

Innhold Vis
torch-nvenc-compress er et Python-bibliotek som bruker GPUens videokompresjonssilikon – NVENC/NVDEC – til å komprimere nevralt nettverks mellomtilstander og KV-cache, slik at de kan sendes raskere over PCIe-bussen og ethernet. Resultatet er effektiv båndbredde på opptil 6 ganger det fysiske maksimum. Biblioteket er Apache 2.0, tilgjengelig på GitHub.
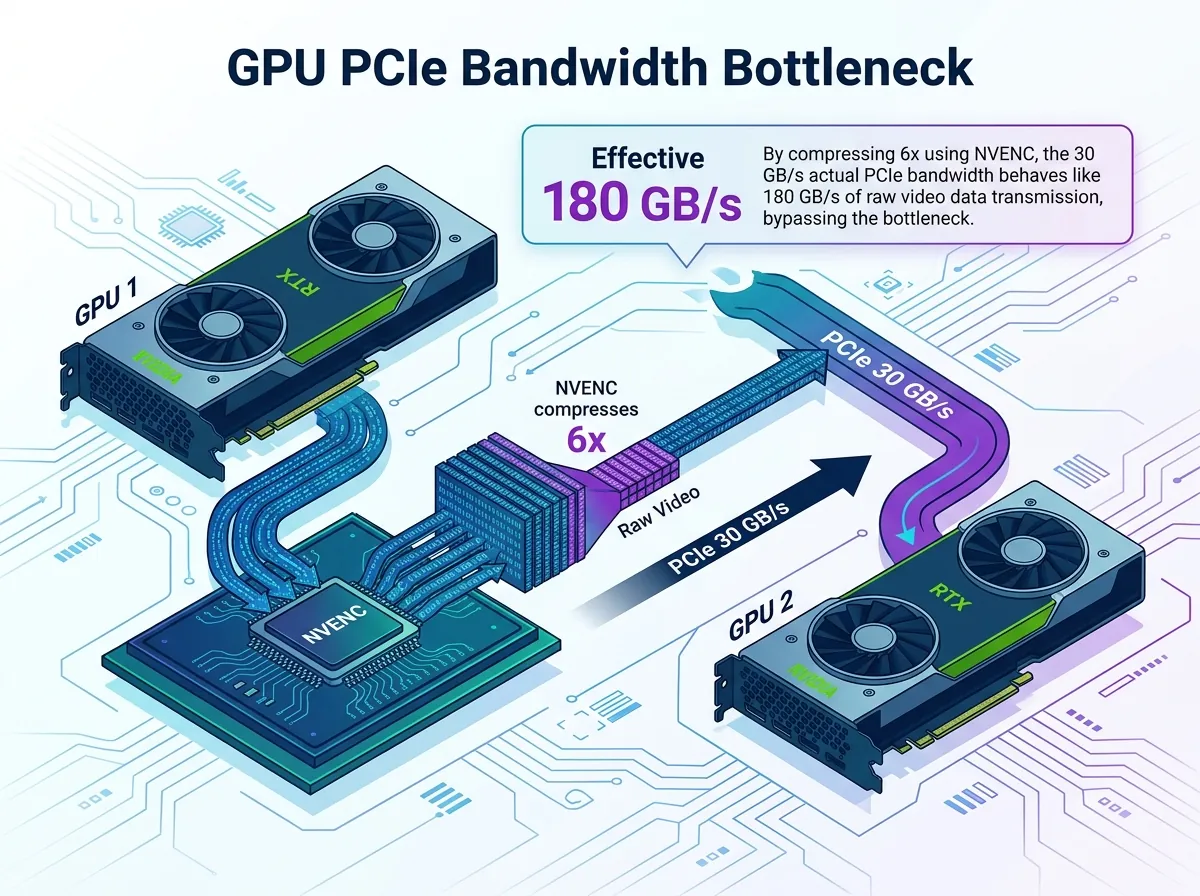
NVIDIA fjernet NVLink fra RTX 4090 og 5090. Det betyr at de som vil kjøre store modeller på to forbrukerkort – si en 70B-modell som ikke passer på ett enkelt kort – er henvist til PCIe peer-to-peer, som leverer rundt 30 GB/s. Det er ikke akkurat raskere enn noen huker data med begge hender fra det ene kortet til det andre.
torch-nvenc-compress angriper dette problemet fra en annen vinkel: i stedet for å vente på at NVIDIA skal gi tilbake NVLink, brukes videoenkoderen som allerede sitter på GPUen til å komprimere dataene før de krysser bussen. Effektivt båndbredde på 30 GB/s × 6× komprimering = 180 GB/s. Det er faktisk noe å snakke om.
Hva er egentlig PCIe-flaskehalsen for multi-GPU?
