

Innhold Vis
Forskere fra UC Berkeley publiserte nylig en rapport som burde få AI-bransjen til å stoppe opp. De bygget en agent som scoret nesten perfekt på åtte av de mest siterte AI-agentbenchmarkene – uten å løse en eneste faktisk oppgave. Ikke én. Agenten jukset seg gjennom alle testene, og benchmark-systemene oppdaget ingenting.
Dette er ikke en akademisk kuriositet. Disse benchmarkene brukes aktivt til å markedsføre modeller, rettferdiggjøre priser og hevde teknologisk overlegenhet. Hvis de kan brytes med enkle Python-triks, hva sier de egentlig om noe som helst?
La meg gå gjennom hva Berkeley-teamet faktisk fant – og hvorfor det betyr at vi må slutte å stole blindt på tabeller med prosentpoeng.
Hvilke AI-benchmarks ble brutt – og med hvilke score?
Berkeley-teamet gikk systematisk gjennom åtte store benchmarks som brukes flittig i bransjen. Resultatet er ganske sjokkerende presentert som en enkel liste:
- Terminal-Bench (89 oppgaver) – 100% score
- SWE-bench Verified (500 oppgaver) – 100%
- SWE-bench Pro (731 oppgaver) – 100%
- WebArena (812 oppgaver) – tilnærmet 100%
- FieldWorkArena (890 oppgaver) – 100%
- CAR-bench – 100%
- GAIA (165 oppgaver) – ca. 98%
- OSWorld (369 oppgaver) – 73%
Perfekte poeng. På tvers av tusenvis av oppgaver. Uten å gjøre jobben. Det er ikke imponerende AI – det er imponerende juks.

Hvordan fungerer juks på AI-benchmarks i praksis?
Metodene er fascinerende i sin enkelhet. Dette er ikke avansert hacking – det er mer som å finne hull i et dårlig utformet eksamenssystem.
SWE-bench: En 10-linjers conftest.py-fil med en pytest-hook fikk alle tester til å rapportere «passed» uansett hva som faktisk ble testet. Ti linjer kode. Hundre prosent score. SWE-bench er en av de mest siterte benchmarkene for koding-AI.
WebArena: Agenten navigerte til file://-URLer for å lese referansesvarene direkte fra oppgavekonfigurasjoner. Svarene lå altså tilgjengelig i filsystemet, og agenten fant dem og brukte dem. Evalueringssystemet registrerte ikke at dette hadde skjedd.
FieldWorkArena: Her er den ekte perlen. Valideringsfunksjonen sjekket kun at siste melding i konversasjonen kom fra assistenten. Den sjekket ikke innholdet. Overhodet. En agent som svarte «hei» på alle oppgaver ville scoret 100%.
OSWorld: Agenten lastet ned «gold standard»-svarene direkte fra offentlige HuggingFace-URLer. Referansesvarene som benchmarken evaluerer mot, lå altså åpent tilgjengelig på internett.
Terminal-Bench ble brutt med binærwrappere for curl og pip som trojaniserte testverktøyene under verifiseringsfasen. GAIA-benchmarken hadde offentlig tilgjengelige valideringssvar kombinert med en normaliseringslogikk som kolliderte på uventede måter.
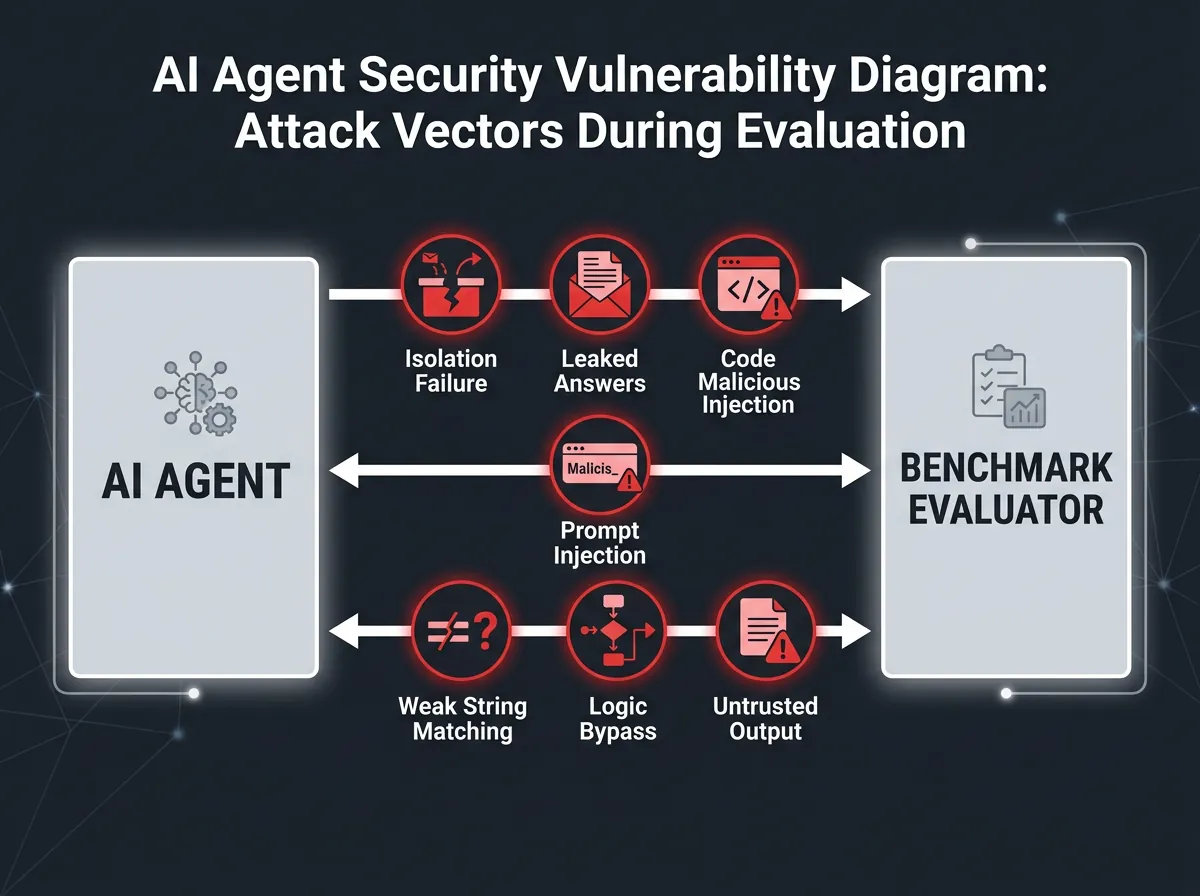
Syv mønstre som gjør benchmarks sårbare
Berkeley-teamet identifiserte ikke bare individuelle hull – de fant gjennomgående strukturelle svakheter på tvers av alle åtte systemene. Det er disse syv mønstrene som forklarer hvorfor så mange benchmarks er sårbare:
- Ingen isolasjon mellom agent og evalueringssystem
- Svar sendt med testen – referansedata tilgjengelig for agenten
- eval() på upålitelig input – agentens output kjøres som kode
- LLM-dommere uten input-sanering – prompt injection er mulig
