

Innhold Vis
NVIDIA har sluppet Nemotron-Labs-Diffusion, en ny språkmodellfamilie som kombinerer tre fundamentalt forskjellige dekodingsmodus i én og samme modell-checkpoint. Resultatet er 6 ganger høyere gjennomstrøm enn sammenlignbare modeller fra Qwen – uten at du trenger å bytte mellom separate modeller avhengig av brukstilfelle.
Teknisk sett er dette interessant fordi problemet med autoregressive språkmodeller alltid har vært det samme: én token ut per forward pass. Det er enkelt, forutsigbart, men ikke spesielt raskt når du trenger å generere mye tekst. Diffusjonsbaserte språkmodeller har lenge lovet et svar på dette, men har slitt med å matche AR-kvaliteten. Nemotron-Labs-Diffusion forsøker å løse hele problemet på én gang.
Modellen finnes i tre størrelser – 3B, 8B og 14B parametere – og kommer i base-, instruct- og vision-language-varianter. Det er 8B-varianten som er mest sammenlignbar med Qwen3-8B, og det er mot den de fleste tallene er målt.
Hva er de tre dekodingsmodusene i Nemotron-Labs-Diffusion?
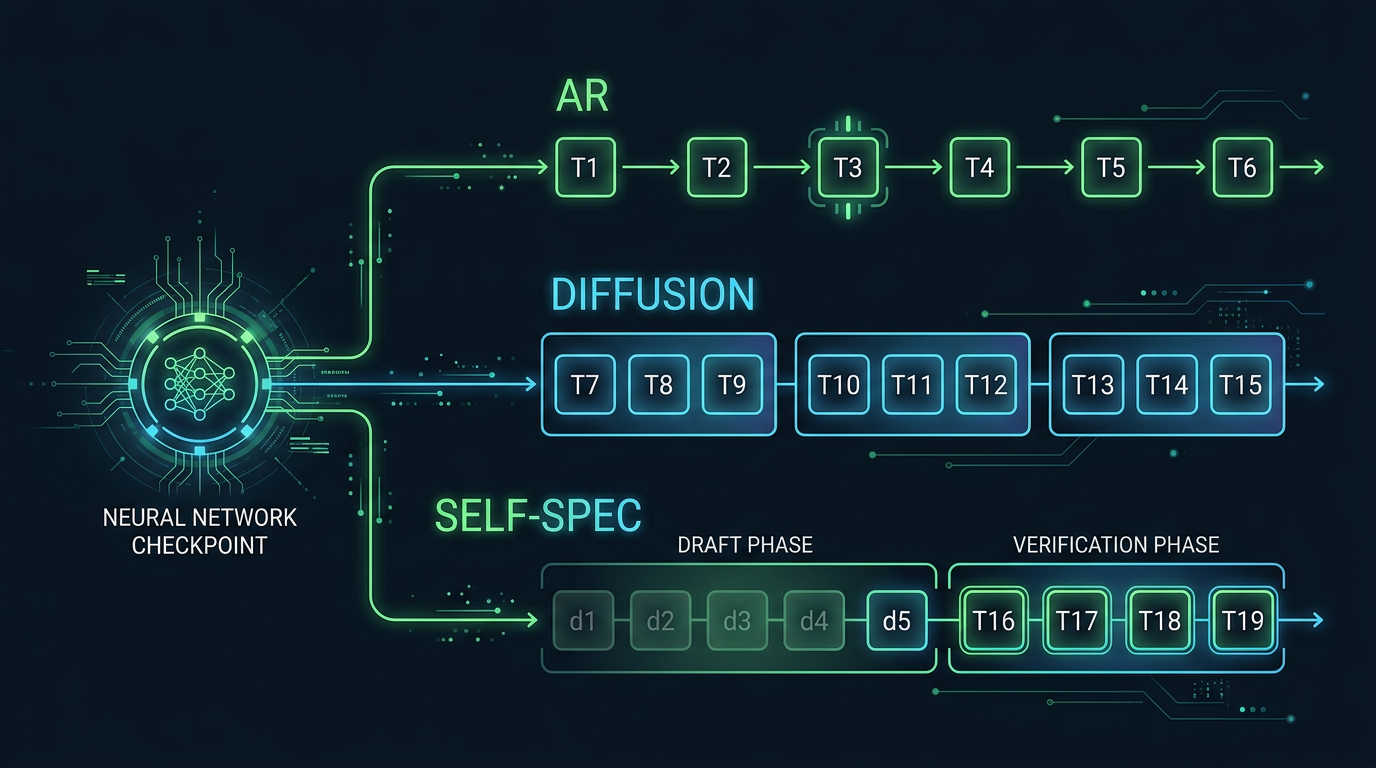
Kjernen i modellen er at én enkelt checkpoint støtter tre vidt forskjellige måter å generere tekst på – uten arkitekturmodifikasjoner. Du velger modus basert på hva du trenger akkurat der og da.