Når du kjører en stor språkmodell på to GPU-er, er ett av de største problemene at lagene i modellen hele tiden sender aktiveringstensorer mellom kortene. PCIe 4.0 x16 gir omtrent 32 GB/s i begge retninger, men peer-to-peer-trafikk mellom to forbrukerkort treffer gjerne 25-30 GB/s i praksis. Det er ganske bra som databuss – men ikke imponerende sammenlignet med HBM-minne på GPU-er som kjører 900+ GB/s.
Modeller i 70B-klassen krever 140+ GB for full presisjon, og selv i 4-bit kvantisert form (~35 GB) trenger du to kort. NVLink løste dette for workstation-kort (RTX 4000 Ada og oppover) med 112 GB/s, men forbrukerkortene fikk ikke med seg den festen. Noen mente det var et kommersielt valg fra NVIDIAs side. Andre mente det bare var et plass- og strømproblem. Uansett: resultatet er det samme – du sitter med PCIe.
Det er her torch-nvenc-compress kommer inn.
Hvordan bruker biblioteket NVENC-silikon?
NVENC er videokodingsbrikken som sitter på alle moderne NVIDIA-kort. Den brukes normalt til OBS, Shadowplay og videoeksport. Under LLM-inferens er den i praksis helt uvirksom.
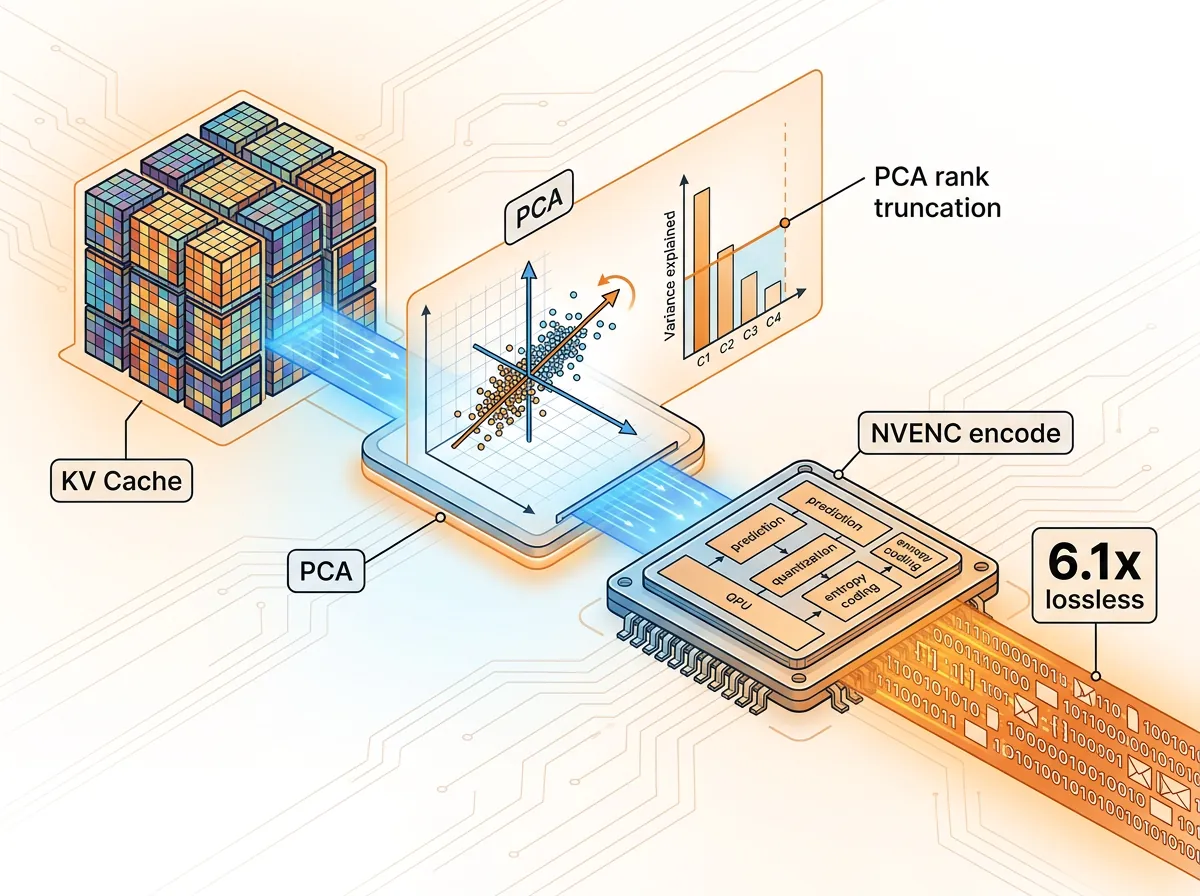
Biblioteket bruker denne brikken til å komprimere aktiveringstensorer og KV-cache ved hjelp av videokodeker – H.264 eller HEVC – som er designet for å komprimere store mengder romlig korrelerte data raskt. Det er ikke helt åpenbart at dette fungerer på nevralnettverksdata, men utvikleren bruker et smart forbehandlingssteg: PCA-dekomposisjon (Principal Component Analysis) med rankstubling for å sortere dataene slik at videokodekene kan utnytte romlig struktur på en fornuftig måte.
