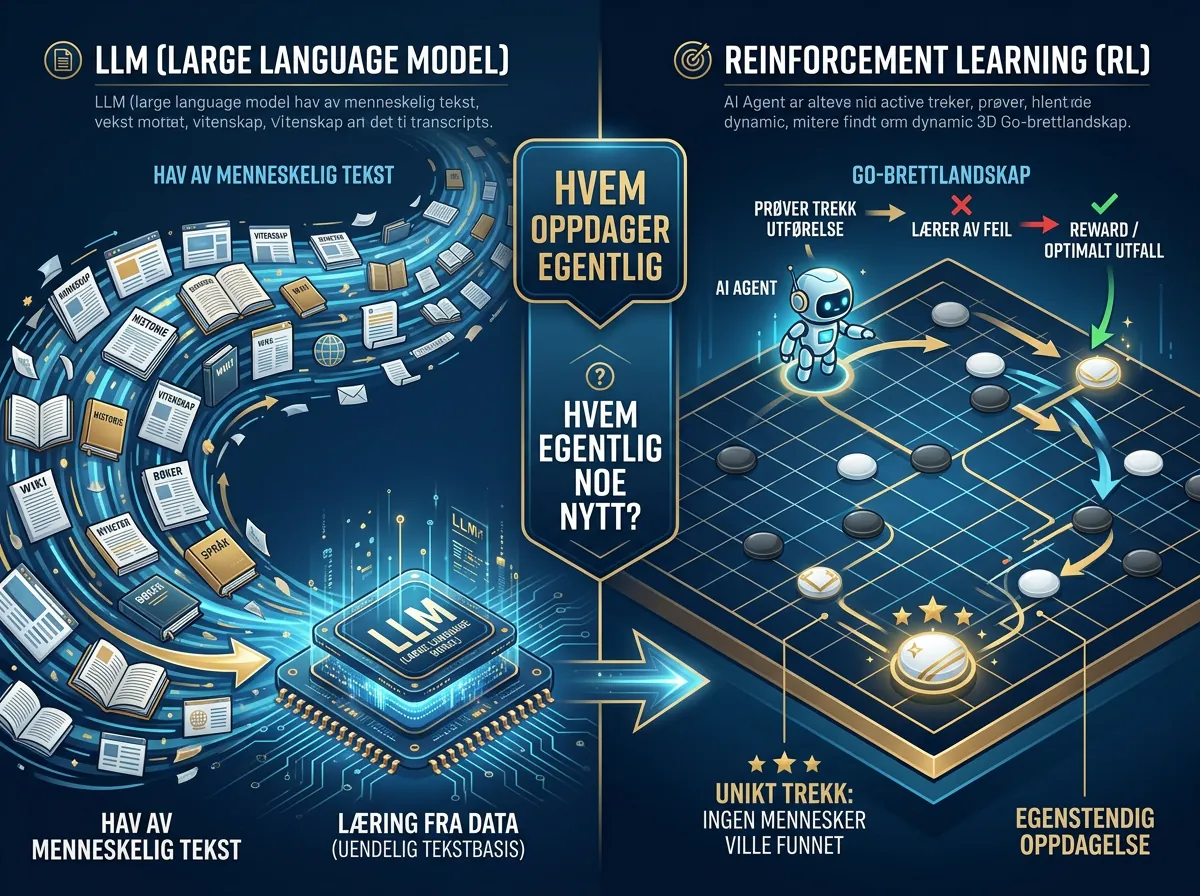
Kritikken Silver reiser mot store språkmodeller er ikke at de er dårlige. GPT-4o, Claude, Gemini – de er imponerende. Men de er fundamentalt begrenset av hva mennesker allerede vet.
Et LLM trenes på «the entirety of the human internet» – hele menneskelig nedskrevet kunnskap. Resultatet er en modell som kan kombinere, parafrasere og utlede fra det vi allerede har produsert. Det er nyttig. Men det er ikke det samme som å oppdage noe nytt.
Silver peker på et konkret eksempel fra sin egen karriere: AlphaGos berømte trekk 37 mot Lee Sedol i 2016. Det var et trekk ingen menneskelig Go-spiller noensinne hadde spilt. Det finnes ikke i noen spilldatabase. Programmet oppdaget det selv, gjennom millioner av spill mot seg selv – uten å ha studert ett eneste menneskelig spill. Lee Sedol forlot rommet i 15 minutter. Ekspertene trodde datamaskinen hadde gjort en feil. Den hadde ikke det.
Det er den typen intelligens Silver vil bygge videre. Noe som ikke bare remikser hva vi vet – men som kan komme frem til ting vi aldri hadde tenkt på.
Hva er «ineffable intelligence»?
Selskapsnavnet er et poeng i seg selv. «Ineffable» betyr noe som er umulig å sette ord på – som bokstavelig talt ikke kan beskrives med menneskelig språk.
Det er veldig bevisst. Silver argumenterer for at den typen intelligens han vil bygge, vil gå utover det vi kan forklare eller forstå med ord. En AI som lærer rent fra egne erfaringer, uten menneskelige eksempler som grunnlag, vil utvikle strategier og innsikt som er genuint ikke-menneskelig.
AlphaGo Zero er et tidlig glimt av dette. Den versjonen av AlphaGo ble ikke trent på menneskelige spill i det hele tatt – den lærte Go fra grunnen av, kun gjennom å spille mot seg selv. Den ble bedre enn alle tidligere versjoner som hadde studert millioner av menneskelige partier. Den oppnådde det Silver kaller «decisively superhuman performance» – og den gjorde det på en annen måte enn mennesker gjør det.
