

Innhold Vis
Qwen Image er Alibabas open source bildegenererings- og redigeringsmodell – og noen har begynt å bruke den til noe virkelig fascinerende: fotorealistiske scener fra alternative historier som aldri skjedde. Et Reddit-innlegg i r/StableDiffusion demonstrerte nylig hva som er mulig når man setter opp et Qwen Image-oppsett med ComfyUI og lar kreativiteten løpe fritt. Resultatet var bilder som ser ut som ekte historiske fotografier – men fra tidslinjene vi aldri fikk.
Det er en av de tingene som virkelig viser hva dagens bildegenerering er blitt til. Det handler ikke lenger om å lage fancy illustrasjoner. Det handler om å bygge visuell kontrafaktisk historiefortelling med et presisjonsnivå som tidligere krevde store filmbudsjetter og profesjonelle effektteam.
Her er en gjennomgang av Qwen Image-oppsettet, hva det kan gjøre, og hvorfor dette er et av de mest interessante kreative verktøyene i open source-landskapet akkurat nå.
Hva er Qwen Image – og hvorfor er det annerledes?
Qwen Image er en bildegenererings- og redigeringsmodell fra Alibabas Qwen-team, lansert i 2025. Den bygger på en MMDiT-arkitektur (Multimodal Diffusion Transformer) med 20 milliarder parametere og er åpen kildekode under Apache 2.0-lisens – noe som betyr full kommersiell frihet.
Det som skiller Qwen Image fra mange konkurrenter er at den er trent med en kombinasjon av visuell semantisk forståelse og presisjonsdiffusjon. Kort sagt: modellen forstår hva den ser, og kan redigere presist basert på tekstinstruksjoner – uten at du trenger å tegne inpainting-masker manuelt. Du skriver hva du vil ha, og modellen skjønner hva som skal endres og hva som skal beholdes.
Ifølge Qwens offisielle GitHub-repo støtter modellen alt fra tekst-til-bilde-generering til avansert bilderedigering i én og samme arkitektur. Og den kan generere bilder opptil 3584×3584 piksler direkte – uten eksterne upscalere.
Hva gjør Qwen Image i praksis?
Her er noen av de konkrete tingene modellen håndterer med imponerende presisjon:
- Objektmanipulering: Legg til eller fjern objekter fra scener uten å berøre resten av bildet
- Stiloverføring: Ta et fotografi og gjør det til pixel art, tegneserie, eller maleristil
- Historisk fotorealism: Generer bilder som ser ut som ekte fotografier fra en bestemt epoke
- Tekstintegrasjon: Legg til tekst, skilt, overskrifter – noe de fleste diffusjonsmodeller er forferdelige på
- Perspektiv og rotasjon: Roter objekter eller endre kameravinkel med bevarte detaljer
Alternativ-historietrikset utnytter nettopp kombinasjonen av historisk fotorealism og presis bilderedigering. Du kan starte med et faktisk historisk fotografi, gi modellen instruksjoner om hva som skal endres, og få tilbake et bilde som ser ut som om det alltid har vært slik.
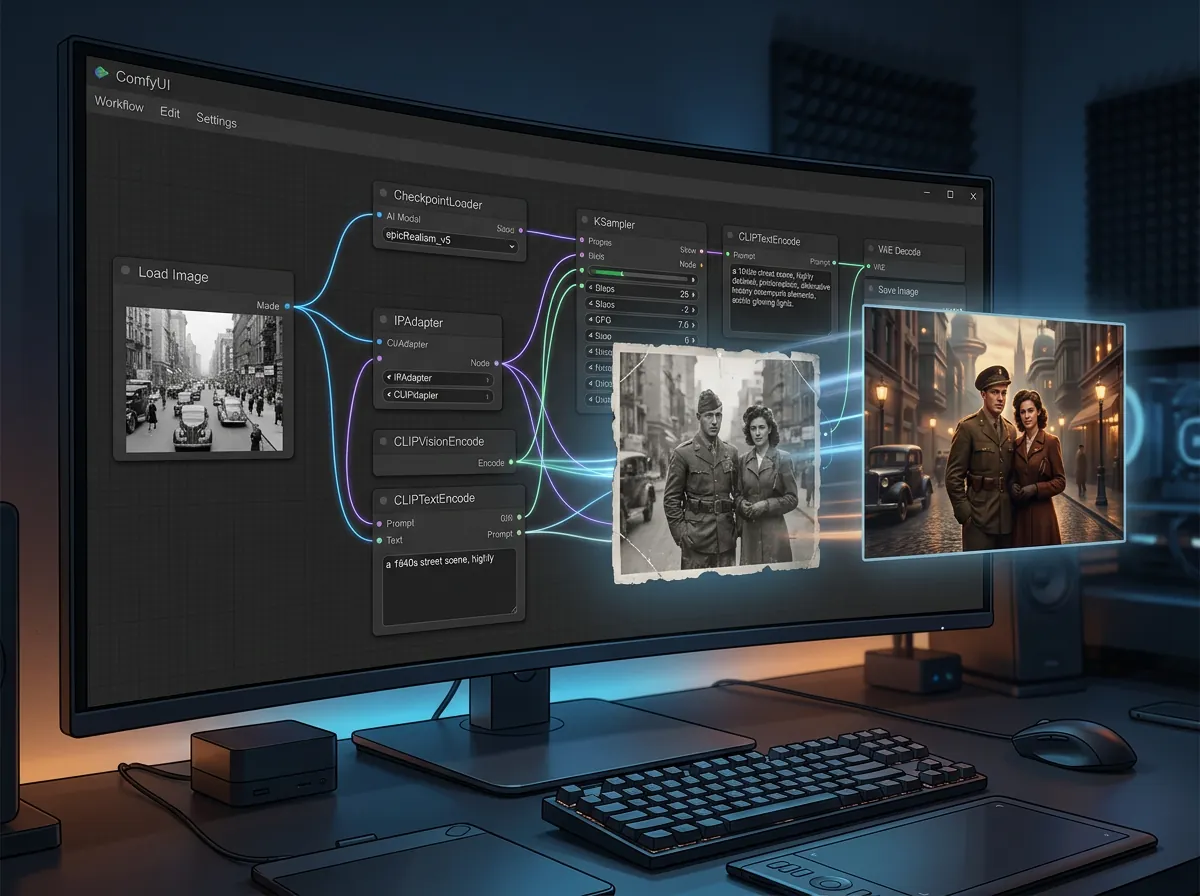
Hvilket oppsett trengs for å kjøre Qwen Image lokalt?
