

Innhold Vis
ACE-Step 1.5 XL er en betydelig oppdatering av den open source musikk-AI-en som jeg testet i februar. XL-versjonen doblet modellstørrelsen til 4 milliarder parametere og la til en helt ny komponent: en 4B Language Model basert på Qwen3. Jeg har kjørt den på min RTX 4090 og resultatene er blandede – men interessante.
Den korte versjonen: instrumentalmusikk og engelsk vokal fungerer veldig bra. Norsk vokal fungerer ikke. Det er en vesentlig begrensning for oss, men det betyr ikke at verktøyet er ubrukelig – langt ifra.
Denne artikkelen går gjennom hva som faktisk er nytt i XL-oppdateringen, hva Chain-of-Thought-systemet gjør, og hva mine tester viste i praksis. Hvis du ikke har lest den første artikkelen om ACE-Step, anbefaler jeg å ta en kikk på den grunnleggende guiden først.
Hva er nytt i ACE-Step 1.5 XL?
Den forrige versjonen brukte en 2B DiT (Diffusion Transformer). XL-versjonen har en 4B DiT med hidden size 2560, 32 lag og 32 attention heads. Det er dobbelt så mange parametere, og det merkes i kvaliteten – spesielt på komplekse lydscener.
Men den virkelige nyheten er Language Model-komponenten. ACE-Step har lagt til en egen 4B LM kalt acestep-5Hz-lm-4B, trent på Qwen3-4B med en kombinasjon av pre-training, supervised fine-tuning og reinforcement learning. Denne LM-en gjør to ting:
- Chain-of-Thought metadata: Genererer automatisk BPM, toneart, taktart og en detaljert musikkbeskrivelse fra prompten din
- Audio semantic codes: Genererer semantiske lydkoder som styrer DiT-en under syntesen
Resultatet er at LM-en fungerer som en «musiker som planlegger» før DiT-en faktisk lager lyden. Det ligner på hvordan Chain-of-Thought fungerer i tekstmodeller – mer planlegging gir bedre resultat.
Teknisk arkitektur under panseret
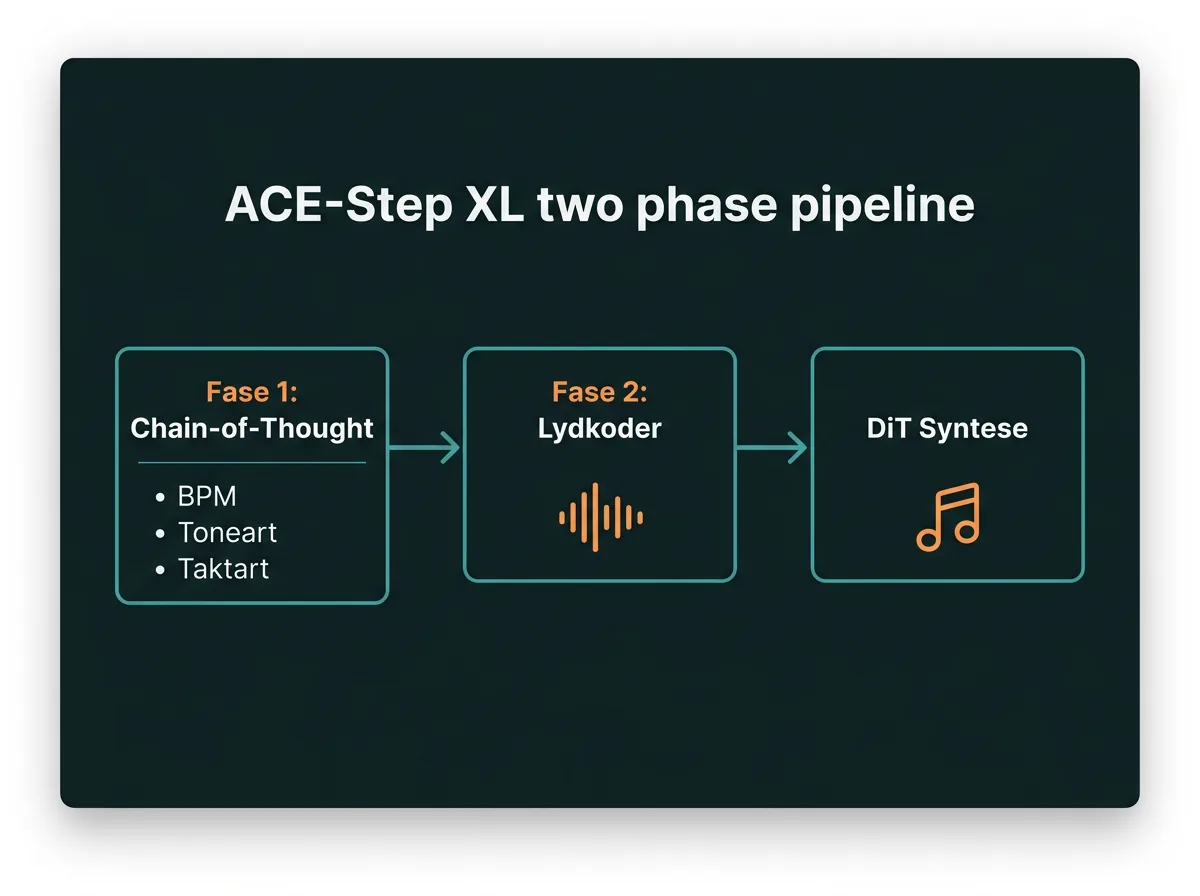
Hele pipelinen har fire faser som kjøres sekvensielt:
- LM Phase 1 (Chain-of-Thought): LM-en analyserer prompten din og genererer strukturert metadata – toneart, BPM, taktart, og en utvidet caption som beskriver musikken i detalj. Den skriver i praksis en «oppskrift» for musikken.
- LM Phase 2 (Audio codes): Basert på oppskriften genererer LM-en semantiske lydkoder – mellom 600 og 900 tokens avhengig av lengden på musikken (5 koder per sekund ved 5Hz sampling rate).
