

Innhold Vis
H Company og NVIDIA lanserte Holotron-12B 16. mars 2026 – en åpen, multimodal modell bygget spesifikt for computer-use agents. Modellen er basert på NVIDIAs Nemotron-Nano-12B-v2-VL arkitektur og trenet på H Companys proprietære data for skjermforståelse og UI-navigasjon. Lisensen er NVIDIAs Open Model License, og vektene er tilgjengelig på Hugging Face.
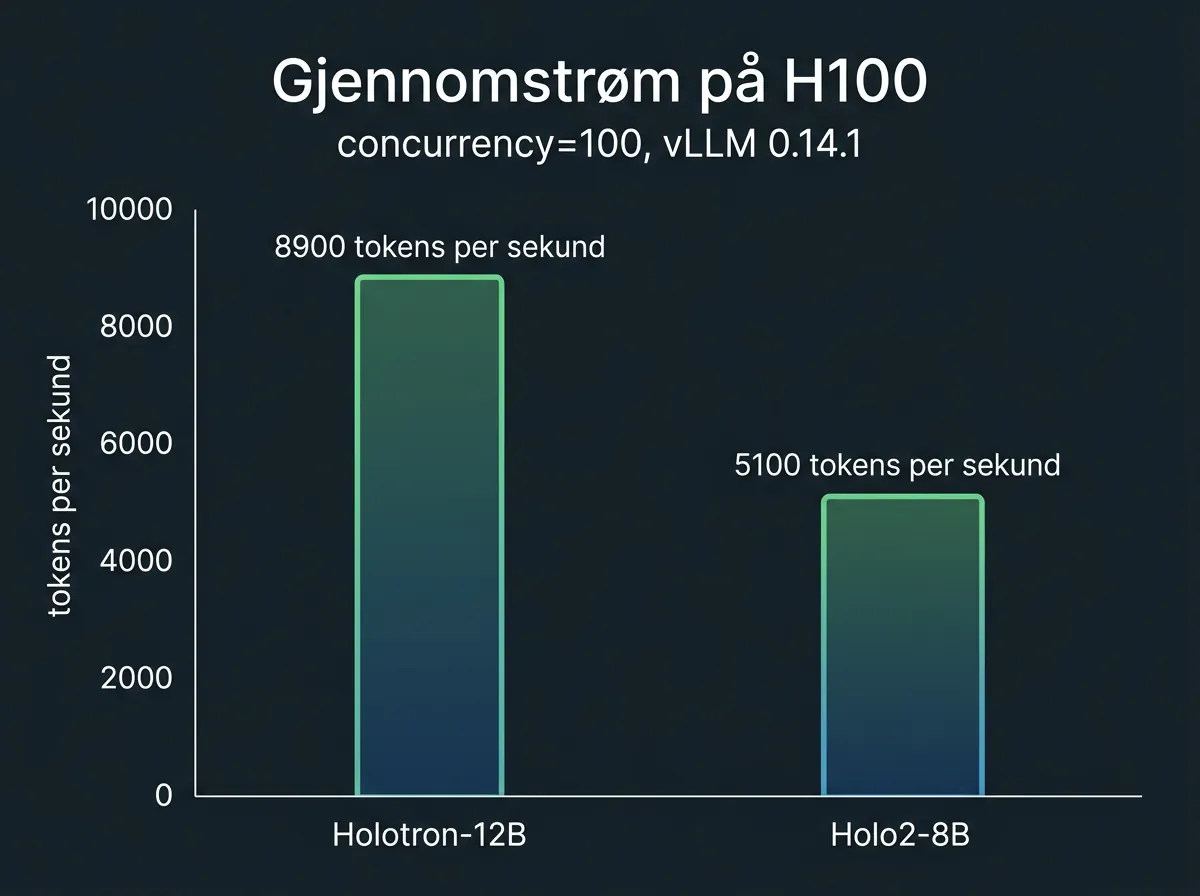
Det som skiller Holotron-12B fra konkurrentene er ikke primært nøyaktighet – der matcher den Holo2 og Qwen-baserte modeller på benchmark WebVoyager med rundt 80,5%. Det interessante er throughput. På en enkelt H100 med vLLM kjører Holotron-12B over 8 900 tokens per sekund ved concurrency 100. Holo2-8B lander på 5 100. Det er over 2x høyere gjennomstrøm fra en modell som holder samme nøyaktighet.
For de som bygger agentic systemer med høy last er det en vesentlig forskjell.
Hva er Holotron-12B egentlig?
Holotron-12B er et Vision-Language Model (VLM) designet for å fungere som «hjernen» i computer-use agents – systemer som navigerer web, desktop og mobile grensesnitt autonomt. H Company har siden 2024 bygget opp modell-familien sin fra Holo1, via Holo1.5 og Holo2, og lanserte i forrige uke Holo2-serien basert på Qwen3-VL. Holotron-12B er derimot et resultat av samarbeidet med NVIDIA, og bruker en annen grunnarkitektur.
Modellen er trent i to trinn fra Nemotron-Nano-12B-v2-VL-BF16, med supervised fine-tuning på H Companys datasett for lokalisering og navigasjon. Treningsomfanget ligger på rundt 14 billioner tokens. Det smarte med arkitekturen er at den bruker hybrid State-Space Model (SSM) kombinert med attention – som gir lineær kompleksitet i stedet for kvadratisk. Det betyr lavere minnebruk og bedre skalering ved lange kontekster og mange bilder.
H Company driver også Surfer-H – en web-agent som bruker disse modellene for å utføre oppgaver autonomt. Med Holotron-12B får Surfer-H en backend som tåler høyere last uten å gå på bekostning av nøyaktighet.
Hvordan sammenligner Holotron-12B med Holo2 og Qwen?
På WebVoyager-benchmark, en av de viktigste for computer-use, scorer Holotron-12B 80,5% – omtrent på linje med Holo2-8B. Nemotron-baselines uten H Companys fine-tuning landet på 35,1%. Det forteller noe om verdien av spesialisert trening på UI-data.
Holo2-serien er basert på Qwen3-VL og tilbyr modeller i 4B, 8B og 30B-A3B størrelser. Holotron-12B er ikke en direkte Holo2-konkurrent, men snarere et alternativ for brukere som vil unngå Qwen-arkitekturen – enten av preferanse eller infrastrukturhensyn. H Company er transparente på at begge linjer eksisterer og har ulike use cases.
Throughput-fordelen på 2x er viktig for produksjonssystemer. Sett for deg en agentic pipeline som kjører 100 parallelle browsing-sesjoner. Med Holotron-12B vil du betjene samme last med halvparten av compute-ressursene sammenlignet med Holo2-8B. Eller doble kapasiteten med samme hardware.
Hybrid SSM – hva betyr arkitekturen i praksis?
De fleste VLM-er bruker transformer-arkitektur med full attention, der beregningskostnaden vokser kvadratisk med sekvens-lengden. Det er greit for kortere kontekster, men blir dyrt når agenter håndterer lange websider med mange bilder og scrolling-historikk.
Hybrid SSM løser dette ved å kombinere tradisjonell attention for de delene av nettverket der det gir mest verdi, med State-Space Model-lag for resten. SSM-lagene har lineær kompleksitet og konstant minnefotavtrykk uavhengig av sekvens-lengde. For en computer-use-modell som kontinuerlig prosesserer skjermbilder og brukerinteraksjoner er dette en arkitektur som skalerer bedre.
Resultatet er ikke bare raskere inferens – det er også lavere GPU-minnebruk per request, noe som gjør det mulig å kjøre høyere concurrency på samme hardware.
Slik kjører du Holotron-12B lokalt
Holotron-12B er åpen kildekode med NVIDIAs Open Model License, tilgjengelig på Hugging Face. For å kjøre modellen lokalt trenger du noen spesifikke avhengigheter siden arkitekturen bruker Mamba SSM:
Installer avhengigheter med pip. Du trenger torch, en spesifikk versjon av transformers (over 4.53, under 4.54), causal_conv1d, timm, mamba-ssm versjon 2.2.5, accelerate, open_clip_torch, numpy og pillow. Versjonskravene er strenge – spesielt for mamba-ssm. Det er verdt å sette opp et eget virtuelt miljø for dette.
For produksjonssystemene som benchmarks er kjørt på ble vLLM 0.14.1 brukt på en enkelt H100. Throughput-tallene på 8 900 tokens/s er i den konteksten. Lokalt på forbruker-hardware vil du naturligvis se lavere tall, men arkitekturfordelene holder seg.