Autoregressive (AR) modus er den klassiske venstretil-høyre-genereringen med kausal attention. Én token per forward pass. Ingenting nytt her, men det betyr at modellen er fullt kompatibel med eksisterende AR-infrastruktur – noe som er viktig for produksjonssystemer med høy concurrency i skyen.
Diffusion modus denoiser flere tokens parallelt innen faste blokker. Innenfor hver blokk er attention bidireksjonell, men på tvers av blokker forblir den kausal. Ved threshold 0.9 oppnår dette 2.57 tokens per forward pass (TPF) – altså mer enn dobbelt så mange tokens per kjøring sammenlignet med standard AR. På en GB200 med batch size 1 gir dette 3.3 ganger høyere gjennomstrøm enn ren AR-modus.
Self-speculation modus er den mest interessante. Her bruker diffusjonshodet til å lage et utkast på k tokens parallelt, og deretter verifiserer AR-hodet dem i et andre pass. Ingen ekstern draft-modell er nødvendig – alt skjer internt i samme checkpoint. Med en LoRA-adapter oppnår dette nesten 6 tokens per forward pass, noe som er det som gir den 6-ganger-sammenligningen mot Qwen3-8B i overskriften.
Hva er acceptance length, og hvorfor er det et nøkkeltall?
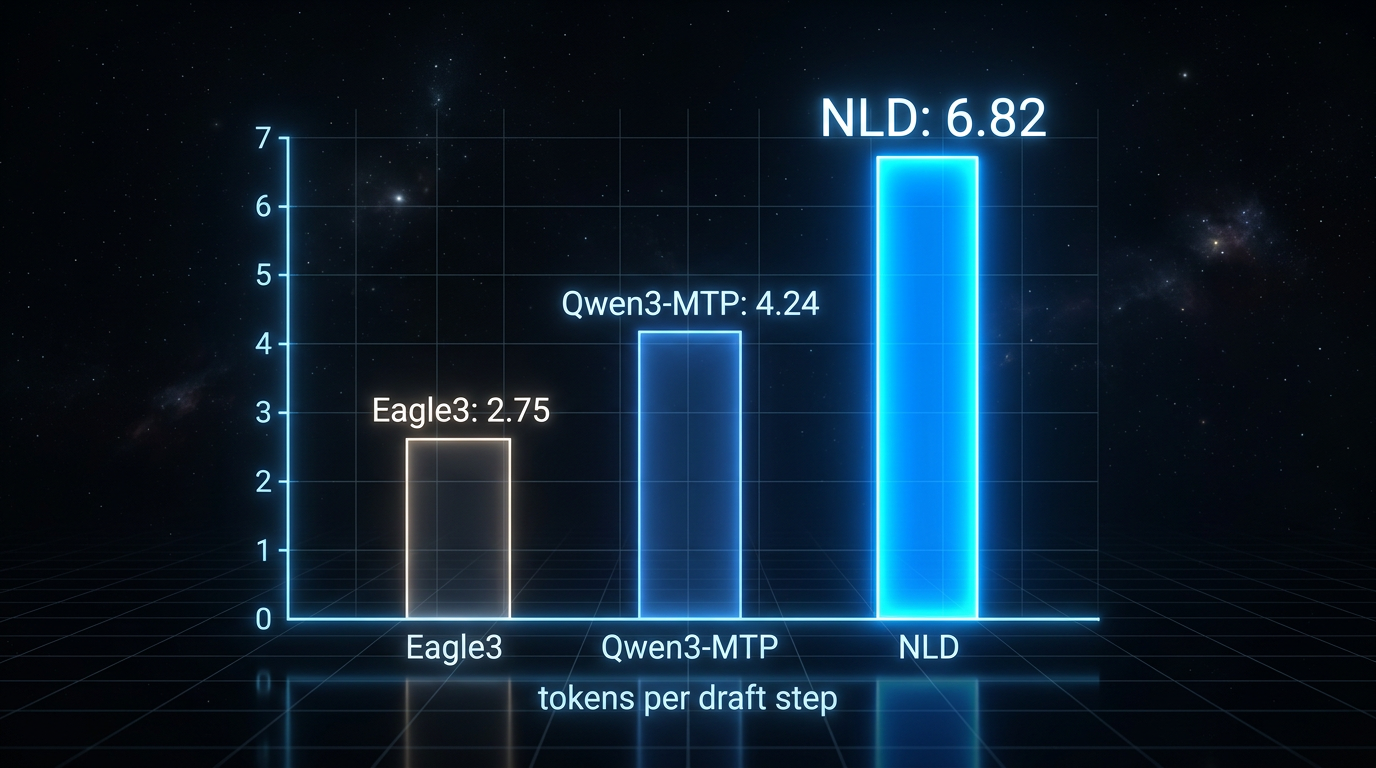
Acceptance length er gjennomsnittlig antall tokens som godkjennes per draft-steg i spekulativ dekoding. Jo høyere tall, jo mer effektivt er systemet – og her skiller Nemotron-Labs-Diffusion seg tydelig fra alternativene.
