

Innhold Vis
LLMSearchIndex er et open source Python-bibliotek som lar deg kjøre nettbasert søk helt lokalt – uten betalte API-er og uten å sende spørsmålene dine til noen tredjepart. Prosjektet, tilgjengelig på GitHub, inneholder over 203 millioner indekserte nettsider fra FineWeb og Wikipedia, pakket ned i en komprimert indeks som kjører på vanlig hardware.
For deg som bygger RAG-systemer (Retrieval-Augmented Generation) med lokale språkmodeller via Ollama eller lignende, er dette interessant. Det vanlige problemet er at «lokal AI» stopper å være lokal så snart modellen trenger å søke på nettet. Da er du plutselig avhengig av Brave Search API ($3/1 000 spørsmål), SearXNG med skraping som feiler uforutsigbart, eller Googles Custom Search-API med tilhørende prislapp. LLMSearchIndex prøver å løse akkurat det problemet.
Her er hva biblioteket faktisk gjør, hvordan det fungerer teknisk, og hva du bør tenke på før du tar det i bruk.
Hva er LLMSearchIndex?
Kjernen i prosjektet er en fortrenet, kraftig komprimert søkeindeks som inneholder det meste av innholdet fra to store datasett: FineWeb (HuggingFaces store webtekst-datasett) og Wikipedias fullstendige tekstinnhold. Til sammen er det over 203 millioner nettsider indeksert.
Det teknisk smarte er komprimeringen. Embeddings (de numeriske representasjonene av tekst som gjør semantisk søk mulig) er normalt sett svære greier. Her er de komprimert i tre steg: Sentence Transformers-modellen all-MiniLM-L6-v2 genererer opprinnelig 384-dimensjonale vektorer, PCA-komprimering kutter dem ned til 64 dimensjoner, og deretter binær kvantisering reduserer størrelsen ytterligere. Resultatet er en FAISS-indeks du kan søke i lokalt.
Installasjon er rett frem. Du trenger bare pip:
pip install llmsearchindex
Deretter er det tre linjer kode for å søke:
from llmsearchindex import LLMIndex
index = LLMIndex()
results = index.search("hvem er Elon Musk", top_k=5, rerank=True)
Det finnes to søkemodi: standard (raskest) og reranked der cosinus-likhet brukes til å score og sortere resultatene på nytt. Reranking gir bedre presisjon, men tar litt lengre tid.
Hva krever det av hardware?
Her er de faktiske systemkravene ifølge prosjektets dokumentasjon:
RAM: cirka 6 GB
Diskplass: cirka 10 GB
Prosessor: CPU støttes – GPU er valgfritt
De fleste moderne PC-er med 16 GB RAM og en vanlig SSD vil håndtere dette fint. Det er ikke krav om nVidia-kort eller spesialhardware. Det er i stor kontrast til å kjøre selve språkmodellene, som gjerne vil ha 8-24 GB VRAM for god ytelse.
Merk at indeksen hentes fra HuggingFace-servere første gang du kjører den – du trenger internett for nedlastingen, men selve søkingen skjer lokalt etterpå.
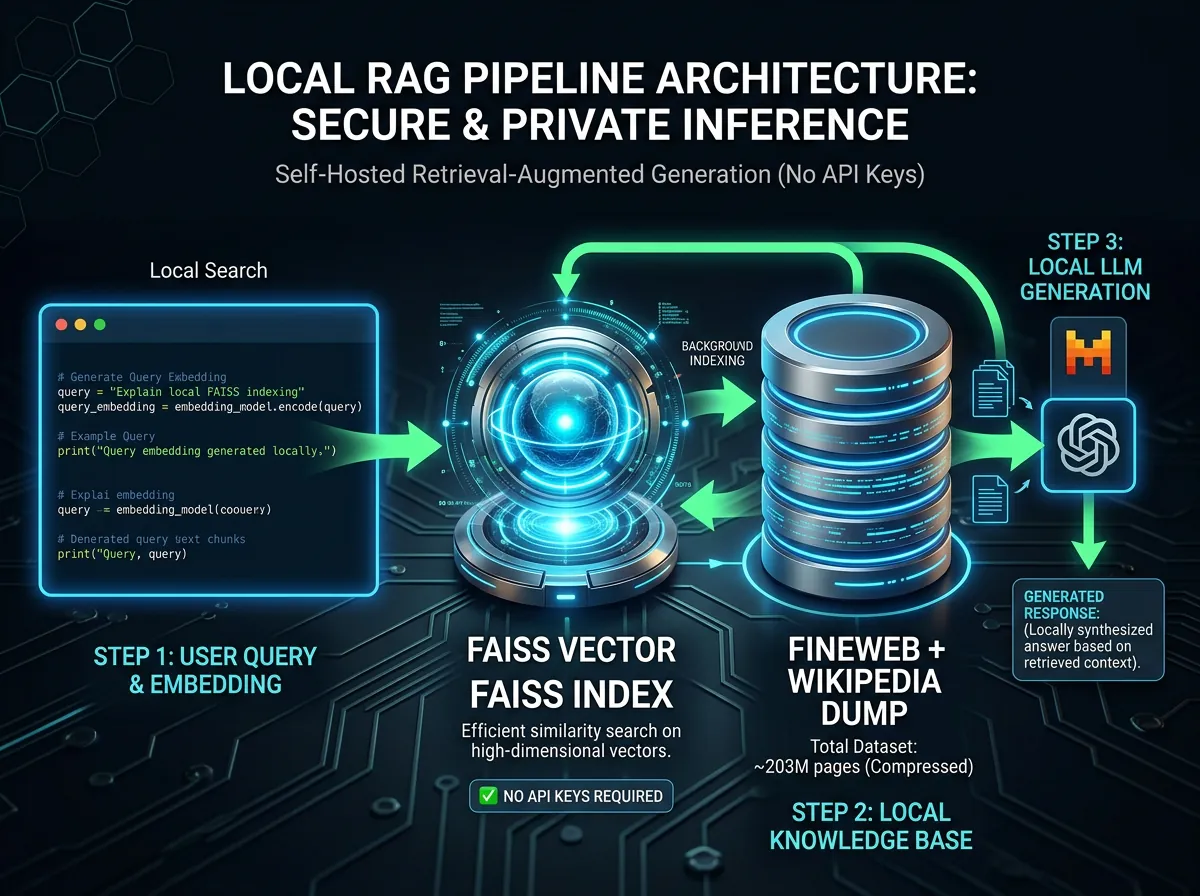
Hvorfor er dette relevant for lokal RAG?
