

Innhold Vis
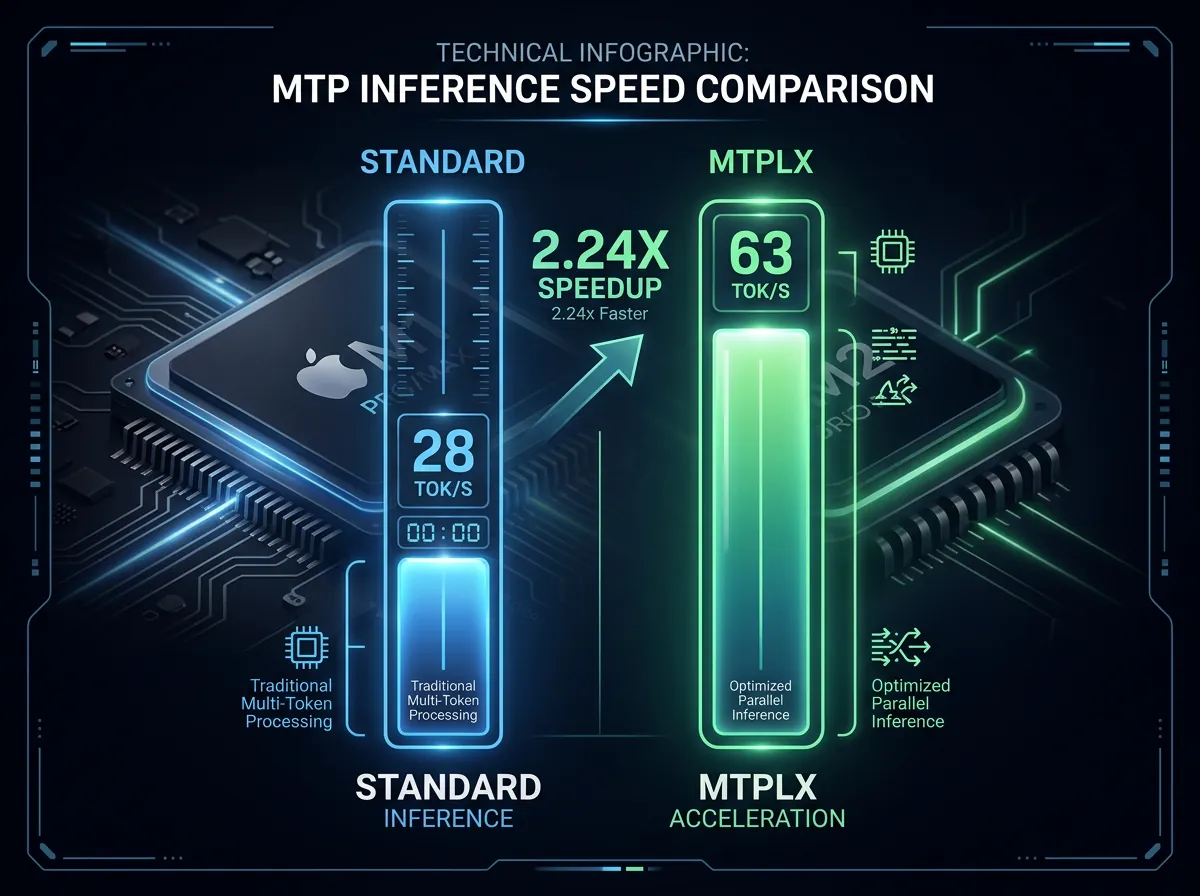
MTPLX er en ny, innebygd MTP-inferensmotor for Apple Silicon som gir opp til 2,24 ganger raskere token-generering uten å bruke ekstra minne. Prosjektet dukket opp på LocalLLaMA denne uken og har allerede skapt stor interesse blant Mac-brukere som kjører store språkmodeller lokalt. Kjernetallet er konkret: Qwen3.6-27B gikk fra 28 tokens per sekund til 63 tokens per sekund på en MacBook Pro M5 Max.
Det som skiller MTPLX fra lignende prosjekter er at det ikke bruker en ekstern drafter-modell. Det utnytter i stedet MTP-hodene (Multi-Token Prediction heads) som allerede er bakt inn i selve modellen under trening. Det betyr at du slipper å laste ned en ekstra liten modell, og du slipper minneoverheaden som følger med. Ingenting ekstra – bare den ytelsen som allerede lå gjemt i modellen din.
For deg som kjører lokale modeller på Mac er dette verdt å følge med på. MTP-støtte har vært under utvikling i flere rammeverk det siste halvåret, og MTPLX tar det et steg videre ved å optimalisere spesifikt for Apple Silicon-arkitekturen.
Hva er MTPLX, og hva gjør det annerledes?
