

Innhold Vis
Nicholas Carlini er en av verdens mest siterte sikkerhetsforskere – 67 200 siteringer på Google Scholar. Han har jobbet ved Google Brain, DeepMind og er nå Research Scientist hos Anthropic. Han har CVE-er til sitt navn. Han har funnet sårbarheter som ingen andre fant. Og likevel sa han nylig noe som stoppet meg helt: «Disse modellene er bedre sikkerhetsresearchere enn meg.»
Ikke som clickbait. Ikke som markedsføring. Som en sober konstatering fra en mann som faktisk vet hva han snakker om.
Carlini holdt nylig et foredrag der han viste konkret hva Claude klarer å gjøre innen sikkerhetsresearch – zero-day sårbarheter i Linux-kjernen, en kritisk SQL-injeksjon i Ghost CMS, og 3,7 millioner dollar hentet ut fra smarte kontrakter. Tallene er ikke teoretiske. Resultatene er ekte. Og implikasjonene er store.
Hvem er Nicholas Carlini?
Carlini har Ph.D. fra UC Berkeley, jobbet ved Google Brain fra 2018, DeepMind fra 2023, og er nå forsker hos Anthropic. Han forsker på hva man kan gjøre med og mot språkmodeller – altså angrep og forsvar i ett. Hans arbeider har vunnet best-paper-priser fra IEEE S&P, USENIX Security og ICML.
Kort sagt: han er ikke en tech-entusiast som kjøper hypen. Han er en av menneskene som best forstår hva disse modellene faktisk gjør. Og han er bekymret.
Ikke panisk. Men bekymret. Det er en viktig distinksjon.
Hva fant Claude som Carlini selv aldri hadde funnet?
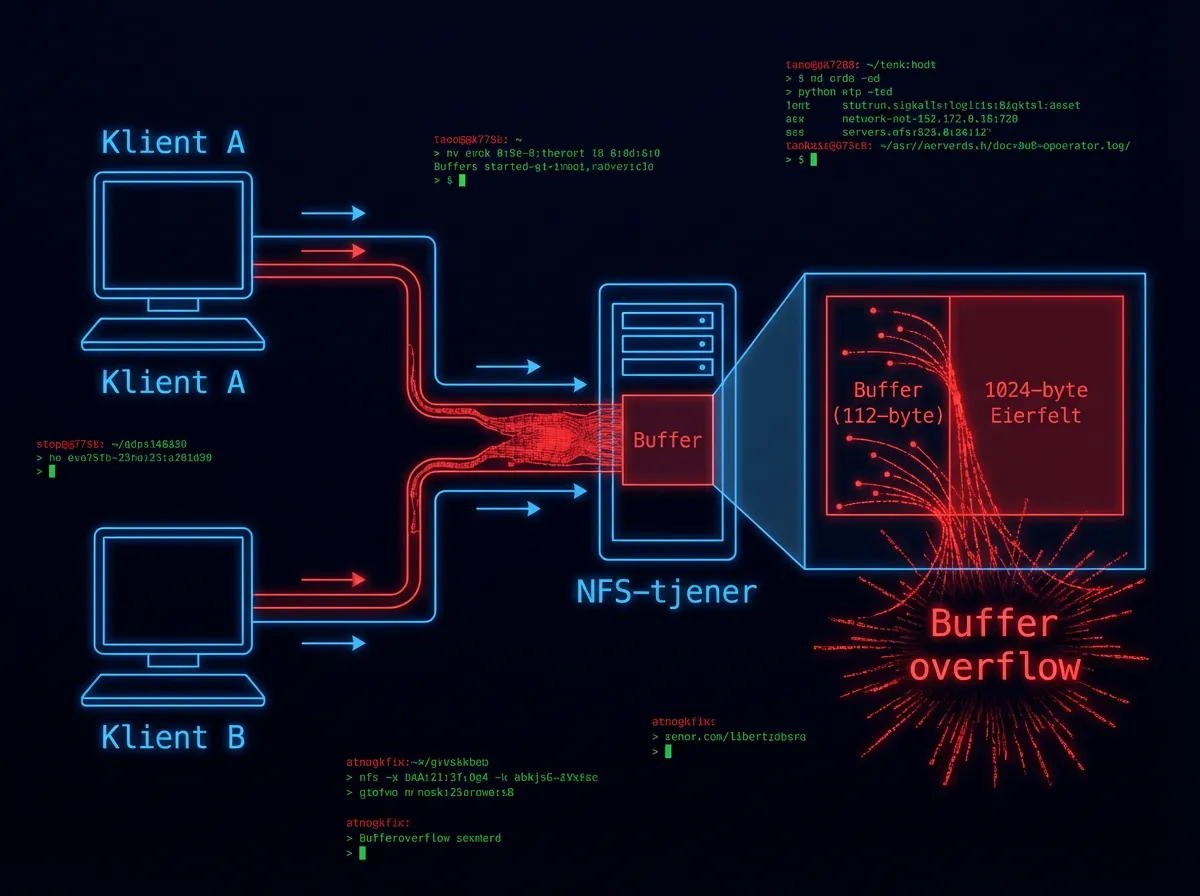
Det mest dramatiske eksempelet fra foredraget hans var en sårbarhet i Linux-kjernen. Ikke en liten bug. En heap buffer overflow i NFS v4-daemonen. Og ikke en ny bug – den ble introdusert i koden i 2003. Den har ligget der i over 20 år.