Er dette relevant for deg som bygger med AI-agenter?
Holotron-12B er en spesialistmodell. Den er ikke nyttig for generell tekst-generering, koding eller samtale. Bruksområdet er smalt: autonome agenter som navigerer digitale grensesnitt. For de som jobber med akkurat det er det en av de mer interessante open-source-lanseringene på en stund.
At NVIDIA er involvert er ikke overraskende – de har vært aktive med Nemotron-serien og bruker ekstern samarbeid for å posisjonere sine åpne modeller i agentic-segmentet. Artikkelen min om NVIDIAs satsing på open-weight modeller fra forrige uke er relevant kontekst her – Holotron-12B er et praktisk eksempel på denne strategien.
For utviklere og bedrifter som eksperimenterer med RPA-aktig automatisering, nettskraping, eller testing av web-applikasjoner er computer-use-modeller et felt som beveger seg fort. H Company er et av de få selskapene som konsekvent har bygget ut hele stacken – fra modell til agent-runtime med Surfer-H. Holotron-12B er et skritt i retning av å gjøre denne teknologien tilgjengelig for høyere skala.
Om du vil lese mer om hvordan AI-agenter kan effektivisere arbeidsflyter uten å sprenge budsjettet, har jeg skrevet om metoder for å kutte agent-kostnader med 80% – som er en naturlig parallell til throughput-fordelene Holotron-12B gir.








2 kommentarer