MTPLX er ikke enda et spekulativt dekodingsprosjekt. Det er bygd på en distinkt idé: i stedet for å koble til en liten draft-modell som gjetter de neste tokenene og så lar stormodellen verifisere, bruker MTPLX de forhåndstrente MTP-hodene som allerede sitter i modellarkitekturen.
Mange nyere modeller – inkludert Qwen3-serien og DeepSeek V3 – ble trent med MTP-hoder innebygd. Tanken bak det er nettopp at modellen under trening lærer å forutsi flere tokens fremover samtidig, og disse hodene kan brukes direkte under inferens. Problemet har vært at de fleste inferensrammeverk ikke har utnyttet dem skikkelig, særlig på Apple Silicon.
Det er der MTPLX kommer inn. Prosjektet implementerer matematisk eksakt temperatur-sampling med rejection sampling, i motsetning til den grådige tilnærmingen mange lignende prosjekter bruker. Det betyr at du får nøyaktig de samme svarene som du ville fått uten optimaliseringen – ikke en tilnærming. Ytelsen er reel og uten kompromisser på kvalitet.
Temperaturen kan justeres fritt, noe som gjør det brukbart for alt fra kodegenerering (lav temperatur, deterministisk) til kreativ skriving (høy temperatur, mer variasjon) og vanlig chat.
Hva er ytelsestallene i praksis?
Tallene som er rapportert er fra Qwen3.6-27B på en MacBook Pro M5 Max, kjørt ved temperatur 0,6:
- Uten MTPLX: 28 tokens per sekund
- Med MTPLX: 63 tokens per sekund
- Speedup: 2,24x
Det er en solid forbedring. For å sette det i kontekst: 28 tokens per sekund er allerede raskere enn det de fleste leser, men det merkes ved lengre svar. 63 tokens per sekund gir en opplevelse som nærmer seg umiddelbar respons for de fleste brukstilfeller.
Til sammenligning har llama.cpp sin MTP-beta vist lignende speedup-tall på Qwen3.6-27B – fra rundt 7 tokens per sekund til 15-21 tokens per sekund – men det er på CPU/CUDA-hardware. MTPLX er rettet spesifikt mot MLX og Apple Silicon, og kombinert med M5 Maxs 614 GB/s minnebåndbredde er det en naturlig match.
Hvilke modeller fungerer med MTPLX?
Det er et viktig spørsmål. MTPLX fungerer på alle modeller som allerede har MTP-hoder innebygd. Du trenger ikke spesielle versjoner – bare en modell som ble trent med MTP aktivert.
Per i dag gjelder det blant annet:
- Qwen3-serien (Qwen3.6-27B, Qwen3.5-serien og lignende)
- DeepSeek V3 og modeller basert på samme arkitektur
- Andre modeller der MTP-hoder ble inkludert under trening
Det er verdt å merke seg at ikke alle populære modeller har dette. Google fjernet for eksempel MTP fra de offentlig tilgjengelige Gemma 4-modellene, noe jeg skrev om da det skjedde. Markedskreftene gjør sitt arbeid: Qwen og DeepSeek inkluderer det, Google holder det tilbake i sine åpne modeller. Brukernes valg av hva de laster ned vil si noe om hva produsentene prioriterer fremover.
