

Innhold Vis
Claude Mythos er en intern Anthropic-modell som per tidlig april 2026 har funnet over 500 høy-alvorlighets zero-day-sårbarheter i produksjons open source-kode. Modellen er ikke offentlig tilgjengelig, men detaljer lekket ut denne uken – og det som kom fram er noe av det mer tankevekkende jeg har sett innen AI og sikkerhet på lenge.
Kombinasjonen av Mythos-avsløringen, en live demo av AI som finner 23 år gamle bugs på 90 minutter, og en utilsiktet lekkasje av Claude Code-kildekoden – alt i løpet av samme uke – gjør at det er verdt å ta et skikkelig dypdykk i hva som egentlig foregår her.
For de som ikke har lest om den opprinnelige Carlini-demoen: jeg dekket den grundig her. Denne artikkelen handler om hva som har kommet til siden da – og hva det betyr at vi nå har et navn på modellen bak.
Hva er Claude Mythos?
Mythos er ikke en modell du kan bestille via API i dag. Det er en intern Anthropic-modell designet spesielt for sikkerhetsrelaterte oppgaver – sårbarhetsjakt, exploit-analyse, og det som kalles «multi-step attack reasoning». Detaljene kom ikke via en offisiell lansering, men gjennom en lekkasje.
Modellen skal ha et kontekstvindu på 1 million tokens. Det er mye – nok til å holde store kodebaser i hodet samtidig, uten å måtte «vinduisere» analysen og miste sammenhengen mellom filer og komponenter. For sikkerhetsforskning er dette praktisk talt et gjennombrudd: mange av de vanskeligste sårbarhetene involverer interaksjoner mellom deler av koden som ligger langt fra hverandre.
I samme lekkasje dukket det også opp spor av Opus 4.7 og Sonnet 4.8 i koden – modellnavn ingen hadde hørt om før. Det gir et glimt inn i Anthropics roadmap som åpenbart ikke var ment for offentligheten.
Ghost CMS og Linux-kjernen: hva skjedde i labben?
Nicholas Carlini, sikkerhetsforskeren hos Anthropic, kjørte en live demo der Claude ble sluppet løs på to mål. Jeg har skrevet detaljert om begge funnene tidligere, men for kontekstens skyld:
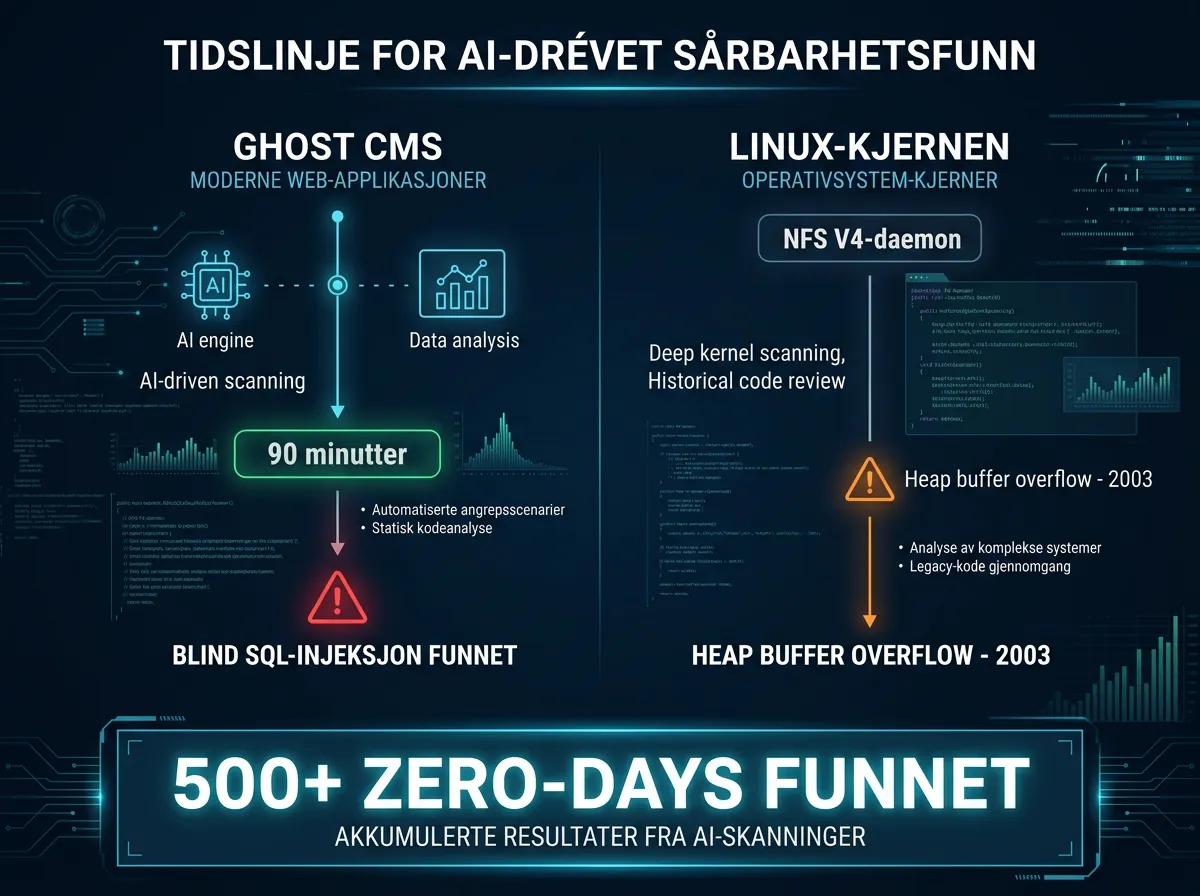
