

Innhold Vis
Thinking Machines Lab har sluppet en research preview av TML-Interaction-Small – en 276 milliarder parameter MoE-modell som gjør noe de fleste AI-modeller ikke klarer: den hører og snakker på samme tid. Ikke tur-for-tur som ChatGPT og Gemini gjør det, men i 200 millisekund-segmenter som behandler lyd, video og tekst parallelt.
Mira Murati grunnla Thinking Machines Lab etter hun forlot OpenAI i slutten av 2024. Selskapet har vært relativt stille siden starten, men med denne modellen viser de at de tenker annerledes om hva en samtale-AI egentlig bør være. Ikke bare raskere – men fundamentalt annerledes i arkitektur.
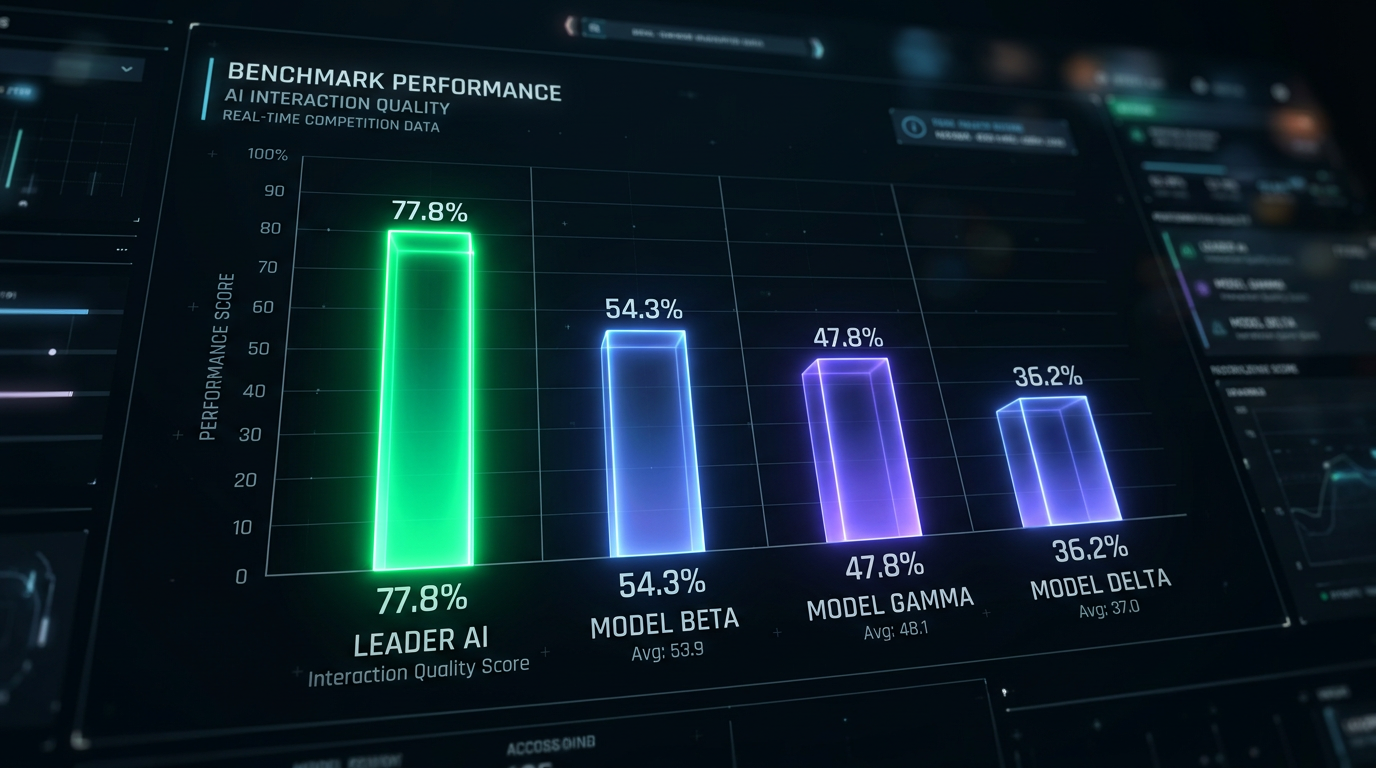
Tallene fra benchmarks er verdt å se på. På FD-bench v1.5, som måler interaksjonskvalitet, scorer TML-Interaction-Small 77,8 – mot 54,3 for Gemini og 47,8 for GPT-realtime-2.0. Det er ikke marginale forskjeller. Og på noen av de nye benchmarkene de har introdusert, scorer konkurrentene nærmest null.
Hva er TML-Interaction-Small?
TML-Interaction-Small er en 276 milliarder parameter Mixture-of-Experts-modell med 12 milliarder aktive parametere per inferens. Den er bygget fra grunnen for sanntidsinteraksjon – ikke tilpasset fra en eksisterende chat-modell.
Arkitekturen kalles «multi-stream, time-aligned micro-turn» – som i praksis betyr at modellen deler inn alt den behandler i 200 millisekund-segmenter. Hvert segment kan inneholde lyd, video og tekst samtidig, og modellen prosesserer disse i parallell, ikke sekvensielt. Resultatet er at den kan reagere på noe du sier midt i en setning, eller oppdage noe i videoen uten at du trenger å si noe.