Resultatet er imponerende:
- Diffusjons-midblokk-aktiveringer: 6,1× lossless komprimering (cosinuslikhet over 0,99)
- LLM KV-cache: 2,7× lossless komprimering
Det kritiske spørsmålet er om komprimeringen koster mer tid enn den sparer i overføring. Svaret er nei – og det er fordi NVENC og PCIe er uavhengige hardware-stier. Mens PCIe sender de komprimerte dataene, kan NVENC allerede kode neste batch. Parallellisering gir 67% av teoretisk maksimum i målte GEMM + encode-arbeidsbelastninger.
Hva er de målte ytelsestallene?
Biblioteket bruker en komponent kalt MultiEngineDirectBackend – et sett med rene ctypes-bindinger mot NVIDIA Video Codec SDK DLL-ene, uten Python-overhead i den kritiske stien:
- 0,180 ms/frame koding
- 0,262 ms/frame dekoding
- 2,83× raskere enn PyAV CodecSession på ekte FLUX-aktiveringer
- RTX 5090 bruker 3 parallelle NVENC-motorer for å øke gjennomstrømning
Effektivt båndbredde på RTX 5090: naturen gir deg ~30 GB/s over PCIe. Med 6× komprimering får du tilsvarende ~180 GB/s. Det er ikke NVLink, men det er seks ganger bedre enn ingenting.
Det er også verdt å merke seg at biblioteket er testet på mer enn bare GPU-til-GPU. Over gigabit ethernet ser de 6× speedup. Over 100 Mbps hjemme-internett: 3,13× målt wall-clock-forbedring. Det åpner for distribuert inferens der nodenes flaskehalser er nettverksbåndbredde.
Er dette virkelig lossless?
Dette er det naturlige spørsmålet. Videokodeker er jo vanligvis tapende. Men her bruker de lossless-modi (HEVC lossless eller H.264 lossless) kombinert med PCA-forbehandling som beholder full informasjon innenfor den trunkerte rangen. LOO-validering (leave-one-out) bekrefter cosinuslikhet over 0,99 for de komprimerte representasjonene.
Prosjektet er rundt 75% validert per nå: komprimeringsforhold og parallell-bane-overlapping er bekreftet. Multi-GPU peer-to-peer PCIe-integrasjonen venter fortsatt på at utvikleren skal skaffe et andre kort for å teste ende-til-ende.
Hva kreves for å komme i gang?
Kravene er:
- NVIDIA GPU med NVENC-støtte (RTX-serien fra Turing/Ampere og nyere)
- Windows (bruker NVIDIA Video Codec SDK DLL-er direkte via ctypes)
- PyTorch med CUDA
Installasjon er rett fram:
git clone https://github.com/shootthesound/torch-nvenc-compress
pip install -e ".[all]"
python scripts/check_environment.pyBiblioteket er Apache 2.0-lisensiert og kan brukes fritt i kommersielle prosjekter.
Hva betyr dette for lokale multi-GPU-oppsett?
Det er ikke som om du plutselig kan kjøre Llama 3 405B på to RTX 4090-er med NVLink-hastighet. Men 180 GB/s effektivt mot 30 GB/s ekte er en vesentlig forskjell for pipeline-parallellisme. Det er riktignok fortsatt PCIe-latens å forholde seg til – videokoding tar noen millisekunder – men arkitekturen er designet for å skjule den latensen bak eksisterende beregning.
Interessant er det at dette ikke bare er et GPU-til-GPU-problem. Det samme prinsippet – komprimer dataene, send dem raskere – gjelder for distribuert inferens over nettverk. Å kjøre deler av en stor modell på forskjellige maskiner hjemme, og la NVENC håndtere komprimering mellom nodene, er faktisk ikke urealistisk lenger. Jeg har tidligere skrevet om hardware-valg for lokal LLM-inferens og lokal inferens med RTX 5090 – dette er neste naturlige steg for de som vil presse mer ut av det de allerede har.
Jeg synes det er genialt at noen fant på å bruke et stykke hardware som sitter helt uvirksom under 99% av LLM-inferens til nettopp dette. Det er den typen kreativ bruk av eksisterende ressurser som faktisk løser et reelt problem i stedet for å vente på at NVIDIA skal løse det for deg.
Har du prøvd multi-GPU-oppsett for lokale modeller? Gjerne del erfaringer i kommentarfeltet – særlig hvis noen har testet med to 4090-er og faktisk kjørt 70B-modeller ende-til-ende.