RAG-pipelinen ser typisk slik ut: bruker stiller spørsmål – systemet søker etter relevant kontekst – konteksten sendes med til språkmodellen – modellen svarer. Problemet oppstår i «søk etter relevant kontekst»-steget når du vil søke på åpent internett.
De vanligste løsningene har alle ulemper:
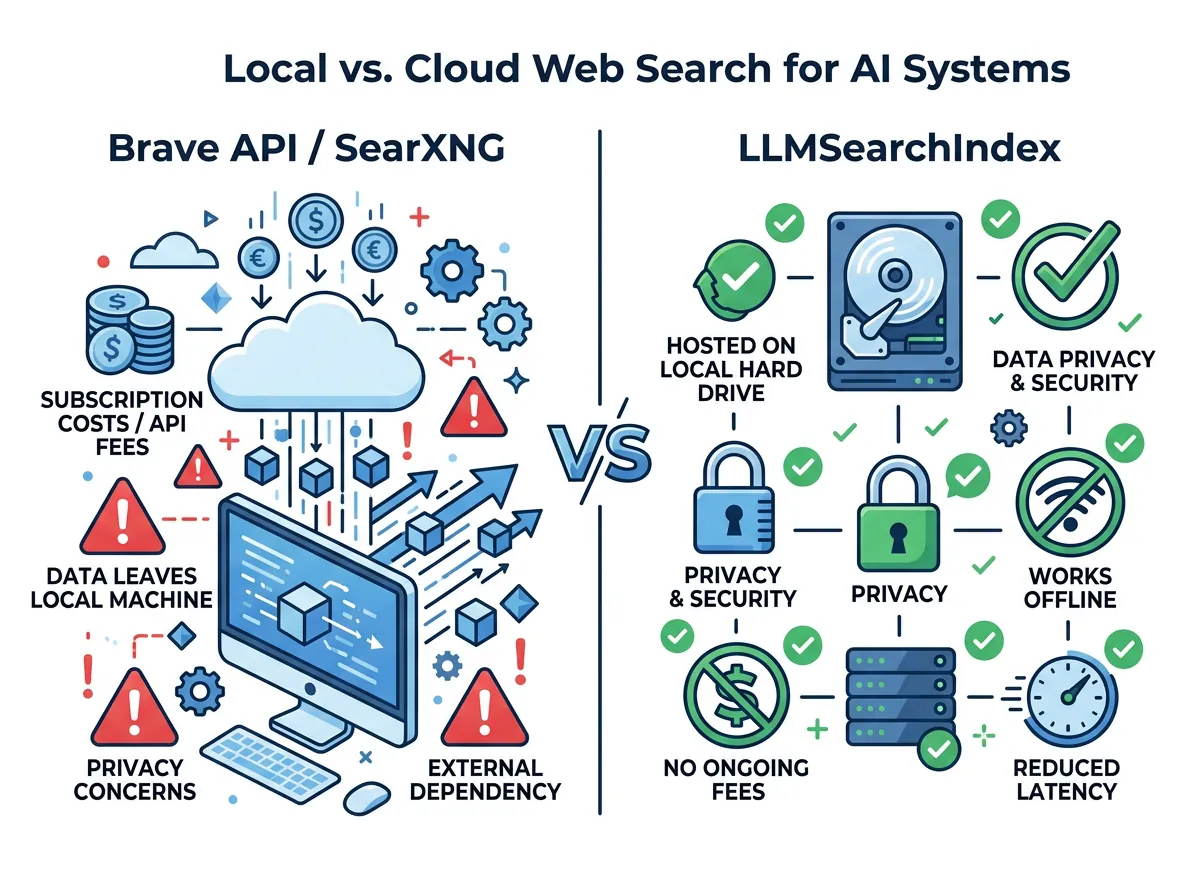
Brave Search API koster $3 per 1 000 spørsmål. For personlig bruk er det håndterbart, men det er fremdeles et eksternt API-kall, og du sender spørsmålene dine til Brave.