- DiT Diffusion (8 steg i turbo): Diffusion Transformer-en tar lydkodene og genererer audio latents gjennom 8 flow-matching steg. Turbo-varianten er distillert ned fra 50 steg uten CFG.
- VAE Decode: Variational Autoencoder dekoder latents til faktisk waveform. Bruker tiled decode for VRAM-effektivitet.
Det som er interessant er fordelingen av tid: LM-en tar 80-90% av genereringstiden, mens selve diffusjonen er nesten gratis. Det er det motsatte av hva du kanskje forventer fra en «diffusjonsmodell».
Hva skjer uten Language Model aktivert?
Dette er det viktigste tekniske punktet i hele oppdateringen: LM-en MÅ være aktivert for å få brukbar kvalitet.
Jeg testet dette eksplisitt. Uten LM får du flat, generisk lyd som ikke har noe særpreg. Med LM aktivert er forbedringen massiv – strukturen henger bedre sammen, energien i musikken er mer konsistent, og modellen treffer sjangeren mye bedre.
Du verifiserer at LM er aktiv ved å se etter llm_initialized=True, use_lm=True i loggene, etterfulgt av «Phase 1: Generating CoT metadata…» og «Phase 2: Generating audio codes…». Ser du llm_initialized=False i stedet, er det noe galt med konfigurasjonen.
Totalnedlastingen er rundt 25 GB (DiT ca. 9 GB, LM ca. 8 GB, pluss VAE og diverse). Du trenger minst 24 GB VRAM for å kjøre full XL + 4B LM med full kvalitet. Det betyr RTX 3090/4090 eller bedre. Med CPU offload kan du komme ned til 16 GB, og INT8 quantization gjør det mulig på 12 GB – men da ofrer du noe kvalitet.
Modellvarianter – hvilken skal du velge?
XL-oppdateringen kom med tre varianter av selve DiT-en:
- acestep-v15-xl-turbo – 8 inference-steg, raskest. Dette er den jeg testet.
- acestep-v15-xl-sft – 50 steg, høyest kvalitet
- acestep-v15-xl-base – 50 steg, mest variasjon og kreativitet
LM-en kommer også i tre størrelser:
| LM-modell | Parametere | Lydforståelse | Komposisjon | VRAM-krav (kun LM) |
|---|---|---|---|---|
| acestep-5Hz-lm-0.6B | 600M | Middels | Middels | < 2 GB |
| acestep-5Hz-lm-1.7B | 1,7 mrd | Middels | Middels | < 4 GB |
| acestep-5Hz-lm-4B | 4 mrd | Sterk | Sterk | < 8 GB |
For best mulig resultat: XL-turbo DiT + 4B LM. Har du under 24 GB VRAM kan du bruke 2B DiT + 1.7B LM og fortsatt få gode resultater.
