

Innhold Vis
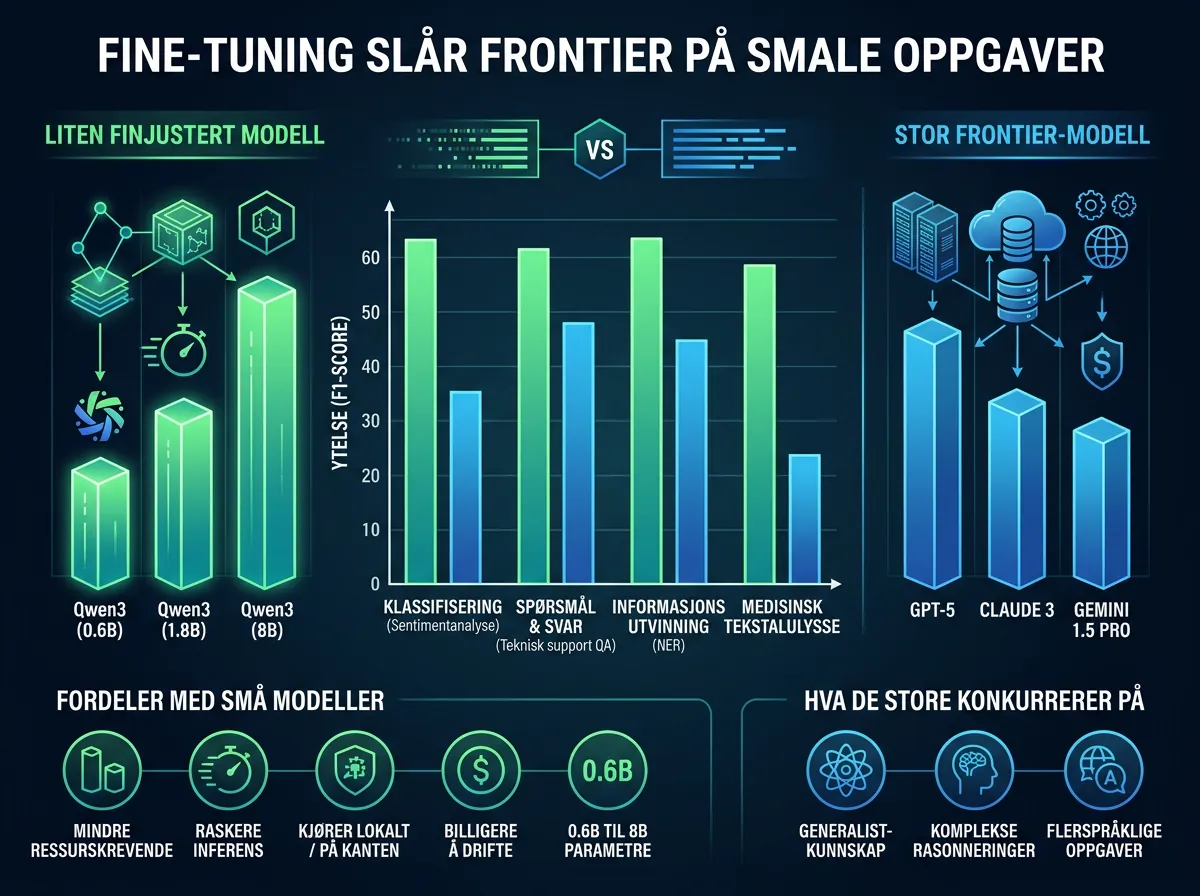
Fine-tunede Qwen3-modeller på 0,6 til 8 milliarder parametre slår frontier-modeller fra OpenAI, Anthropic og Google på smale oppgaver — og trenger bare 50 treningseksempler for å gjøre det. Det viser en ny systematisk sammenligning publisert på r/LocalLLaMA og Distil Labs’ blogg.
Studien er grundig. Tolv SLM-er ble testet mot GPT-5 nano/mini/5.2, Gemini 2.5 Flash Lite/Flash, Claude Haiku 4.5/Sonnet 4.6/Opus 4.6 og Grok 4.1 Fast/Grok 4 — over ni datasett som dekker klassifisering, function calling, QA og open-book QA. Alle de distillerte modellene ble trent utelukkende med open-weight lærere. Ingen frontier-API-data i treningsloopen.
Resultatet er det som i beste fall kan kalles et tankekors for frontier-leverandørene: en 4B-modell som koster 30 øre bildet å kjøre på én GPU, kan gjøre jobben bedre enn en API som koster hundrevis av kroner per million tokens.
Hva ble testet, og hvem vant?
Qwen3-familien dominerte rangeringen. Qwen3-4B-Instruct-2507 tok førsteplassen blant fine-tunede modeller med en gjennomsnittsrangering på 2,25 — og matchet eller overgikk læreren på syv av åtte benchmarks. Dramatisk forbedring på SQuAD 2.0: pluss 19 prosentpoeng etter fine-tuning.