SearXNG er gratis og open source, men avhenger av meta-søk og skraping fra Google/Bing som regelmessig feiler med rate-limiting og endrede HTML-strukturer.
Google Custom Search API har en gratis kvote på 100 søk per dag, deretter $5 per 1 000 søk.
DuckDuckGo scraping fungerer inntil det ikke fungerer – og du har ingen SLA eller garantier.
LLMSearchIndex eliminerer alle disse avhengighetene. Når indeksen er lastet ned, skjer alt lokalt uten nettverkskall under søking. Perfekt for systemer som må fungere offline, for personvernbevisste oppsett der data ikke skal sendes ut, eller bare for folk som ikke vil betale per spørsmål.
Hvis du er nysgjerrig på hva RAG faktisk er og hvordan det fungerer, har jeg en forklaring i AI-ordlisten min – se under bokstaven R.
Hva er ulempene?
Ingenting er gratis uten en kostnad et annet sted. Her er de åpenbare kompromissene:
Ikke oppdatert innhold. Indeksen er et øyeblikksbilde av FineWeb og Wikipedia. Det betyr ingen nyheter fra i dag, ingen ferske bloggposter, ingen siste kvartalstall fra børsen. Er spørsmålet ditt tidssensitivt, er dette verktøyet feil valg.
Ikke fullstendig internett. 203 millioner sider høres mye ut, men Common Crawl (som FineWeb er bygget på) er et utvalg – ikke alt. Nisjenettsteder, innhold bak innlogging, nyere innhold og ikke-engelskspråklige sider er dårlig representert.
Diskplass. 10 GB er ikke enormt, men det er noe å tenke på hvis du har begrenset lagring. Til sammenligning er mange Ollama-modeller på 4-8 GB, så du snakker om en ganske heftig lokal installasjon totalt.
Prosjektet er nytt. 5 GitHub-stjerner og 1 fork når dette skrives. Det er ikke et modent prosjekt med lang historikk. Forventes bugs, mangler og liten community rundt feilsøking.
Passer det for n8n-automatisering?
Ja, dette er faktisk interessant i en n8n-basert automatiseringspipeline. Tenk deg en workflow der en bruker stiller et spørsmål, n8n kaller LLMSearchIndex via en Python-funksjon, henter de relevante tekstsegmentene, sender dem som kontekst til Ollama, og returnerer svaret. Hele greia kjører lokalt uten API-nøkler.
Det som trengs er en Python HTTP-wrapper rundt LLMSearchIndex som n8n kan kalle via HTTP Request-noden. Det er ikke komplisert å sette opp med Flask eller FastAPI.
For den som allerede har en lokal Ollama-instans og vil legge til nettsøk uten å betale per spørsmål, er dette den enkleste veien dit akkurat nå. Og Ollama-guiden min gir deg grunnlaget for det lokale laget hvis du ikke allerede er i gang.
Er dette noe å følge med på?
Prosjektet er interessant som konsept, men er ærlig talt tidlig i utviklingen. 5 stjerner på GitHub er ikke imponerende. Det mangler benchmarks mot betalte alternativer på søkekvalitet, og det er uklart hvor ofte indeksen vil bli oppdatert fremover.
Det som skiller det fra andre RAG-verktøy er den komprimerte nett-indeksen. Open source RAG-rammeverk finnes det mange av – LlamaIndex, RAGFlow, og andre – men ingen av dem løser «søk på åpent internett lokalt»-problemet på samme måte. De bygger på at du har egne dokumenter, eller at du betaler for ekstern søke-API.
Hvis du vil ha en live demo før du laster ned 10 GB, finnes det en på HuggingFace Spaces. Og alt kode er MIT-lisensiert, så du kan bruke det fritt i kommersielle prosjekter.
Jeg synes det er verdt å følge. Konseptet er solid – et komprimert nett-snapshot for offline RAG-søk er noe som faktisk mangler i verktøykassen. Om prosjektet tar av eller dør stille om seks måneder gjenstår å se. Men et developer-verktøy med lite konkurranse i en nisje der behovet er reelt – det er et godt utgangspunkt.
Se prosjektet på GitHub, eller installer det direkte med pip install llmsearchindex. HuggingFace-demoen lar deg teste uten å sette opp noe lokalt.
Teknisk oppsummering
For de som vil ha tallene samlet på ett sted:
Indeksert innhold: 203 169 792 nettsider (FineWeb + Wikipedia)
Søketeknologi: FAISS vektorindeks med binær kvantisering
Embeddingmodell: all-MiniLM-L6-v2 (384d – komprimert til 64d via PCA)
RAM-krav: ~6 GB
Diskplass: ~10 GB
GPU: ikke påkrevd
Lisens: MIT (fri kommersiell bruk)
Installasjon: pip install llmsearchindex