Ghost CMS er en populær open source bloggplattform med over 50 000 GitHub-stjerner – og ifølge Carlini hadde den aldri hatt en kritisk sårbarhet i sin 20-årige historie. På 90 minutter fant Claude en blind SQL-injeksjon i Content API-et. En uautentisert bruker – altså noen uten konto eller tilgang – kunne bruke sårbarheten til å hente ut admin-databasen, opprette sin egen admin-konto, og ta full kontroll over installasjonen.
Linux-kjernen fikk samme behandling. Resultatet: en heap buffer overflow i NFS V4-daemonen. Feilen hadde ligget der siden 2003. 23 år uten at noen menneskelig forsker hadde oppdaget den.
Begge disse funnene ble rapportert og patchet på ansvarlig vis. Men poenget er ikke de spesifikke sårbarhetene – poenget er hastigheten og bredden.
500+ zero-days – hva betyr det egentlig?
Per tidlig april 2026 har Claude funnet over 500 høy-alvorlighets zero-day-sårbarheter i produksjons open source-kode. Det er ikke 500 «potensielle problemer» eller lav-alvorlighets issues – dette er sårbarheter som ble vurdert som kritiske nok til å rapportere og fikse.
For å sette det i perspektiv: de mest produktive menneskelige sikkerhetsforskerne finner kanskje noen titalls kritiske sårbarheter i løpet av en karriere. Project Zero hos Google – et av verdens beste sikkerhets-team – publiserer rundt 20-30 zero-days i året, og det regnes som imponerende.
500+ fra én modell er et annet tallspråk helt.
Det som gjør dette spesielt interessant er at mange av disse funnene er i kode som har vært i produksjon i årevis. Som Linux NFS-feilen fra 2003: den levde i kjernen gjennom fire amerikanske presidentperioder, to finanskriser, og utallige sikkerhetsrevisjoner. AI fant den fordi den kan holde mer kode i arbeidsminnet samtidig, og fordi den ikke har de kognitive biasene som får menneskelige revisorer til å stole på «gammel, gjennomprøvd kode».
Claude Code-lekkasjen: bonusnyheten fra samme uke
Samme uke som Mythos-detaljene lekket, skjedde noe annet uventet: Claude Code CLI-kildekoden ble utilsiktet eksponert. En feilkonfigurert npm sourcemap førte til at hele TypeScript-kodebasen ble tilgjengelig – 900 filer, rundt 500 000 linjer kode.