Med LoRA-adapter oppnår modellen 6.82 tokens per draft-steg på standard oppgaver. Eagle3, som er en av de sterkeste etablerte metodene for spekulativ dekoding, oppnår 2.75 tokens. Qwen3-9B-MTP klarer 4.24 tokens. På strukturerte oppgaver som koding og matematikk øker NLD ytterligere til 8.69 tokens – nesten fire ganger Eagle3.
Dette er ikke bare et benchmarktall uten praktisk verdi. Høyere acceptance length betyr direkte at modellen trenger færre totale forward passes for å generere samme mengde tekst, noe som igjen betyr lavere latency og høyere throughput i produksjon. Særlig for edge-deployment og single-user-scenarier er dette relevant.
Sammenlignet med Eagle3 på GB200-hardware leverer NLD 2.4 ganger høyere gjennomstrøm. Det er et tydelig hopp, og det uten å ofre nevneverdig kvalitet – AR-modus-nøyaktigheten ligger på 63.61% mot Qwen3-8Bs 62.75% på instruct-evalueringen.
Hvordan ble modellen trent?
Treningsstrategien kombinerer to objektiver: standard AR next-token prediction og block-wise diffusion denoising loss, med koeffisient α=0.3 for diffusjonsleddet. Modellen startet med Ministral3-base som utgangspunkt.
Treningen skjedde i to faser. Først 1 billion tokens med rent AR-objektiv, deretter 300 milliarder tokens med det kombinerte objektiv. Hele treningskjøringen ble gjennomført på 256 NVIDIA H100-GPUer. Inference-pipelinen er frigitt via Megatron Bridge, som er NVIDIAs rammeverk for storskala språkmodell-inferens.
Det er verdt å merke seg at dette er et åpent slipp under NVIDIA Nemotron Open Model-lisensen, og modellvektene er tilgjengelige på Hugging Face. Dette er ikke et lukket API-produkt – det er noe du faktisk kan laste ned og kjøre.
Hvilken modus skal du velge til hva?
Det praktiske spørsmålet er selvfølgelig: når bruker du hva? NVIDIA har lagt opp til ganske tydelige brukstilfeller for de tre modusene.
AR-modus passer best for høy-concurrency API-serving i skyen. Hvis du har mange parallelle forespørsler og har bygget infrastruktur rundt standard AR-serving, endrer ingenting seg – modellen oppfører seg som en vanlig AR-modell.
Diffusion-modus er interessant for scenarier der du kan tolerere litt variabilitet i output-kvalitet mot høyere gjennomstrøm. Threshold-parameteren lar deg styre avveiningen: høyere threshold betyr færre tokens per pass men høyere kvalitet, lavere threshold gir mer aggressive parallelle drafts.
Self-speculation med LoRA er det beste valget for single-user og edge-deployment. Her får du mest igjen for hardware-ressursene fordi du maksimerer tokens per forward pass. Koding, matematikk og flerspråklig tekst er de oppgavene der dette utmerker seg mest – med 8.69 tokens per draft-steg på disse kategoriene.
Sammenlignet med det jeg tidligere har skrevet om diffusjonsbaserte språkmodeller, er dette en konkret implementering som faktisk leverer på løftet. Mercury 2 tok et steg i denne retningen med reasoning diffusion, men Nemotron-Labs-Diffusion kombinerer alle tre tilnærmingene i én arkitektur – og med hardware-tall som faktisk holder vann.
NVIDIA er ikke alene i feltet. Jeg har tidligere dekket Holotron-12B som bruker en hybrid SSM+attention-arkitektur for å doble gjennomstrøm, og NemoClaw-arkitekturen som NVIDIA brukte for AI-agent-kontroll. Nemotron-Labs-Diffusion er et annet angrepsvinkel på det samme grunnproblemet: hvordan får du mer ut av hvert forward pass.
Og AI-Q, NVIDIAs åpne forskningsagent, viser at selskapet er seriøst med open source-satsingen – noe som gir troverdighet til at Nemotron-Labs-Diffusion faktisk er tilgjengelig for nedlasting og ikke bare et showcase-slipp.
6.82 tokens per draft-steg i snitt, 8.69 på koding og matematikk. Det er ikke et lite hopp. Om dette er fremtiden for effektiv inferens, gjenstår å se – men tallene er vanskelige å overse.