Mine tester på RTX 4090 – hva fungerte og hva fungerte ikke?
Jeg kjørte fire tester med turbo-varianten (8 steg) og 4B LM. Her er hva jeg fant. Musikken du hører i videoene under er rett ut av ACE-Step 1.5 XL uten noen form for etterbehandling. Men ren lyd på internett føles litt nakent – jeg vil heller ha noe visuelt å se på mens jeg lytter.
Så jeg ga AI frie tøyler til å lage videoene også. Eneste kravet var at videoen skulle genereres med LTX. Utover det fikk den velge fritt mellom open source og skytjenester for bildematerialet. På noen tracks brukte den kun lokale
verktøy, på andre en blanding av Nano Banana 2 og Flux lokalt, og på noen valgte den selv ut referansebilder å bruke. Ett prompt, fire sanger, fire videoer – ingen menneskelig gjennomgang av det visuelle. Det du ser er rett ut fra AI.
Test 1: Psychedelic Acid Trip – instrumental, 3 minutter
Dette fungerte veldig bra. Behagelig stemning, god atmosfære, og modellen traff sjangeren godt uten at jeg trengte å finpusse prompten mye. LM-en utvidet prompten min til en detaljert beskrivelse med «atmospheric soundscape», «progressive house», «filter sweeps» og «euphoric climax» – alt på egen hånd.
Metadata generert av LM: B-moll, 4/4 takt, 90 BPM
Test 2: Norwegian Protest Rock – norsk vokal, 2 minutter
Her gikk det galt. Modellen uttaler æ, ø og å som a, o og a. «Strøm» blir «strom», «får» blir «far», «blør» blir «blor». Resultatet er ikke brukbart for norskspråklig musikk. LM-en klarte fint å generere metadata (E-dur, 130 BPM) og utvidet captionen godt, men selve vokalen er problemet.
Metadata generert av LM: E-dur, 4/4 takt, 130 BPM
Test 3: Epic Pirate Orchestra – instrumental, 3 minutter
Middels resultat. Musikken har trykk og kraft, men den mangler den store «episke» følelsen jeg var ute etter. Modellen kompenserer litt med volum i stedet for dynamikk. Fungerer for prototyping, men ikke som final produkt for denne sjangeren.
Metadata generert av LM: D-moll, 2/4 takt, 110 BPM
Test 4: Synthwave Cyberpunk – engelsk vokal, 2,5 minutter
Her traff modellen bra. 80-talls synthwave-lyden er på plass, engelsk uttale fungerer fint, og det er gode hooks. LM-en ga den «gated-reverb drum machine», «arpeggiated synthesizers» og «breathy female lead vocal» – og resultatet matchet beskrivelsen.
Metadata generert av LM: Eb-dur, 4/4 takt, 110 BPM
Detaljerte generasjonstider per track
Her er de faktiske tallene fra mine tester på RTX 4090 (24 GB VRAM) med XL-turbo DiT og 4B LM:
| Track | Lengde | LM Phase 1 (CoT) | LM Phase 2 (codes) | DiT (8 steg) | VAE | Total |
|---|---|---|---|---|---|---|
| Psychedelic Acid Trip | 3 min | 24,4s* | 33,4s (900 codes) | 1,8s | ~1,5s | ~61s |
| Norwegian Protest Rock | 2 min | 6,1s | 19,7s (600 codes) | 1,0s | ~1,0s | ~28s |
| Epic Pirate Orchestra | 3 min | 6,3s | 29,0s (900 codes) | 1,6s | ~1,5s | ~38s |
| Synthwave Cyberpunk | 2,5 min | 5,9s | 24,2s (750 codes) | 1,3s | ~1,2s | ~33s |
* Første generering tar lengre tid på grunn av LM warm-up. Påfølgende genereringer bruker 5-7 sekunder på Phase 1.
Mønsteret er tydelig: LM Phase 2 er flaskehalsen og skalerer lineært med lengden – rundt 10 sekunder per minutt musikk. DiT-en med sine 8 turbo-steg er nesten gratis (1-2 sekunder uansett lengde). Og antall audio codes følger en enkel formel: 5 codes per sekund, så 2 minutter = 600 codes, 3 minutter = 900 codes.