Dette er ikke en sikkerhetskatastrofe i klassisk forstand – kildekoden til et CLI-verktøy er ikke det samme som å eksponere treningsvekter eller systemprompter. Men det gir et usedvanlig innsyn i hvordan Anthropic strukturerer en stor, kompleks AI-applikasjon. For utviklere som er nysgjerrige på arkitektur og design-valg i AI-verktøy, er 500 000 linjer TypeScript ganske mye å lese seg gjennom.
Ironien er ikke helt fraværende: en uke der verden diskuterer AI som sårbarhetsjeger, lekker Anthropic sin egen kildekode via en konfigurasjonsfeil.
Dobbeltsidig teknologi – forsvar og angrep
Her er det som faktisk holder meg våken litt ekstra: den samme teknologien som gjør Mythos nyttig for forsvarere, gjør den nyttig for angripere.
Carlini og Anthropic bruker dette til ansvarlig disclosure – finner feilen, varsler, venter på patch, publiserer. Det er slik god sikkerhetsforskning fungerer. Men en modell med samme evner i hendene på noen med andre intensjoner er et annet scenario. Check Point påpeker i sin analyse at dette demokratiserer angrepsfunksjoner som tidligere var forbeholdt ressurssterke aktører – nasjonalstater, store cyberkriminelle organisasjoner.
Tidligere trengte du dyktige mennesker med mange års erfaring for å finne og utnytte en heap buffer overflow i Linux-kjernen. Med Mythos-klasse-modeller kan noen med langt lavere teknisk kompetanse potensielt sette i gang den samme prosessen.
Det er ikke en grunn til panikk – det er en grunn til å ta sikkerhetsarbeid mer alvorlig. Den gode nyheten er at forsvarerne har tilgang til de samme verktøyene. Spørsmålet er hvem som tar dem i bruk raskest og mest systematisk.
Hva bør du gjøre med denne informasjonen?
Hvis du driver et open source-prosjekt: ta sikkerhetsrevisjoner på alvor, og vurder AI-assistert kodeanalyse som en del av prosessen. Verktøy som GitHub Copilot Autofix og lignende begynner å nærme seg denne typen analyse for vanlige utviklere.
Hvis du kjører Ghost CMS eller andre populære open source-plattformer: hold deg oppdatert på patches. Responsvinduet mellom funn og utnyttelse krymper. Det var en periode der du hadde uker på å patche en kritisk sårbarhet etter at den ble publisert. Den perioden er på vei til å bli kortere.
Og hvis du er interessert i AI-sikkerhet generelt: Carlinis observasjon om at «disse modellene er bedre sikkerhetsresearchere enn meg» er ikke beskjeden markedsføring. Det er en av verdens mest siterte sikkerhetsforskere som beskriver en reell kapasitetsendring – og han jobber hos Anthropic, så han har sett det på nært hold.
Det er ikke skremmende. Det er fascinerende. Og det er et felt som kommer til å se mye mer aktivitet de neste 12-24 månedene.
Mythos og fremtiden for AI-assistert sikkerhetsforskning
Det som er interessant med Mythos er ikke bare tallene – det er hva de forteller om retningen. Dobbelingstiden for AI-modellers evne til å finne sårbarheter er anslått til rundt fire måneder. Det betyr at modellen som finnes om ett år trolig er vesentlig kraftigere enn det vi ser nå.
1 million tokens kontekstvindu er allerede nok til å holde relativt store kodebaser i hodet. Neste generasjon kan potensielt analysere et helt operativsystem som en sammenhengende enhet – ikke som fragmenter. Det åpner for funn av sårbarheter som involverer interaksjoner på tvers av delsystemer som aldri har vært analysert i sammenheng.
Mythos-lekkasjen er et signal om at dette ikke er forskning som ligger 5-10 år frem i tid. Det er et system som eksisterer i dag, som allerede har funnet 500+ reelle zero-days, og som Anthropic tydeligvis investerer tungt i.
Hva tenker du – er AI-assistert sikkerhetsrevisjon noe du ser som verdifullt for prosjekter du er involvert i? Gi gjerne en kommentar.









5 kommentarer