Hva er reinforcement learning, og hvorfor mener Silver det er veien videre?
Reinforcement learning (RL) er en læringsmetode der en AI-agent får belønning for ønskede handlinger og straff for uønskede. Den eksperimenterer, prøver og feiler, og lærer gradvis hva som fungerer i sitt miljø – uten at noen mennesker forteller den hva svaret er på forhånd.
Tenk på det som forskjellen mellom å lese en bok om sykling og faktisk å øve seg på å sykle. LLMs leser bøkene. Silver vil bygge noe som sykler – og så skriver sin egen bok om det.
DeepMind brukte denne metoden til å knuse profesjonelle Go-spillere, vinne på Atari-spill, og løse proteinfoldingsproblemet med AlphaFold. Silver har tilbrakt over ti år med å pushe grensene for hva RL kan gjøre. Nå vil han ta det et steg videre – bort fra spill med klare regler og mot åpne miljøer der «hva er målet?» ikke har et enkelt svar.
Det er her det blir vanskelig. Reinforcement learning er ekstremt kraftig i strukturerte miljøer med klare belønningssignaler. Sjakk: du vinner eller taper. Go: du vinner eller taper. Men generell intelligens? Hva er belønningssignalet for «å forstå verden bedre»? Det er det ingen har løst ennå – og det er det Silver nå satser 1,1 milliard dollar på å finne ut av.
Hvem er investorene, og hva sier de om sjansen for suksess?
Finansieringsrunden som ble annonsert 27. april 2026, er historisk. Sequoia Capital og Lightspeed ledet runden. Nvidia bidro med over 250 millioner dollar. Google deltok. DST Global og Index var også med. Og – interessant nok – det britiske statens «Sovereign AI Fund» var inne.
Selskapet var verdsatt til 5,1 milliarder dollar ved lukking. For et selskap uten produkt, uten inntekter og uten offentlig veikart. Det er et enormt veddemål på én persons track record og én idé.
Sonya Huang fra Sequoia, som ledet investeringen, bruker begrepet «superlearner» om hva Silver bygger – et system som oppdager all kunnskap gjennom egne erfaringer, fra grunnleggende motoriske ferdigheter til intellektuelle gjennombrudd. Ambisjonsnivået er å «oppdage på nytt og deretter overgå de største oppfinnelsene i menneskehetens historie: språk, vitenskap, matematikk og teknologi.»
Ja, det er akkurat så store ord. Om det holder, gjenstår å se.
Er Silver alene om denne tankegangen?
Ikke helt. Richard Sutton – som regnes som en av de absolutte pionerene innen reinforcement learning og medforfatter på det banebrytende papiret «Reinforcement Learning: An Introduction» – deler Silvers grunnleggende syn. De to publiserte et felles paper i 2025 som la det teoretiske grunnlaget for «the era of experience».
Sutton har i årevis argumentert for at skaleringen av forhåndstrent data har fundamentale tak – og at veien til genuin intelligens går gjennom læring fra interaksjon, ikke fra lagret tekst. Det er et synspunkt som har vært kontroversielt i et felt som i stor grad har satset alt på å skalere LLMs.
Det er verdt å merke seg at dette ikke er en liten uenighet om detaljer. Det er en grunnleggende faglig uenighet om hva AI faktisk er og hva det kan bli. OpenAI, Anthropic og Google satser milliardene på forhåndstrening og kontekstuell læring. Silver satser på at de tar feil om den lange banen.
Hva betyr dette for deg som følger med på AI?
Det korte svaret er: foreløpig ingenting praktisk. Ineffable Intelligence er i tidlig fase, og det vil ta år før vi vet om Silver har rett.
Men det er fascinerende å følge med på, og her er grunnen: hvis Silver har rett, betyr det at de milliardene som pumpes inn i å skalere LLMs nå, bygger mot et tak. Ikke et tak vi treffer i morgen – men et fundamentalt tak på hva modeller som lærer av menneskelig data, kan oppnå.
Jeg har skrevet om DeepMinds AlphaProof og AlphaGeometry 2, som kombinerte reinforcement learning med symbolsk resonnering for å løse matematikkoppgaver på IMO-nivå. Det er et annet eksempel på at RL-baserte systemer kan oppnå noe som rent LLM-baserte systemer ikke klarer – virkelig verifisert, ikke-hallusinert resonnering. Det peker i samme retning som Silver.
Og rekursiv selvforbedring – AI som forbedrer AI – er et tredje felt som trekker på lignende ideer: systemer som ikke er begrenset av menneskelig kunnskap som treningsdata.
Uavhengig av om Ineffable Intelligence lykkes, er spørsmålet Silver stiller viktig: hva er den faktiske grensen for hva AI kan oppdage, versus hva det kan reprodusere? Det er et spørsmål uten enkelt svar, og det vil forme hva AI faktisk blir de neste tiårene.
Silvers ambisjon er formulert slik av selskapet selv: å skape et system som «gjenoppdager og deretter overgår de største oppfinnelsene i menneskehetens historie.» Det er enten det viktigste forskningsprosjektet som noensinne er satt i gang – eller det er et veldig dyrt eksperiment som viser at forhåndstrening tross alt ikke var så feil.
Jeg er genuint nysgjerrig på hvilket det blir. Og det er ikke ofte jeg sier det om et selskap uten et eneste produkt.







