

Innhold Vis
Qwen3.5 Omni er Alibabas nye omnimodale AI-modell – den hører, ser, leser og snakker, alt samtidig, uten å bruke separate verktøy for hver ting. Lansert av Qwen-teamet i 2026, er dette en modell som prosesserer tekst, bilder, lyd og video nativt i én og samme modell.
Jeg er skeptisk til kinesiske modeller som regel. Men jeg kan ikke ignorere det som skjer med Qwen-serien – de har jevnlig levert modeller som overpresterer i forhold til størrelsen. Qwen3.5 Omni er noe annerledes igjen: det er ikke en tekstmodell med litt multimodal støtte slengt på, men en modell som er bygget omnimodal fra bunnen av.
Her er hva du trenger å vite.
Hva er Qwen3.5 Omni?
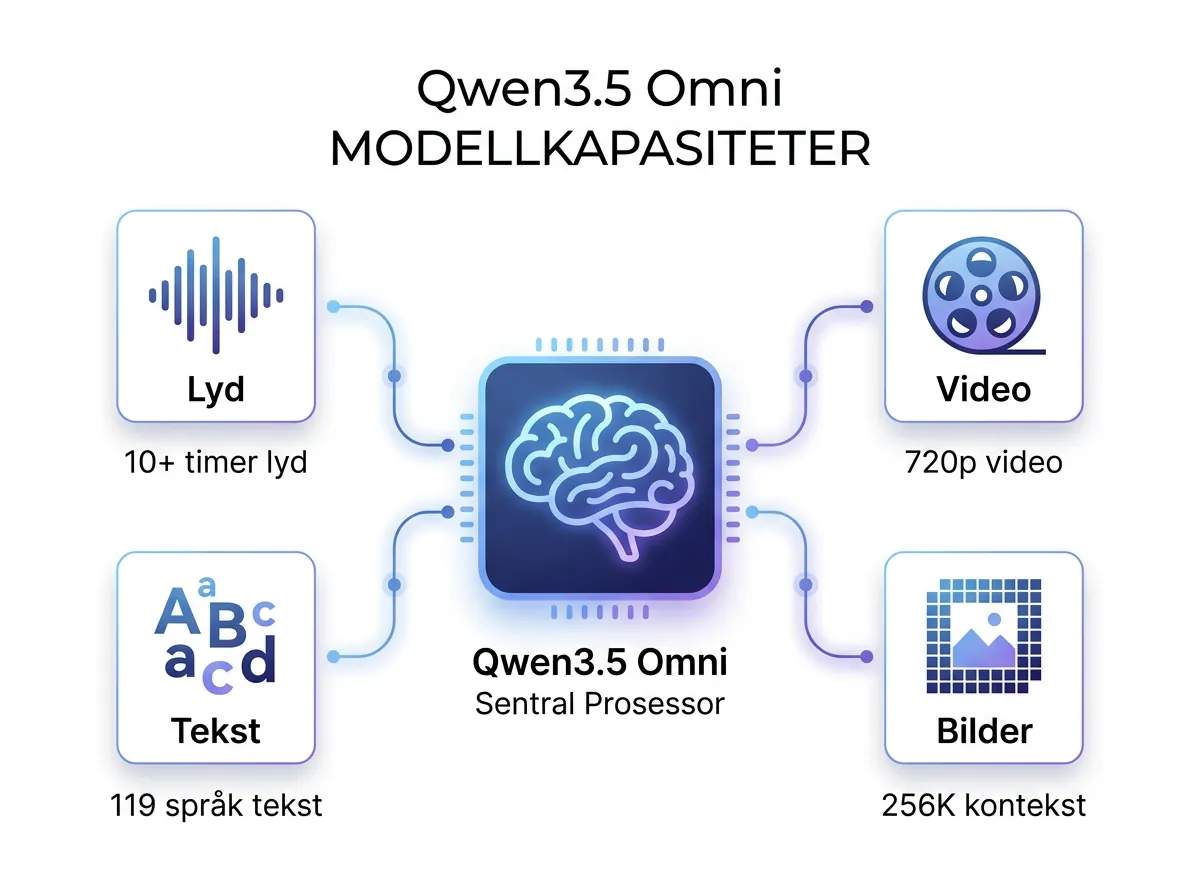
Qwen3.5 Omni er den tredje generasjonen av Qwens omnimodale modellserie. Den støtter nativt forståelse av tekst, bilder, lyd og video – og kan generere tekst og tale i sanntid. Ingen tredjepartsverktøy for transkripsjon, ingen separate pipeline-steg. Alt skjer i én modell.
