

Innhold Vis
Intel Arc Pro B70 er et grafikkort med 32 GB VRAM til $949 – en pris som gjør det til det mest VRAM-rike GPU-et under $1 000 på markedet. Lansert i april 2026, er det rettet mot lokale LLM-brukere som vil kjøre store modeller uten å betale RTX 5090-priser. Men som tidlige brukere raskt har funnet ut: maskinvaren er imponerende, programvaren er et kaos.
Fellesskapet på LocalLLaMA Reddit har allerede testet kortet grundig. Tallene er gode – 235 tokens per sekund med Gemma 3 27B på vLLM med 100 parallelle forespørsler er ikke dårlig. Men veien dit er brosteinslagt med dependency-konflikter, ødelagte installasjoner og manglende støtte for nyere arkitekturer.
Her er hva du trenger å vite om Arc Pro B70 hvis du vurderer det til lokal inferens – det gode, det dårlige, og det som er direkte frustrerende.
Hva er Intel Arc Pro B70?
Arc Pro B70 er Intels «Battlemage»-arkitektur i en workstation-versjon. Nøkkeltall: 32 GB GDDR6 VRAM på en 256-bit bus, 608 GB/s minnebåndbredde, 256 Xe Matrix Extensions-motorer, og PCIe 5.0-støtte. TDP på 230W. Pris: $949.
For kontekst: RTX 5090 har 32 GB VRAM, men koster tre ganger så mye. RTX 4090 har bare 24 GB. Så for ren VRAM per krone er B70 et attraktivt kort – du kan laste Q8-kvantiserte modeller på 27B-størrelse uten å stykke dem opp over flere kort.
Intel har posisjonert kortet direkte mot AI-inferens, ikke gaming. Det er ingen tilfeldig bonus-VRAM – dette er en gjennomtenkt produktbeslutning for å ta markedsandeler fra Nvidia innen lokal AI. Spørsmålet er om software-støtten holder tritt med ambisjonen.
Hva er ytelsen i praksis?
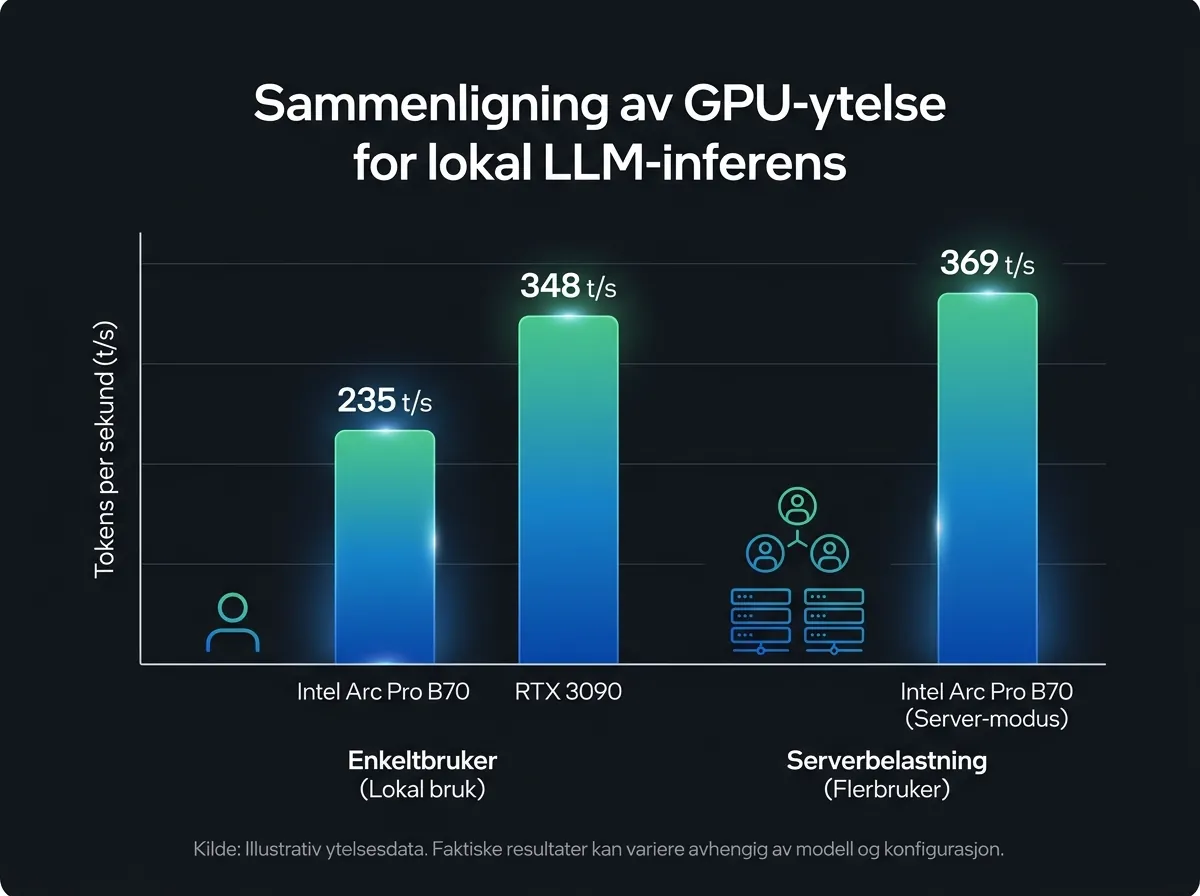
Tallene er faktisk ganske bra. Med vLLM og Gemma 3 27B oppnår tidlige brukere rundt 235 tokens per sekund under høy belastning (100 parallelle forespørsler). I multi-GPU-oppsett skalerer det godt: GitHub-prosjektet arc-pro-b70-inference-setup rapporterer 140 tokens/s på 2x B70 og 540 tokens/s på 4x B70.