Til sammenligning: tradisjonelle modeller som GPT-4o og Gemini Live bruker en slags turn-based logikk under overflaten. De venter på at du er ferdig med å snakke, stopper oppfatning mens de genererer svar, og bruker separate komponenter for stemmaktivitetsdeteksjon (VAD), talegjenkjenning (ASR) og talesyntese (TTS). TML-Interaction-Small har ingen av disse delene som separate systemer – alt er trenet inn fra starten.
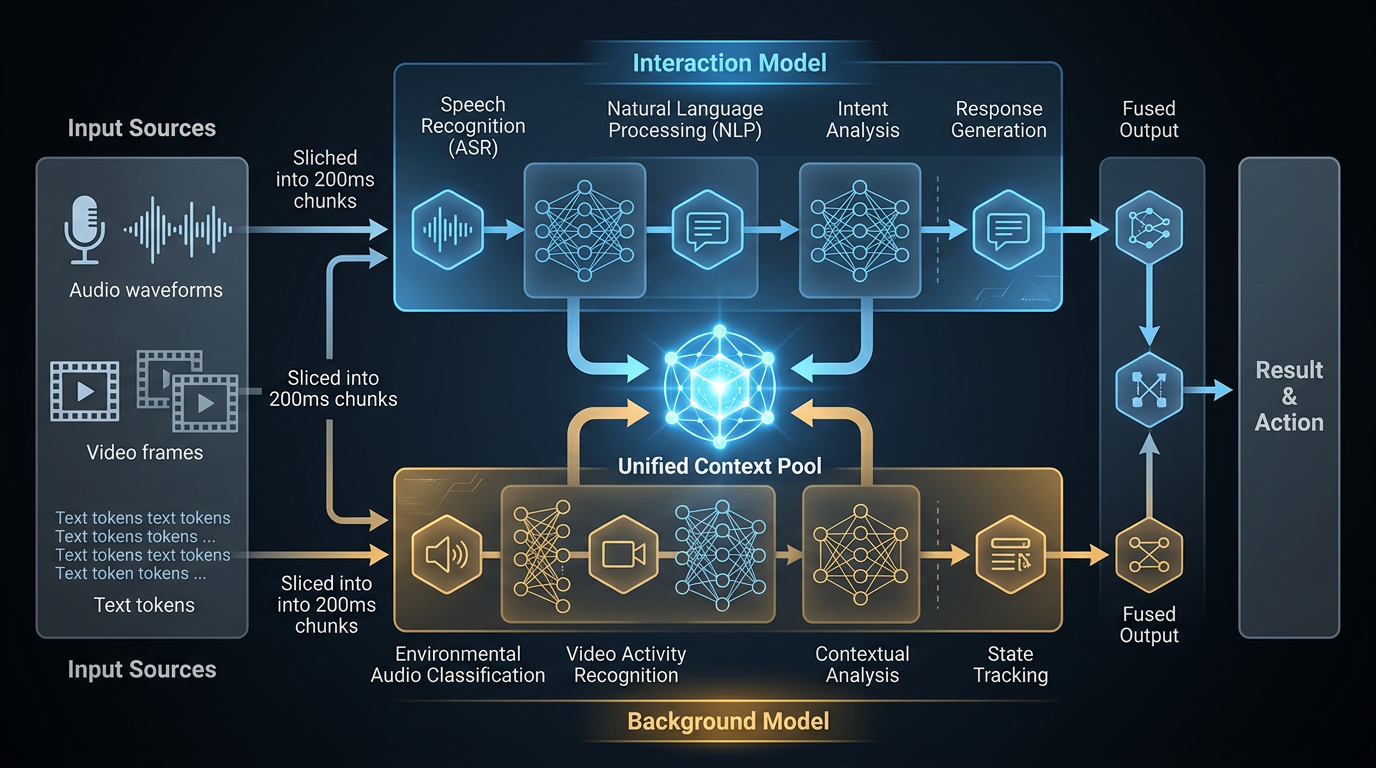
Hvordan fungerer to-komponent-systemet?
Modellen kjører to parallelle komponenter som deler full kontekst hele tiden. Den første er «Interaction Model» – alltid aktiv, behandler kontinuerlig strøm av lyd, video og tekst. Den andre er «Background Model» – kjører asynkront for dypere resonering, verktøybruk og nettsøk.
Thinking Machines Lab beskriver det slik: «Think of it like one person who keeps you engaged in conversation while a colleague in the background looks something up and passes notes forward in real time.» Det er en god analogi. Den ene parten holder samtalen i gang mens den andre jobber med oppgaven – og resultater fra bakgrunnsarbeidet flettes inn i samtalen uten pause eller avbrudd.
Praktisk betyr dette at modellen kan kjøre et nettsøk, hente et verktøy, eller resonnere over et komplekst problem – alt mens samtalen fortsetter. Ingen «et øyeblikk, jeg sjekker»-pauser. Det ligner mer på hvordan et menneske faktisk fungerer i en samtale enn det noen AI-assistent har klart å levere til nå.