Qwen3-8B hadde best grunnytelse uten fine-tuning (rangering 1,75). Qwen3-0.6B — en modell som er så liten at den går på en mobil — viste den største relative forbedringen fra fine-tuning. Fine-tuning matter faktisk mer enn valg av grunnmodell, konkluderer forskerne. En veltilpasset 1B-modell kan slå en uprøvd 8B-modell.
Treningsdataen? Femti eksempler. Ikke femti tusen. Femti.
Hvorfor er dette viktig nå?
Fordi det snur en grunnleggende antagelse: at de store modellene alltid er best. Det er de ikke, på smale domener. En finansinstitusjon som klassifiserer kundespørsmål, et e-handelsnettsted som tagger produkter, en helsetjeneste som kategoriserer henvendelser — ingen av dem trenger GPT-5 eller Claude Opus for de oppgavene. De trenger en liten, presis, billig modell som er finjustert på akkurat deres data.
Og nå viser tallene at de faktisk kan gjøre det bedre. Ikke bare «nesten like bra». Bedre.
Dette henger tett sammen med det Seldo argumenterte for nylig: 2026 er fine-tuningens år. Fine-tuning er blitt orders of magnitude billigere. Cursor bruker allerede fine-tunede småmodeller for spesifikke kodingsoppgaver. Det er ikke en trend — det er en utvikling som allerede er i gang.
Jeg har skrevet om Qwen3.5 9B som effektiv modell for lavere kost tidligere, og om Qwen 3.5 4B som løser abstraksjonstester GPT-4 feiler på. Men dette er noe annet. Dette handler ikke om at en 9B-modell er overraskende god — det handler om at en systematisk metodikk for fine-tuning gjør at en 0,6B-modell kan konkurrere med de største frontier-API-ene på avgrensede oppgaver.
Hva betyr «narrow tasks» i praksis?
De ni datasettene i studien er representative for reelle brukstilfeller:
- TREC — spørsmålsklassifisering
- Banking77 — klassifisering av bankhenvendelser (77 kategorier)
- Ecommerce — kategorisering av e-handelsspørsmål
- Mental Health — klassifisering av psykisk helse-innhold
- HotpotQA — flertrinns faktaspørsmål
- Roman Empire QA — open-book QA
- SQuAD 2.0 — leseforbedring med ubesvarte spørsmål
- Function calling og strukturert output
Banking77 alene viser poenget: 77 kategorier for kundestøtte i bank. En fine-tunet Qwen3-0.6B kan lære seg alle 77 på 50 eksempler og bli bedre enn GPT-5 som aldri har sett akkurat din data. Det er ikke magi — det er spesialisering.

Hva koster det å kjøre dette selv?
Inferens i studien kjørte på vLLM på en enkelt H100 GPU. Det er ikke en maskin folk flest har hjemme, men det er ikke poenget. Poenget er at en 0,6B-modell kan kjøre på svært beskjeden hardware. En 4B-modell går på en moderne laptop med 16 GB RAM.
Alternativt kan du leie GPU-tid. En H100 koster omtrent 2-3 dollar i timen hos de fleste skytjenester. En fine-tuning-jobb med 50-500 eksempler tar minutter, ikke timer. Total kostnad: kanskje 20-50 kroner for hele treningsjobben. Deretter kjører du modellen lokalt.
Sammenlignet med GPT-5 API til 4-8 dollar per million output-tokens, er regnestykket enkelt. Har du volum, lønner det seg fort.
Er det noen begrensninger?
Ja, og det er viktig å nevne dem. Disse resultatene gjelder for smale oppgaver — altså oppgaver med klart definert input og output, der du kan samle representativt treningsdata. Generell resonnering, kreativ skriving, kompleks kodeforståelse — der vinner fortsatt de store modellene.
Og «50 eksempler» er et minimum. Du trenger gode eksempler. Skrapet, ukalibrert treningsdata gir skrapet resultat. Garbage in, garbage out gjelder fortsatt.
Men innen de rette domenene? Tallene lyver ikke. En Qwen3-4B-modell finjustert på dine data slår GPT-5 på klassifisering av dine kundehenvendelser. Det er fakta fra benchmarks — ikke markedsføring.
Konklusjon: Fine-tuning er ikke fremtiden, det er nåtiden
Det interessante med denne studien er ikke at den avslører noe nytt — prinsippet om at spesialiserte modeller slår generalister er gammelt. Det interessante er at det nå er kvantifisert systematisk, og at barrieren er blitt så lav (50 eksempler, open-weight lærere, ingen frontier-API-avhengighet) at det er innenfor rekkevidde for nesten alle med en konkret brukscase.
Markedet ser ut til å bevege seg i denne retningen allerede. Frontier-modellene er fremdeles enestående for komplekse, generelle oppgaver. Men for de stabile, gjentakende oppgavene som utgjør mesteparten av AI-implementasjoner i praksis? Kanskje er en 4B-modell du eier og kontrollerer selv, bedre enn å betale per token for alltid.
Det er i alle fall verdt å teste.