Modellen bruker en Thinker-Talker MoE-arkitektur (Mixture of Experts). Thinker prosesserer og resonnerer, Talker genererer naturlig tale. Begge bruker Hybrid-Attention MoE. Det er en gjennomtenkt arkitektur for å holde latens nede mens man håndterer mange modaliteter.
Serien kommer i tre varianter: Plus, Flash og Light. Alle støtter et kontekstvindu på 256 000 tokens – det er ikke lite. Modellen er tilgjengelig via Hugging Face, ModelScope og DashScope API.
Hva kan modellen faktisk håndtere?
Her er det interessant. Qwen3.5 Omni er trent på over 100 millioner timer med audio-visuelt materiale. Det er en annen skala enn det vi vanligvis ser. Resultatet er at modellen klarer ting konkurrentene strever med:
- Lyd: Mer enn 10 timer med lydinnput i én kjøring
- Video: Over 400 sekunder med 720p video til 1 FPS
- Tekst: 119 språk for tekstinteraksjon
- Tale inn: 19 språk for taleforståelse
- Tale ut: 10 språk for talegenerering
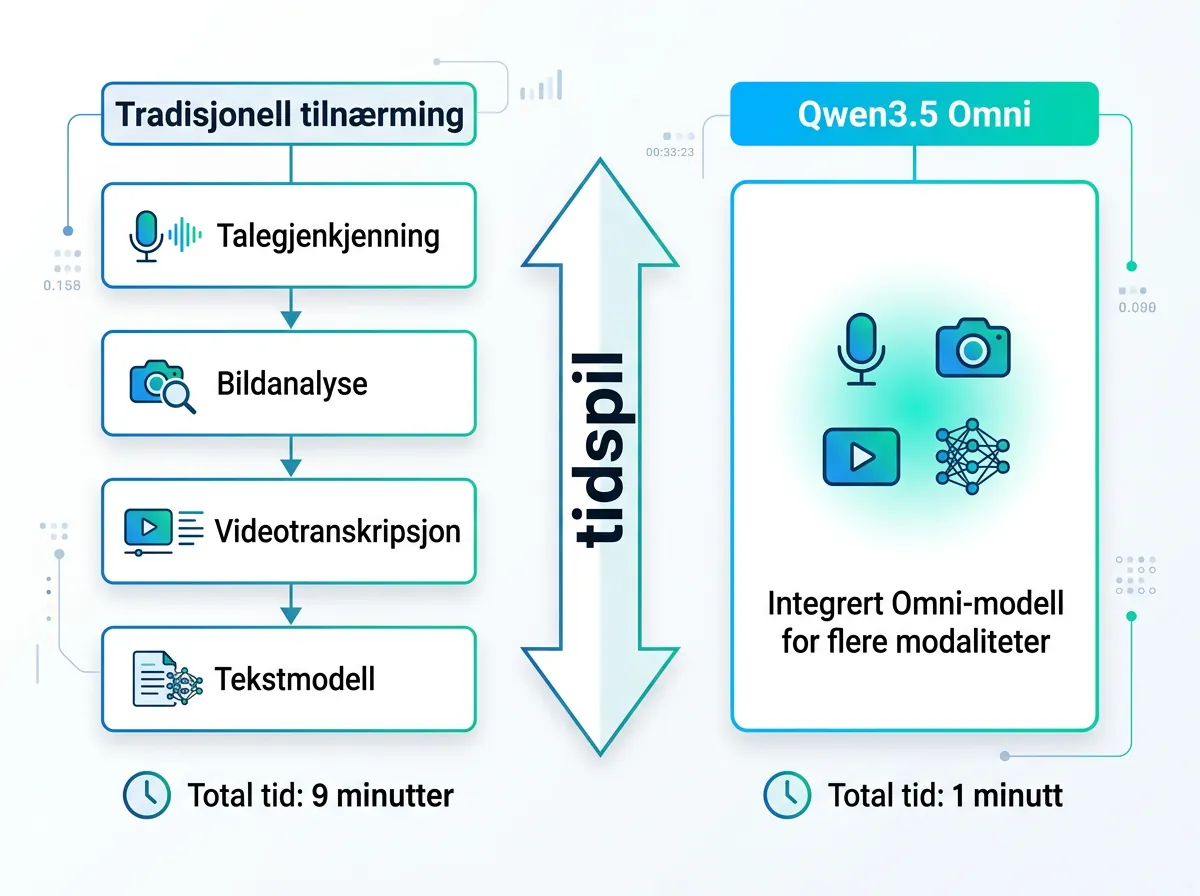
Til sammenligning: ChatGPT 5.4 brukte 9 minutter på å analysere en YouTube-video fordi den kombinerer separate vision-, transkripsjon- og OCR-verktøy. Qwen3.5 Omni gjorde det samme på rundt ett minutt – fordi det er én nativ operasjon, ikke en kjede av verktøy.
