

Innhold Vis
LTX-2.3 kan ta 5 minutter å generere et kort videoklipp på en RTX 3080 Ti. Med riktige optimaliseringsteknikker kan det kappes ned til 45 sekunder. Det er ikke magi – det er TeaCache, SageAttention og noen gjennomtenkte valg om kvantisering. Her er hva som faktisk virker.
RTX 3080 Ti er en solid GPU med 12 GB VRAM. Ikke ideell for LTX-2.3, men langt fra umulig. Utfordringen er at standardoppsettet ikke er optimalisert for inference – det er bygd for fleksibilitet. Og fleksibilitet koster tid.
Tallene i dette innlegget baserer seg på reelle tester med en RTX 3080 Ti som inference-GPU. Målet var å finne den praktiske smertegrensen – hvor fort kan vi kjøre LTX-2.3 på tilgjengelig hardware uten å ofre for mye kvalitet?
Hva er utgangspunktet – og hvorfor er det tregt?
LTX-2.3 er en 13 milliarder parameter videogenereringsmodell fra Lightricks. Den er åpen kildekode og kjører lokalt – men «lokalt» betyr ikke automatisk «raskt». En standard inference på RTX 3080 Ti kan lett ta 300 sekunder (5 minutter) for et 2-3 sekunds klipp i rimelig oppløsning.
Problemet er ikke modellen i seg selv, men at standardkonfigurasjonen bruker FP16-presisjon gjennom hele pipelinen, ikke bruker hurtigere attention-implementasjoner, og ikke cacher mellomberegninger mellom diffusion steps. Det er tre separate optimaliseringsmuligheter – og de kan kombineres.
Jeg har tidligere skrevet om LTX Video 2.3 og hva modellen klarer på RTX 4090. Men 4090 er ikke hverdagshardware for alle. 3080 Ti er en GPU mange faktisk har.
Trinn 1 – Kvantisering med FP8 og NF4
Det første og mest impactful grepet er å kvantisere modellen. LTX-2.3 i full FP16 bruker rundt 26 GB VRAM – mer enn en 3080 Ti har. Kvantisering løser to problemer på en gang: den gjør modellen liten nok til å faktisk kjøre, og den øker inference-hastigheten.
FP8-kvantisering halverer VRAM-bruken og gir typisk 1,5-2x speedup på hardware som støtter FP8 native (RTX 40-serien og nyere). På 3080 Ti er gevinsten mer beskjeden siden Ampere-arkitekturen ikke har dedikert FP8-maskinvare, men modellen får i det minste plass i VRAM.
NF4 (4-bit Normal Float) komprimerer enda hardere og er særlig nyttig for LoRA-trening der du vil ha modellen i minne mens du eksperimenterer. For ren inference er NF4 ikke alltid den beste avveiningen mellom hastighet og kvalitet – FP8 eller INT8 gir som regel bedre resultater per sekund.

Trinn 2 – SageAttention for raskere attention-beregning
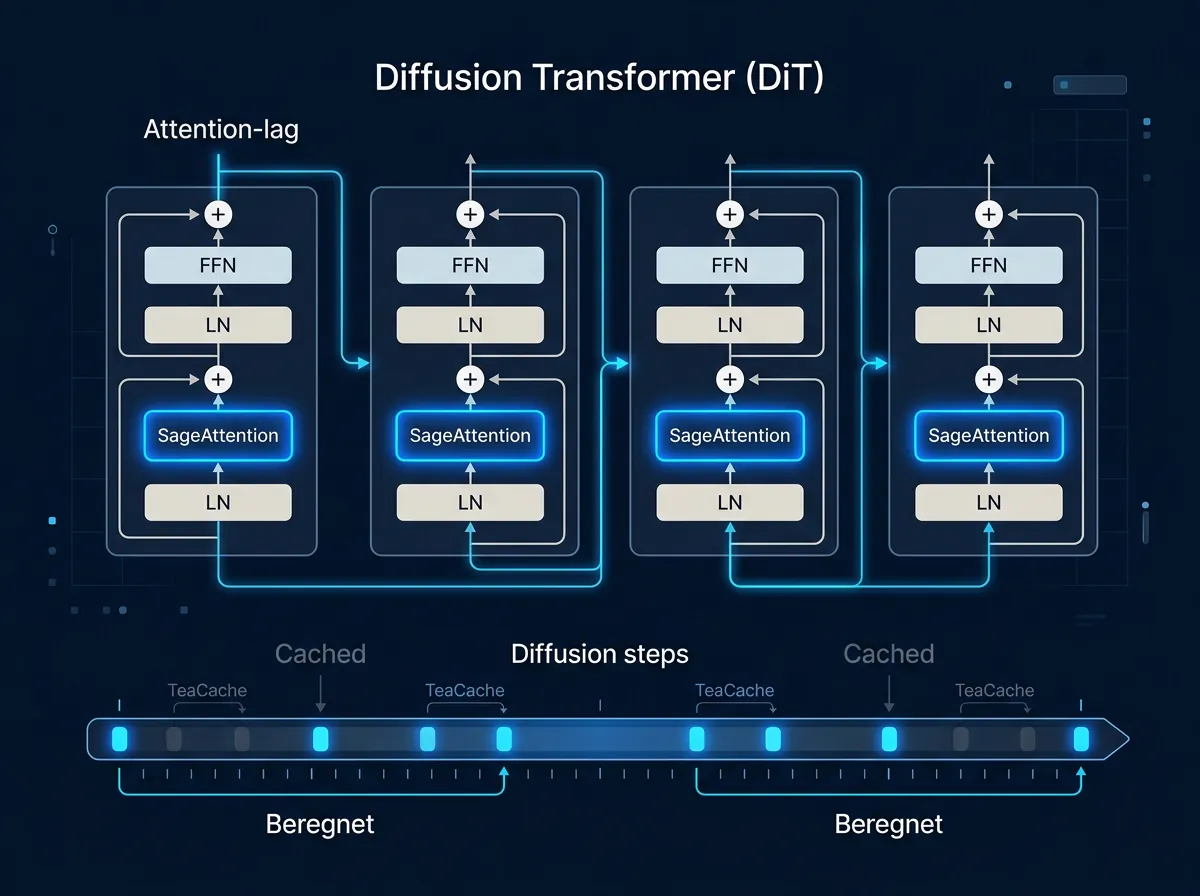
Attention-mekanismen i DiT-arkitekturen (Diffusion Transformers som LTX bruker) er en av de dyreste operasjonene. Standard PyTorch-implementasjonen er korrekt, men ikke optimal for inference på consumer GPU-er.