Carlini er eksplisitt: han har aldri funnet en slik sårbarhet i Linux-kjernen selv. Det er en av de vanskeligste typene sikkerhetsfeil å finne – du må koordinere to separate klienter som sender spesifikke pakker i riktig rekkefølge for å trigge en buffer overflow som gir angriperen kontroll over systemet. Ingen fuzzer ville funnet dette. Det krever forståelse av logikkflyten, ikke bare tilfeldige inputs.
Og det som virkelig traff meg: rapportdokumentet som beskriver angrepet? Det var Claude som laget det. Carlini kopierte og limte det inn i presentasjonen sin uten endringer.
Ghost CMS: 20 år uten kritisk sårbarhet – inntil nå
Ghost er en populær publiseringsplattform med over 50 000 GitHub-stjerner. I hele sin 20 år lange historie har den aldri hatt en kritisk sårbarhetsvurdering. Claude fant den første.
En blind SQL-injeksjon i Content API – uautentisert tilgang som gir deg admin API-nøkkel, hemmeligheter og passord-hash. Carlini var ikke sikker på om det var utnyttbart i det hele tatt. Så han ba Claude prøve. Modellen skrev hele angrepskoden selv – inkludert binærsøk-logikken som trengs for blind SQL-injeksjon der du ikke ser output direkte, bare kan observere responstid.
«Jeg hadde sikkert klart dette selv,» sa Carlini, «men det er noe nuanse her som krever sikkerhetserfaring – og jeg trengte ingen for å få dette til å skje.»
Det er det som er poenget. Ikke at Claude er superintelligent. Men at terskelen for å utnytte komplekse sårbarheter har falt dramatisk.
3,7 millioner dollar fra smarte kontrakter
Den tredje demonstrasjonen handlet om smarte kontrakter på blokkjeden. Forskning publisert av Anthropic viser at nyere modeller – Claude Opus 4.5, Sonnet 4.5 og GPT-5 – klarte å finne og utnytte sårbarheter i faktiske smarte kontrakter som tilsvarte 3,7 millioner dollar i stjålne midler. I simulerte omgivelser, altså – men med ekte kontrakter.
Det som gjør dette interessant fra et sikkerhetsperspektiv: kontraktene ble utnyttet etter modellenes kunnskaps-cutoff-dato. De hadde aldri «sett» disse kontraktene under trening. De resonnerte seg frem til angrepene fra grunnen av.
Og logaritmeskalaen på grafen Carlini viste over tid sier alt. Evnen til å finne disse sårbarhetene vokser eksponentielt.
Hva er det egentlig Claude gjør som er nytt?
Carlinis forklaring er nøktern og presis. Han sier at 90% av sikkerhetsresearch handler om mønstergjenkjenning – «dette ligner på noe vi har sett før.» Modellene er ekstraordinært gode på dette. De kan scanne enorme kodebaser raskere enn noe menneske.
Scaffolden han bruker er overraskende enkel. Claude Code, en VM med vide tillatelser, og en instruksjon: «Du spiller CTF. Finn den mest alvorlige sårbarheten og skriv den til denne output-filen. Gå.» Deretter peker han modellen på én fil om gangen for å sikre bred dekning.
Ingen avansert fuzzing-infrastruktur. Ingen måneder med spesialisert oppsett. Bare modellen og en haug med kode.
Det er det som er skremmende – og fascinerende på samme tid.
Er Carlini bekymret?
Ja. Men han er ikke apokalyptisk. Han bruker et godt bilde: den industrielle revolusjon var generelt sett bra for menneskeheten – men de som levde gjennom den hadde det ganske tøft underveis.
Hans poeng er at vi er i overgangsfasen nå. Modellene som kan finne disse sårbarhetene er 3-4 måneder gamle. Eldre modeller som Sonnet 4.5 og Opus 4.1 klarte dette nesten aldri. De nyeste klarer det konsistent. Og dobbelingstiden for kapabiliteten er omtrent 4 måneder.
Han er skeptisk til de som sier «eksponenten bends snart.» Det er det folk har sagt om deep learning i 10 år. Det har ikke stoppet ennå.
Det som bekymrer ham mest er ikke dagens situasjon – det er at han personlig sitter med hundrevis av potensielle Linux-sårbarheter han ikke har rukket å validere. Og snart er det ikke bare han som har dette. Det er alle med internettilgang og en API-nøkkel.
Hva betyr dette i praksis?
Jeg har skrevet en del om AI-agenter og sikkerhetsproblemer tidligere, og om åpen kildekode-agenter som eksponerer sensitive data. Det bildet Carlini maler er noe annet og større.
Det er ikke lenger snakk om at dårlige aktører kan utnytte AI til å skrive spam eller lage phishing-meldinger. Vi snakker nå om autonome systemer som kan finne zero-day-sårbarheter i kritisk infrastruktur – operativsystemer, databaser, kjernekomponenter som Linux brukt av hundrevis av millioner systemer.
Carlinis call to action er verdt å ta på alvor: han oppfordrer sikkerhetseksperter til å hjelpe – ikke spesifikt Anthropic, men hvem som helst som jobber med dette problemet. OpenAI har sitt Aardvark-prosjekt. DeepMind jobber med det. Anthropic har sitt offensive sikkerhetsinitiativ.
Det han sier er egentlig ganske enkelt: dette er ikke et problem vi kan vente et år med å ta på alvor. Måneder teller.
Og den mest siterte sikkerhetsforskeren jeg noensinne har lest om sier nå at en AI er bedre enn ham. Det synes jeg vi bør ta innover oss.
Les komplett oversikt: AI-sikkerhet – hva du trenger a vite (2026).








1 kommentar