Sammenlign med RTX 3090: I server-scenarioer med 50 samtidige forespørsler oppnår ifølge hardware-corner.net B70 rundt 369 tokens/s mot RTX 3090s 348 tokens/s. B70 vinner altså i gjennomstrømning. Men snur du det til enkeltbruker-modus, taper B70. RTX 3090 har 936 GB/s minnebåndbredde mot B70s 608 GB/s, og det merkes på single-request latens.
Poenget er: B70 er optimalisert for server-stil bruk med mange parallelle forespørsler. Vil du kjøre en lokal chatbot bare for deg selv? RTX 3090 eller 4090 gir bedre opplevelse per krone. Vil du hoste en intern AI-server for et lite team? Da begynner B70 å se mer attraktivt ut.
Hvorfor er software-stacken et problem?
Her er sannheten ingen i Intels markedsavdeling vil si høyt: CUDA har 15+ år med modning. Tusenvis av biblioteker, rammeverk og verktøy bygger på CUDA. Intel har ikke det. De har OneAPI og SYCL, som er teknisk kompetente, men et langt yngre og tynnere økosystem.
Konkret betyr det:
- vLLM krever veldig spesifikke versjoner – Python 3.12 og Ubuntu 24.04.3 er rapportert som nødvendig for stabil drift. Avvik fra dette, og ting begynner å gå galt.
- MoE-arkitekturer er dårlig støttet – Mixtral, DeepSeek og lignende Mixture-of-Experts-modeller er krevende å kjøre. Selv om Intel har jobbet med å forbedre dette, er det fortsatt langt bak Nvidia.
- Kvantisering av nye arkitekturer er skjørt – Vil du bruke en fersk modell med GPTQ eller AWQ? Held og lykke. Battlemage er primært optimalisert for FP16 og INT8. Nvidia Blackwell støtter FP4 – Intel gjør det ikke.
- ipex-llm er arkivert – Intel arkiverte ipex-llm-repositoriet i januar 2026 med begrunnelse «kjente sikkerhetsproblemer». Den offisielle veien fremover er llm-scaler via Docker, men dokumentasjonen er sparsom.
En bruker som testet B70 på launch-dag beskriver opplevelsen som å kjempe mot miljøet hele veien. Det er ikke én stor feil – det er hundrevis av små friksjonspunkter som hoper seg opp. Driver-versjoner som ikke matcher. Biblioteker som feiler stille. Modeller som ikke loader av ukjente grunner.

Er det verdt det i dag?
Kommer an på hvem du er.
Er du en eksperimenterende entusiast med tålmodighet for debugging, interesse for å bidra til åpen kildekode-støtte, og trenger 32 GB VRAM uten å betale RTX 5090-pris? Da er B70 interessant. Du vil finne løsninger, du vil lære mye, og du vil kanskje bidra til å gjøre kortet bedre for de som kommer etter deg.
Er du en bedrift eller profesjonell som trenger pålitelig, forutsigbar inferens i dag? Bli med Nvidia. RTX 4090 til 24 GB, RTX 5090 til 32 GB, eller et skymiljø som RunPod for tunge kjøringer. CUDA-støtte er ikke et valg du angrer på.
Vil du kjøre lokale modeller uten å bruke mye tid på oppsett? Ollama med et Nvidia-kort er fortsatt den enkleste veien – jeg har tidligere skrevet om hvordan du kommer i gang med Ollama på RTX 4090.
Hva med fremtiden for Intel Arc?
Intel er ikke passive. De har samarbeidet med vLLM-teamet aktivt de siste månedene, og støtten forbedres. Multi-GPU-skalering via PCIe P2P fungerer. MoE-ytelse er bedret. Det er tydelig at de investerer i å ta AI-markedet på alvor.
Men det tok Nvidia over et tiår å bygge CUDA-økosystemet. Intel kan ikke kjøpe seg den arven – de må bygge den steg for steg. Det betyr at B70 i 2026 er et kort for de som er villige til å akseptere «not for the faint of heart» som en reell advarsel, ikke markedsføringsjargong.
Om et år? Kanskje annerledes. Driver-støtte modnes, fellesskapet vokser, og Intel har insentiv til å fikse problemene. Arc Pro B60 Battlematrix med 192 GB samlede VRAM på tvers av seks kort viser at Intel tenker stort for enterprise-segmentet.
For nå er B70 et lovende kort fanget i software-purgatoriet. Maskinvaren er der. Programvaren er ikke.
Har du testet B70 selv, eller vurderer du det? Jeg er nysgjerrig på om erfaringene dine matcher det bildet som tegner seg fra fellesskapet.