Encoder-free early fusion – hva betyr det?
Dette er kanskje den mest teknisk interessante biten. De fleste multimodale AI-systemer bruker separate, forhåndstrente encodere for hvert modalitet. Whisper-modellen for lyd, en ViT-modell for bilder, en teksttokenizer for tekst – alle trente separat og deretter koblet sammen.
TML-Interaction-Small gjør det annerledes. Lyd behandles via dMel-representasjoner med et lett innebyggingslag direkte. Video behandles via 40×40 bildefliser gjennom en hMLP-komponent. Lydutdata genereres via en Flow-head dekoder. Og det viktige: alle disse komponentene er co-trenet fra grunnen med selve transformerarkitekturen.
Resultatet er at modellen ikke har «sømmer» mellom modalitetene. Den behandler lyd og video ikke som noe som konverteres til tekst-tokens og deretter prosesseres – men som native input på lik linje med tekst. Det er dette de mener med «native multimodal»: ikke boltet på i ettertid, men innebygd i arkitekturen fra dag én. Se også artikkelen om VL-JEPA – Metas AI som tenker uten ord for et annet eksempel på fremvoksende native multimodal arkitektur.
Hva scorer TML-Interaction-Small på?
Benchmarks er alltid noe man bør ta med en klype salt – de måler det de er designet for å måle, og selskaper kan påvirke hva de velger å vise frem. Det sagt, tallene her er ikke uviktige.
På FD-bench v1.5 (interaksjonskvalitet): 77,8 mot 54,3 for Gemini og 47,8 for GPT-realtime-2.0. På Audio MultiChallenge APR (høyeste blant «instant»-modeller): 43,4% mot GPT-realtime-2.0 sine 37,6%. Responstid på FD-bench v1: 0,40 sekunder mot Geminis 0,57 sekunder.
Mer interessant er benchmarkene som tester det modellen faktisk er designet for. TimeSpeak – å snakke på et bestemt tidspunkt i en samtale – scorer TML-Interaction-Small 64,7 mot GPT-realtime-2.0 sine 4,3. CueSpeak – å reagere på visuelle signaler – 81,7 mot 2,9. RepCount-A – telle repetisjoner i video (som push-ups) – 35,4 mot 1,3. Charades – videoforståelse – 32,4 mIoU mot 0.
Null. Konkurrentene scorer null på flere av disse benchmarkene. Det forteller noe om hvor annerledes arkitekturen er, ikke bare bedre på de samme tingene.
Hva kan du bruke den til?
Thinking Machines Lab nevner en rekke konkrete brukstilfeller. Direkteoversetting der du snakker ett språk og mottar svar på et annet – uten opphold mellom de to talene. Visuell reaktivitet uten verbal instruksjon, som å telle push-ups i en treningssession eller oppdage kodebugger i et skjermopptak uten at du trenger å si «hei, se her». Tidsbevisste initiativ der modellen kan starte å snakke på et bestemt øyeblikk basert på noe den ser eller hører.
Det minner litt om det Meta Muse Spark og andre neste generasjons modeller prøver å bygge: AI som samhandler på menneskenes premisser, ikke AI som tvinger mennesker til å tilpasse seg systemets begrensninger.
En treningscoach som ser og hører deg i sanntid. En oversetter som ikke trenger pauser. En kodingsassistent som oppdager feil i terminalen din uten at du trenger å kopiere inn kode manuelt. Det er den typen brukstilfeller som begynner å bli realistiske med denne arkitekturen. Se også hva Ovis2.6-80B – multimodal AI med MoE-arkitektur gjør på den multimodale fronten for et sammenligningspunkt.
Når er den tilgjengelig?
Per mai 2026 er dette en begrenset research preview. Ikke en produksjons-API du kan ta i bruk i morgen. Interesserte kan søke om tilgang via thinkingmachines.ai, og bredere tilgang er planlagt til senere i 2026.
Thinking Machines Lab erkjenner noen kjente begrensninger. Lange sesjoner akkumulerer kontekst raskt siden modellen holder lyd og video aktivt i minne. Det krever pålitelig nettverksforbindelse for 200ms-streaming å fungere som forutsatt. Og modellstørrelsen på 276B med 12B aktive parametere er ikke akkurat noe du kjører lokalt på en bærbar.
På sikkerhetssiden rapporterer de 99,0% avvisningsrate på Harmbench – det er høyt, og de har aktiv tilbakemeldingsinnsamling fra preview-brukere. For en mer nøytral forklaring av begreper som MoE og multimodal, er AI-ordlisten for 2026 et godt utgangspunkt.
Det som er klart allerede nå: arkitekturen er fundamentalt annerledes enn det vi har sett fra OpenAI og Google. Og benchmark-gapet på de interaksjonsrelaterte testene er ikke marginalt – det er en annen divisjon. Om Thinking Machines Lab klarer å skalere dette til en fullverdig produksjonsmodell, kan det bli interessant å følge gjennom resten av 2026.