Oppsettet kjører via ComfyUI – det dominerende grensesnittet for lokale diffusjonsmodeller. Du trenger tre modellkomponenter:
- Diffusjonsmodell: qwen_image_fp8_e4m3fn.safetensors (20,4 GB)
- Tekstkoder: qwen_2.5_vl_7b_fp8_scaled.safetensors
- VAE: qwen_image_vae.safetensors
VRAM-kravet er rundt 24 GB for full fp8-presisjon på en RTX 4090. Men det finnes GGUF-kvantiserte varianter som kan kjøres med 8 GB VRAM – noe som gjør det tilgjengelig for langt flere. Generering tar mellom 35 og 90 sekunder per bilde avhengig av variant og om du bruker Lightning LoRA for akselerasjon.
Vil du ikke kjøre lokalt, finnes modellen også via Hugging Face og cloud-baserte inferenstjenester.
Hva er Qwen Image 2.0 – og er den bedre?
I februar 2026 lanserte Qwen-teamet Qwen Image 2.0 – en oppdatert versjon som forener generering og redigering i én enkelt 7B-arkitektur. Altså tre ganger mindre enn originalen, men med bedre ytelse.
Noen nøkkeltall for Qwen Image 2.0:
- 7 milliarder parametere (ned fra 20B)
- Innebygd 2048×2048 (2K) oppløsning
- Støtter prompts på opptil 1000 tokens
- GenEval-score: 0.91
- DPG-Bench: 88,32 (mot FLUX.1 sin 83,84)
- Rangert #1 i AI Arena for både tekst-til-bilde og bilderedigering
Den er med andre ord direkte konkurrent til Flux 2 – og benchmark-tallene tyder på at den faktisk slår det i mange kategorier.

Alternativ historie som kreativt eksperiment
Tilbake til det som startet dette innlegget. Reddit-posten som dukket opp i r/StableDiffusion demonstrerte nettopp denne kreative bruken: ta en historisk epoke, forestill deg at noe skjedde annerledes, og generer et bilde som ser ut som et ekte fotografi fra den alternative tidslinjen.
Det er noe genuint fascinerende med dette. Alternativ historiefortelling er et gammelt litterært grep – «hva hvis aksemaktene vant andre verdenskrig», «hva hvis Romerriket aldri falt», «hva hvis kolonialismen aldri skjedde». Men å lese om det er én ting. Å se et tilsynelatende autentisk fotografi av den verden er noe helt annet.
Qwen Image er spesielt egnet til dette fordi den kombinerer to ting som trengs: historisk kontekstuell forståelse (som en stor tekstkoder gir), og presisjonsredigering som gjør at detaljer som klær, arkitektur, og epoke-spesifikke objekter kan manipuleres naturlig. Det er ikke tilfeldig at det er akkurat Qwen-oppsettet som dukker opp i denne sammenheng – og ikke bare en vanlig Stable Diffusion-workflow.
Jeg har skrevet om Qwen Image Edit 2511 tidligere, men det er tydelig at fellesskapet rundt modellen stadig finner nye kreative bruksområder. Alternativ historievisualisering er bare det siste eksempelet.
Er Qwen Image det beste valget for dette?
Spørs hva du vil ha ut av det. For de som ønsker presis bilderedigering av eksisterende fotografier – altså å ta et historisk bilde og manipulere det troverdig – er Qwen Image et svært godt valg. Den semantiske forståelsen er god nok til at du kan beskrive hva du vil ha, og modellen gjetter sjelden feil.
For ren tekst-til-bilde-generering av imaginære historiske scener er Flux 2 fremdeles sterk konkurrent. Men Qwen Image 2.0 har benchmarks som peker opp, og er spesielt god på fotorealism og korrekt tekstrendering i bildene.
Og med 8 GB VRAM-støtte via GGUF-varianten er terskelen for å prøve det ganske lav. Hva er verste som kan skje? At du ender opp med å lage bilder fra en alternativ versjon av historien i et par timer. Verre ting har skjedd.







