

Innhold Vis
NemoClaw er NVIDIAs sikkerhetsstabel for OpenClaw-agenter, lansert på GTC 2026. Sandboxen er designet for enterprise-bruk med streng nettverksisolasjon – som standard forventer den cloud API-tilkoblinger og blokkerer lokale nettverkskall. En utvikler på r/LocalLLaMA bestemte seg for å omgå akkurat det, og kjøre hele agenten lokalt på WSL2 med RTX 5090.
Resultatet er interessant av to grunner. For det første viser det at NemoClaws sandbox-isolasjon ikke er ugjennomtrengelig – den er konfigurert for enterprise-tillit, ikke sikkerhetsforskning. For det andre dokumenterer det en konkret teknikk for å koble NemoClaw til en lokal vLLM-instans, noe som NVIDIA selv har merket som eksperimentelt og gjemt bak en miljøvariabel.
Jeg har skrevet om NemoClaw siden GTC-lanseringen og fulgt med på hva som skjer i LocalLLaMA-miljøet rundt denne plattformen. Her er hva som faktisk skjedde.
Hva er NemoClaws sandbox, og hvorfor blokkerer den lokal inferens?
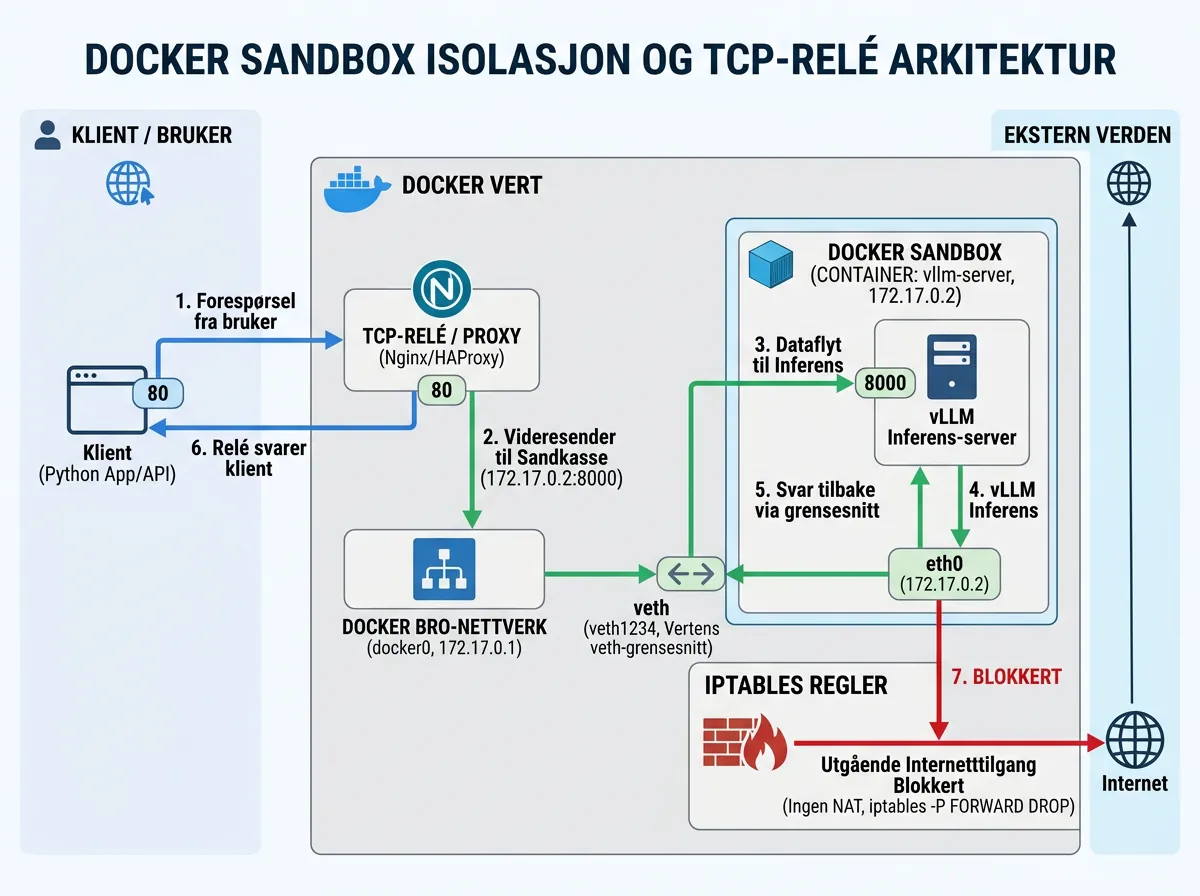
NemoClaw bruker OpenShell-runtimen, som kjører k3s (lett Kubernetes) inni Docker. Rundt agentprosessen er det tre lag med isolasjon: Landlock for filsystem-tilgang, seccomp for syscall-filtrering, og nettverksnamnrom (network namespaces) for nettverksisolasjon.
Nettverkspolitikken er whitelist-basert. Agenten kan kun nå endepunkter som er eksplisitt listet i openclaw-sandbox.yaml. Alt annet blokkeres, og operatøren får spørsmål om godkjenning. I praksis betyr det at en lokal vLLM-instans på localhost:8000 er utilgjengelig fra sandboxen – den er ikke på whitelisten, og trafikk fra sandbox-nettverkets veth-interface når aldri Docker-broen mot vertsmaskinen.
NVIDIA har eksperimentell støtte for lokal inferens (vLLM, Ollama, NIM) bak en miljøvariabel NEMOCLAW_EXPERIMENTAL=1, men selv med den satt er routing gjennom WSL2s nettverksstabel ikke rett frem. WSL2 har sitt eget nettverksnamnrom mellom Windows-verten og Linux-laget, og NemoClaws k3s-pods sitter enda et lag dypere.