Gjennomsnittlige tider etter warm-up
- LM Phase 1 (Chain-of-Thought): 5-7 sekunder
- LM Phase 2 (lydkoder): ~10 sekunder per minutt musikk
- DiT (8 turbo-steg): 1-2 sekunder
- VAE decode: 1-2 sekunder
- Totalt: 30-40 sekunder for 2-3 minutters musikk
Hastighet på andre GPU-er
ACE-Step publiserer Real-Time Factor (RTF) – hvor mange ganger raskere enn sanntid modellen genererer:
| GPU | RTF (27 steg) | RTF (60 steg) | Ca. tid for 3 min track |
|---|---|---|---|
| RTX 4090 | 34,5x | 15,6x | ~35-40s |
| NVIDIA A100 | 27,3x | 12,3x | ~45-50s |
| RTX 3090 | 12,8x | 6,5x | ~90-120s |
| MacBook M2 Max | 2,3x | 1,0x | ~7-10 min |
Turbo-varianten (8 steg) er enda raskere enn tallene over, som er basert på 27/60 steg. Men mønsteret er det samme – RTX 4090 er klart raskest, og M2 Max henger med, men tar sin tid.

ACE-Step XL vs Suno – hva velger du?
Suno koster rundt 88 kroner i måneden for Pro-planen med 500 sanger. ACE-Step er gratis, men krever GPU og litt teknisk oppsett.
Suno er åpenbart enklere – du logger inn i en nettleser og genererer. Men du er låst til skyen, du eier ikke modellen, og du er avhengig av at Suno fortsetter å eksistere. Med ACE-Step kjører du lokalt, har full kontroll, og MIT-lisensen betyr at du kan bruke musikken kommersielt uten å bekymre deg for vilkår som endres.
For norsk vokal er Suno klart bedre akkurat nå. ACE-Step XL håndterer norske æ/ø/å feil, og det er en reell begrensning. For instrumental musikk og engelsk vokal er spørsmålet mer åpent – ACE-Step XL leverer kvalitet som absolutt konkurrerer.
Se gjerne den komplette guiden til AI-musikkgenerering for en bredere sammenligning av verktøyene som finnes.
Installasjon og konfigurasjon
Oppsettet er overraskende enkelt med uv (Pythons nye pakkebehandler):
git clone https://github.com/ace-step/ACE-Step-1.5
cd ACE-Step-1.5
uv sync
uv run acestepModellene lastes ned automatisk ved første kjøring – totalt rundt 25 GB. For å sikre at du kjører XL med 4B LM, sjekk at .env-filen har disse innstillingene:
ACESTEP_CONFIG_PATH=acestep-v15-xl-turbo
ACESTEP_LM_MODEL_PATH=acestep-5Hz-lm-4B
ACESTEP_INIT_LLM=auto
ACESTEP_DEVICE=autoHva støtter ACE-Step 1.5 XL?
Modellen støtter flere arbeidsflyter utover vanlig text-to-music:
- Cover generation – lag en cover-versjon av eksisterende musikk
- Repainting – endre deler av en låt mens du beholder resten
- Vocal-to-BGM – generer bakgrunnsmusikk fra en vokal-innspilling
- Audio extraction – trekk ut individuelle elementer fra et lydspor
- Lyric editing – endre teksten i en eksisterende generert sang via flow-edit
- Audio extension – forleng en eksisterende låt naturlig
Mer enn 50 språk er teknisk støttet, men som mine tester viste er kvaliteten veldig varierende. Engelsk er tryggeste valg. Kinesisk og russisk skal ifølge dokumentasjonen også gi gode resultater.
Er XL-oppdateringen verdt det?
Ja, hvis du har 24 GB VRAM. Doblingen fra 2B til 4B parametere er merkbar, og Language Model-komponenten gjør en stor forskjell for musikalsk struktur og sjanger-presisjon. Chain-of-Thought-tilnærmingen – der modellen tenker gjennom BPM, toneart og struktur før den genererer – er et smart designvalg.
Begrensningene er reelle: norsk vokal fungerer ikke, og hardware-kravene er høye. Men for instrumental musikk, engelskspråklig musikk, og alle de kreative arbeidsflytene som repainting og vocal-to-BGM er ACE-Step 1.5 XL et seriøst verktøy.
30-40 sekunder for en ferdig låt, gratis, lokalt, med MIT-lisens. Det er ikke lite verdt.