Hvordan yter den mot konkurrentene?
Qwen3.5 Omni Plus nådde state-of-the-art på 22 av 36 audio/video-benchmarks. På open source-benchmarks er det SOTA på 32 av 36. Det er gode tall.
Sammenligningen med Gemini 3.1 Pro er den som har fått mest oppmerksomhet: Qwen3.5 Omni Plus overpresterte Gemini 3.1 Pro på generell audioforståelse, resonnering og oversettelse. På audio-visuell forståelse lå de likt. Det er ikke dårlig for en open source-modell fra Alibaba.
På talegjenkjenning dekker modellen nå 113 språk – opp fra 19 i forrige generasjon. På flerspråklige benchmarks slo den ElevenLabs, GPT-Audio og Minimax på stemmestabilitet. Jeg har ikke testet dette selv, men tallene er verdt å merke seg.
Tidligere har jeg skrevet om Qwen Image Edit 2511 og hvordan Alibaba konsekvent leverer solid open source. Qwen3.5 Omni er en fortsettelse av det mønsteret – men på et helt annet nivå teknisk sett.
Hva er nytt i 3.5 vs forrige generasjon?
Qwen3.5 Omni bringer inn noen funksjoner som skiller seg ut fra forgjengeren:
Semantisk avbrudd. Modellen kan nå skille mellom «mm-hmm» (du bare lytter) og et faktisk avbrudd der du vil ta ordet. Det høres ut som en liten ting, men det er avgjørende for naturlig samtaleflyt. Forrige generasjon klarte ikke dette.
Stemmekloning via API. Du kan laste opp en stemmesampler og modellen kloner stemmen. Tilgjengelig kun via API, ikke i web-grensesnittet. Bruksområdene er åpenbare – og misbrukspotensiale likeså, men det er en annen diskusjon.
Sanntids websøk. Modellen kan søke etter oppdatert informasjon mens den svarer. Dette er ikke unikt for Qwen, men det er bra at det er integrert nativt.
ARIA-teknikk for å synkronisere tekst og tale. Det gir mer naturlig uttale enn det man er vant til fra konkurrentene.
Er dette bedre enn Gemini 2.5 Pro på alt?
Nei. Og det er viktig å si. Benchmarks er benchmarks – de måler det de måler. På talegjenkjenning og audioforståelse er ytelsen sammenlignbar med Gemini 2.5 Pro. Ikke bedre, sammenlignbar. På noen audio/video-benchmarks er Plus-varianten sterkere. Men det er Googles offisielle, ressurssterke modell mot et open source-alternativ fra Alibaba – konteksten der er relevant.
Jeg har skrevet om dette tidligere med Qwen 3.5 4B også – Qwen leverer konsekvent solid ytelse i sin størrelsesklasse, men det betyr ikke at de alltid topper listene absolutt sett. Husk at benchmarks er et utgangspunkt, ikke fasit.
Tilgjengelighet og lisensiering
Modellen er tilgjengelig via Hugging Face, ModelScope og DashScope API. GitHub-repositoriet er åpent. For de som vil kjøre den lokalt finnes Docker-støtte for komplett runtime-miljø.
Det er verdt å merke seg at Alibaba er kinesisk selskap. Det påvirker ikke nødvendigvis hva du kan bruke modellen til, men det er relevant kontekst for de som er opptatt av datakilde og treningsdata-opprinnelse. Vurder det ut fra ditt brukstilfelle.
Qwen3.5 Omni representerer uansett et markant steg fremover for omnimodale open source-modeller. Konkurransen med Gemini og GPT er reell – og det er bra for alle som bruker disse verktøyene.








1 kommentar