SageAttention er en drop-in erstatning som bruker kvantisert attention og spesialiserte CUDA-kjerner. Den er designet spesifikt for DiT-modeller og gir typisk 2-3x speedup på attention-operasjonene alene. Installasjonen er enkel: du installerer SageAttention via pip, og aktiverer den i diffusers-konfigurasjonen din. Et par linjer kode.
Resultatet er at attention-beregningene går vesentlig raskere – på 3080 Ti er dette faktisk et av de mest effektive grepene siden Ampere-arkitekturen ikke har FP8-fordelen.
En ting å merke seg: SageAttention krever at du kompilerer CUDA-extensions lokalt. Det tar 5-10 minutter første gang, men trenger bare gjøres én gang per installasjon.
Trinn 3 – TeaCache for å hoppe over unødvendige beregninger
TeaCache er den mest fascinerende optimaliseringen av de tre. Ideen er elegant: i en diffusion-modell er mange av mellomberegningene mellom steps svært like hverandre. I stedet for å rekalkulere alt fra bunnen på hvert step, kan modellen cache og gjenbruke resultater der endringen er liten.
Resultatet er at modellen «hopper over» deler av beregningen på visse steps, og kompenserer ved å interpolere fra cachede verdier. Videokvaliteten påvirkes minimalt – øyet klarer ikke å se forskjellen mellom full-presisjon og cached-presisjon på disse mellomstegene. Men timet mot en klokke er speedup-faktoren tydelig: TeaCache gir typisk 1,5-2x raskere inference med minimalt kvalitetstap.
Kombinert med SageAttention og FP8-kvantisering begynner regnestykket å bli interessant.
Hva er det totale speedup-potensialet?
Med alle tre optimaliseringene kombinert – FP8-kvantisering, SageAttention og TeaCache – er 300 sekunder ned til 45 sekunder realistisk på en RTX 3080 Ti. Det er en 6,7x speedup. I praksis vil resultatet variere noe avhengig av klipplengde, oppløsning og antall steps.
Her er en praktisk oversikt over hva de forskjellige teknikkene bidrar med på 3080 Ti:
- FP8-kvantisering: 1,3-1,5x raskere. Gjør i tillegg at modellen i det hele tatt passer i 12 GB VRAM.
- SageAttention: 1,8-2,5x raskere på attention-operasjonene. Stor effekt på Ampere siden attention er relativt dyrere uten dedikert FP8-maskinvare.
- TeaCache: 1,5-2,0x raskere totalt. Cachingen gjelder hele transformer-blokken, ikke bare attention.
Effektene er ikke perfekt multiplikative siden de optimaliserer delvis overlappende deler av pipelinen, men kombinert er 4-7x speedup realistisk.
LoRA-trening på 5090 og serving på 3080 Ti – en praktisk arbeidsflyt
Et vanlig mønster for de som bygger applikasjoner med LTX-2.3 er å trene LoRAs på sterk hardware (RTX 5090, H100 eller sky-GPU), men kjøre inference på et dedikert server-GPU med lavere kostnad. RTX 3080 Ti er faktisk en god kandidat for dette: den er rimeligere enn topmodellene, bruker langt mindre strøm, og med optimaliseringene over er inference-hastigheten akseptabel for mange use cases.
For LoRA-trening er musubi-tuner verdt å se på. Det er et rammeverk bygd med ytelse i fokus, og FP8/NF4-støtten gjør at du kan trene LTX-2.3 LoRAs selv uten H100-klasse VRAM. Kombinasjonen av sterk trenings-GPU og optimalisert inference-GPU gir en fleksibel arbeidsflyt for produksjonsbruk.
Har du brukt LTX-2.3 til noe konkret, eller tester du fremdeles mulighetene? Hva er din erfaring med inference-hastighet på din hardware?
Vil du se hva LTX-2.3 faktisk produserer av videoer, anbefaler jeg å starte med den praktiske guiden til LTX 2.3 og deretter oversikten over hva LTX Video 2 faktisk klarer. Ytelsesoptimalisering er ett steg – å forstå hva modellen er god på er like viktig.