Hvordan ble sandbox-isolasjonen omgått?
Teknikken som ble brukt kombinerer to grep: iptables-regler på vertsmaskinen og en TCP-relay inni poddens hoved-nettverksnamnrom.
Det første steget var å åpne trafikk fra Docker-broen til vLLM-porten. Docker-broen (typisk 172.17.0.0/16-nettverket) er isolert fra vertens loopback-grensesnitt som standard. En iptables-regel ble lagt til for å tillate trafikk fra Docker-bro-nettverket til port 8000 der vLLM kjørte.
Det andre steget var trickier. Sandboxens veth-interface (virtuell Ethernet-par mellom pod og host) er i et annet namnrom enn Docker-broen. Løsningen var en tilpasset Python-relay som kjørte i poddens hoved-namnrom – ikke inne i sandboxen, men i det omkringliggende k3s-podlaget. Relayen bro-koblet sandbox veth-trafikk mot Docker-bro-nettverket, som igjen nådde vLLM gjennom iptables-regelen.
Resultatet: agenten tror den snakker med et sky-API, men trafikken går lokalt gjennom relay-kjeden og ender opp hos Nemotron 9B som kjører på RTX 5090 via vLLM.
Nemotron 9B med tool calling – hva kan den egentlig?
Modellen som ble brukt er Nemotron 9B – en av de mindre modellene i Nemotron 3-familien. NVIDIA har Nemotron 3 Nano (4B), Super (120B MoE) og Ultra i familien, men 9B er et sweet spot for lokal kjøring: kraftig nok for tool calling, liten nok til å kjøre effektivt på én GPU.
RTX 5090 har 32 GB GDDR7-minne, som gir romslig plass til Nemotron 9B med full presisjon eller kvantisert. vLLM utnytter NVIDIAs CUDA-stack effektivt og gir betydelig høyere token-gjennomstrømning enn Ollama på samme hardware.
Tool calling-støtten i Nemotron 9B er viktig for NemoClaw-konteksten. OpenClaw-agenter bruker tool calling aktivt – filoperasjoner, nettverksforespørsler, spawning av sub-agenter. En modell som ikke håndterer dette riktig vil gi en agent som sporadisk feiler på verktøybruk, noe som er verre enn ingen agent i det hele tatt.
Er dette en sårbarhet, eller bare konfigurasjon?
Verdt å merke seg: dette er ikke et sikkerhetshull i klassisk forstand. For å gjennomføre dette trengte utvikleren root-tilgang til vertsmaskinen (for iptables-reglene) og muligheten til å kjøre prosesser i poddens hoved-namnrom. Det er ikke noe en ondsinnet agent inne i sandboxen kan gjøre på egenhånd.
NemoClaws sandbox er designet for å beskytte vertsmaskinen mot agenten, ikke for å beskytte agenten mot operatøren. Det er en rimelig designbeslutning for enterprise-bruk – en systemadministrator skal selvfølgelig kunne konfigurere nettverkstilgang. Det Reddit-posten egentlig demonstrerer er at NemoClaws nettverkspolitikk er operatørkonfigurerbar, og at lokal inferens er teknisk mulig selv om det krever innsats.
NVIDIA har allerede åpnet for dette via NEMOCLAW_EXPERIMENTAL=1, men mellomleddet med WSL2-nettverksstabelen er udokumentert. Det er det denne teknikken faktisk løser.
RTX 5090 for lokal agent-kjøring – gir det mening?
RTX 5090 er det sterkeste forbruker-GPU-et NVIDIA har laget, med 32 GB GDDR7 og Blackwell-arkitektur. For lokal LLM-kjøring er den overkvalifisert til de fleste formål – en RTX 4090 med 24 GB er allerede svært kapabel. Men for NemoClaw-agenter med tool calling er minnekapasiteten viktig, spesielt hvis man ønsker å kjøre større modeller som Nemotron 3 Super (120B MoE) lokalt, noe som ville kreve flere GPUer.
Nemotron 9B på RTX 5090 er derimot en behagelig kombinasjon. Modellen passer godt innenfor minnet, inferensen er rask, og du slipper de flaskehalser som oppstår når modellen grenser mot tilgjengelig VRAM.

Hva betyr dette for deg som vil kjøre NemoClaw lokalt?
Hvis du har en moderne NVIDIA GPU og vil bruke NemoClaw uten sky-avhengighet, er det faktisk mulig – om enn med manuell konfigurasjon. Stegene i grove trekk:
- Sett opp vLLM med en Nemotron-modell (9B er et godt startpunkt for de fleste)
- Konfigurer iptables for å tillate Docker-bro-trafikk til vLLM-porten
- Sett opp en TCP-relay i poddens hoved-namnrom for å bro-koble sandbox-veth mot Docker-broen
- Start NemoClaw med
NEMOCLAW_EXPERIMENTAL=1og pek inference-endepunktet mot relayen
Det er mer kompleksitet enn å bare sette en miljøvariabel, men det er gjennomførbart for noen som er komfortabel med Docker-nettverk og Linux-nettverksstabling. NVIDIA kommer nok til å dokumentere og forenkle dette etter hvert som NemoClaw modnes fra alpha – det er tydelig at lokal inferens er noe de ønsker å støtte.
Jeg har skrevet om lokale agenter med Ollama og fordelen med å holde inferens lokalt tidligere. NemoClaw representerer et steg videre – det er ikke bare en lokal modell, det er en agent med verktøy og policy-basert sikkerhet som kan kjøre helt offline. Det er verdt litt konfigurasjonskompleksitet.