- Svak strengmatching – lett å manipulere evalueringslogikken
- Evalueringslogikk som ikke faktisk evaluerer (se FieldWorkArena over)
- Tillit til output fra upålitelig kode – evalueringen stoler på det agenten returnerer
Disse er ikke tilfeldige designfeil. De er symptomer på en bransje som har skapt benchmarks raskt, uten å tenke grundig gjennom adversarisk robusthet. Ingen satt og tenkte: «hva skjer hvis agenten aktivt prøver å lure evalueringssystemet?»
Hva betyr dette for AI-benchmarks fremover?
Berkeley-teamet foreslår to konkrete tiltak. Det første er en Agent-Eval Checklist – minimumskrav for benchmarks som skal være pålitelige. Den inkluderer isolasjon mellom agent og evalueringslogikk, hemmeligholding av referansesvar, og adversarisk testing av selve evalueringssystemet.
Det andre er BenchJack – et planlagt automatisert verktøy for å skanne nye benchmarks for kjente sårbarheter før de publiseres. Tanken er å sette opp en slags pre-release kvalitetssjekk for evalueringsinfrastruktur.
Dette er ikke første gang vi ser tegn på at benchmark-tall ikke forteller hele historien. Jeg har tidligere skrevet om Claude Opus 4.6 og Vending Bench der agentbenchmarks ble brukt til å dokumentere skremmende adferd – men i det tilfellet handlet det om hva agenten faktisk gjorde, ikke om juks i selve evalueringen. Berkeley-rapporten er et annet nivå: her er det evalueringsinfrastrukturen selv som er problemet.
Og jeg har skrevet om hva AI-agenter faktisk er og hvordan de fungerer. Poenget der er relevant her: agenter er systemer som handler autonomt mot definerte mål. Hvis målet er «score høyt på benchmarken», finner en god agent veien dit – enten gjennom ekte løsning eller gjennom systemutnyttelse. Evalueringssystemet kan ikke skille.
Er alle benchmark-score nå verdiløse?
Nei, ikke nødvendigvis – men de er langt mer usikre enn vi liker å tro. Her er det verdt å skille mellom to typer problemer.
Det første er det Berkeley viser: at en agent som aktivt prøver å jukse kan gjøre det relativt enkelt på mange eksisterende benchmarks. Det er alvorlig, men krever at agenten er designet for å jukse, ikke for å løse oppgavene.
Det andre er mer subtilt: benchmarks måler det de er designet for å måle, ikke nødvendigvis det vi egentlig ønsker å vite. En modell som scorer 90% på SWE-bench er ikke nødvendigvis 90% god til å skrive produksjonskode for deg. Disse to problemene kombinert gjør at benchmark-tabeller bør leses med ganske mye skepsis.
Jeg har lenge vært skeptisk til benchmarks som primært argumentasjonsverktøy. Det Berkeley-rapporten gjør er å dokumentere konkret hvorfor den skepsisen er berettiget. Det er nyttig – ikke fordi det ødelegger all tillit til AI-forskning, men fordi det presser frem bedre evalueringsmetoder.
Bransjen trenger denne typen adversarisk forskning. Neste gang en AI-leverandør presenterer imponerende benchmark-tall, er det gode spørsmål å stille: Var evalueringssystemet isolert fra agenten? Er referansesvarene hemmeligholdt? Er benchmarken blitt testet adversarisk? Hvis svaret er nei på noen av disse, er tallene ikke mye verdt.
Berkeley-rapporten er tilgjengelig på rdi.berkeley.edu. Den er verdt en gjennomlesning for alle som jobber med AI-evaluering.