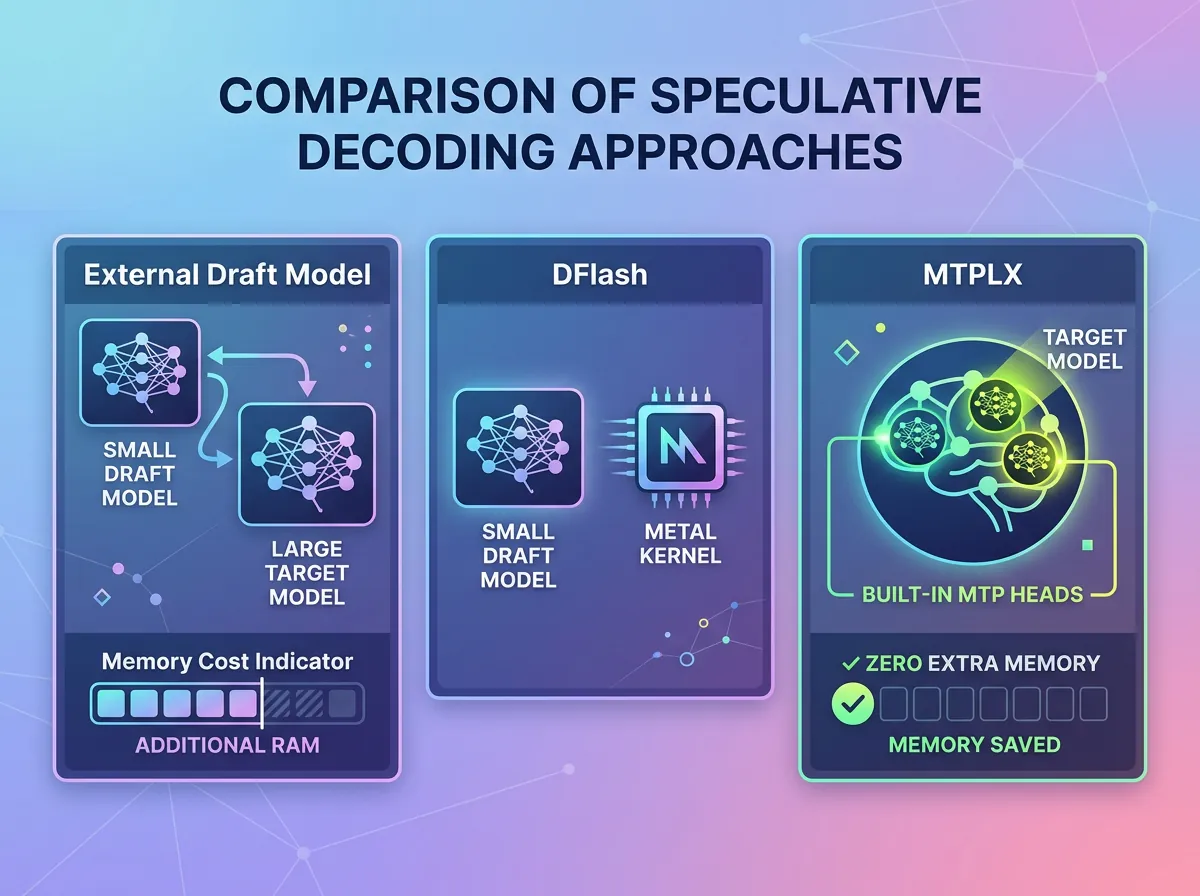
Hvordan skiller MTPLX seg fra llama.cpp og DFlash?
Det er tre MTP/spekulative dekodingsprosjekter som er relevante å sammenligne akkurat nå:
llama.cpp MTP-beta – støtter Qwen3-arkitekturer og kjører bra på CPU og NVIDIA GPU. Beta-stadium betyr at det er stabilitetsforbehold, men ytelsestallene er dokumenterte. Fungerer ikke på Apple Silicon via MLX.
DFlash-mlx – et spekulativt dekodingsprosjekt for Apple Silicon som bruker en liten draft-modell. Lossless output via rejection sampling, egne Metal-kjerner for numerisk presisjon. Krever ekstern drafter-modell og dermed ekstra minne og kompleksitet.
MTPLX – bruker modellens egne innebygde MTP-hoder. Ingen ekstern drafter, ingen minneoverhead. Matematisk eksakt sampling. Rettet mot Apple Silicon og MLX-rammeverket.
Fordelen med MTPLX-tilnærmingen er enkel: du trenger ikke å finne, laste ned og konfigurere en passende draft-modell. Hvis modellen din har MTP-hoder – og Qwen3-serien har det – er alt klart allerede.
Bakgrunnen for hvorfor MTP i det hele tatt er mulig som en inferensoptimalisering kan du lese mer om i denne forklaringsartikkelen om MTP og speculative decoding.
Hva betyr dette for Mac-brukere som kjører lokale modeller?
Apple Silicon har blitt et seriøst alternativ for lokal AI de siste to årene. M5 Max leverer 614 GB/s minnebåndbredde, noe som er avgjørende for inferenshastighet – det er minnet som er flaskehalsen, ikke datakraften. En 27B-modell kjører fint innen unified memory på et Max-chip med 96 GB eller mer.
Det som har manglet er optimaliserte inferensverktøy som tar ut det siste av Apple Silicon-arkitekturen. Ollama kjører via MLX på Mac siden nylig, og DFlash-mlx viste at det var mer ytelse å hente med spesialiserte implementasjoner. MTPLX fortsetter denne trenden med et annet angrepspunkt.
For deg med en M3 Max, M4 Max eller M5 Max og en Qwen3-modell er dette potensielt en enkel ytelsesøkning uten noen kostnad – verken i penger, ekstra nedlastinger, eller kvalitetskompromisser.
Prosjektet er veldig nytt og dukket opp på Reddit-fellesskapet r/LocalLLaMA denne uken. Det er verdt å følge med på det videre arbeidet – om det ender opp integrert i mlx-lm som standard funksjonalitet, vil mange Mac-brukere merke det uten å gjøre noe som helst.
Spekulativt dekoding og MTP-optimalisering er ikke en kuriositet lenger. Det er en kategori verktøy som aktivt konkurrerer om å bli standard i lokale inferensrammeverk – og Apple Silicon er midt i smørøyet av den konkurransen.








2 kommentarer