

Innhold Vis
Store språkmodeller er trege av en enkel grunn: de genererer ett token om gangen. Hvert eneste ord – eller del av et ord – krever en full runde gjennom milliarder av parametre. Resultatet er at selv kraftige modeller på bra hardware kan føles seige når du venter på lange svar.
Men det finnes smarte triks for å lure modellen til å tenke fortere. To av dem heter speculative decoding og Multi-Token Prediction (MTP) – og de siste månedene har disse konseptene dukket opp oftere og oftere i diskusjoner om modeller som DeepSeek V3, Qwen og Gemma 4. Her er en forklaring som ikke krever maskinlæringsgrad for å forstå.
Hvorfor er språkmodeller trege – ett token om gangen
Når en stor språkmodell genererer tekst, gjør den én ting om gangen: den regner ut hva det neste tokenet sannsynligvis er, basert på alt som har kommet før. Deretter gjør den det igjen. Og igjen.
Et token er grovt sett en stavelse, et kort ord, eller et tegn. Ordet «anything» er ett token. «Maskinlæring» kan være to. En setning på 20 ord er typisk 25-35 tokens. En stor modell med 90 milliarder parametere må løpe gjennom enorme matrisemultiplikasjoner for hvert eneste av dem – og det tar tid, selv på kraftig GPU.
Problemet er ikke at modellen er dum. Den er faktisk god til jobben. Problemet er at den er seriell: ett token, pause, ett token til, pause. Det er som å skrive ett bokstav av gangen med full tenkning mellom hver gang. Hvis du vil forstå mer om hvordan selve token-prosessen fungerer, har jeg en mer grundig forklaring i denne artikkelen om hvordan språkmodeller fungerer.
Hva er speculative decoding – og hvordan fungerer det?
Speculative decoding er et 10-kroners ord for en 2-kroners idé. Ideen er: bruk en liten modell til å gjette tokens i forveien, og la den store modellen verifisere gjetningen i stedet for å beregne den selv.
Tenk deg at du har nok GPU til å kjøre Llama 3.2 90B – en enorm modell. Den er treg, men god. Llama 3.2 finnes også i en 1B-variant som kan kjøre 400-500 tokens per sekund på samme hardware. Ideen med speculative decoding er å la 1B-modellen løpe i forveien og gjette neste 5-10 tokens. Deretter sender du disse gjetningene til 90B-modellen og spør: «Stemmer dette?»
Stor modell kan verifisere mange tokens på én gang raskere enn den kan generere dem én om gangen. Resultatet kan bli 2-3 ganger høyere gjennomstrømning – ikke i alle tilfeller, men når det klaffer, klaffer det skikkelig.
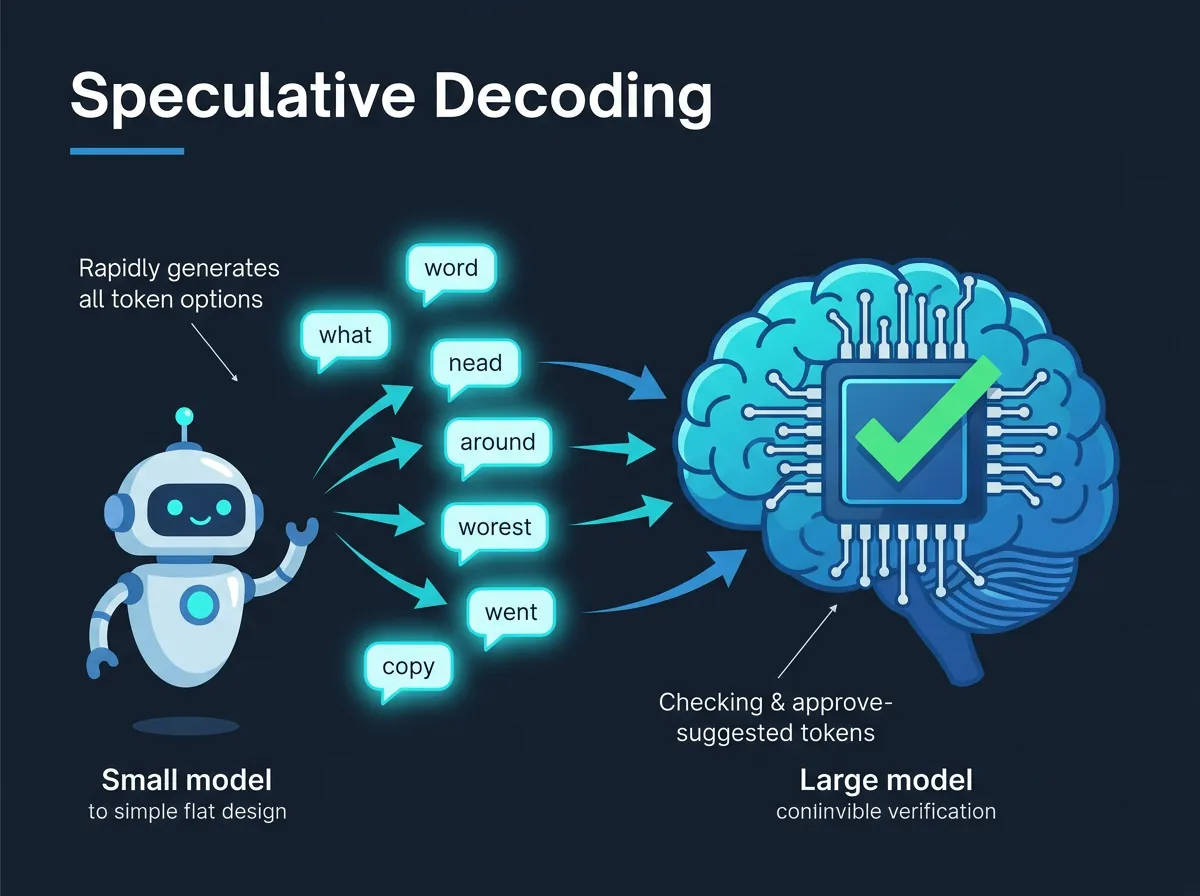
Det er noen fallgruver. Utkast-modellen er liten og kan gjette feil. Hvis den gjetter feil for mye, blir den store modellen nødt til å avvise og regenerere – noe som kan gjøre det tregere enn uten speculative decoding. I praksis er feilraten vanligvis lav nok til at det lønner seg uansett.
Og det beste: dette krever ingen spesialtrening av modellen. Det er arkitektur du bare legger oppå. LM Studio og llama.cpp støtter det allerede i dag.
Hvorfor må begge modellene ha samme vokabular?
Her er det ene kravet som ikke er forhandlingsbart: utkast-modellen og den store modellen må komme fra samme modellfamilie og bruke samme vokabular.
Årsaken er enkel. Tokens er ikke ord – de er tall. Tokenet «anything» kan ha ID 42033 i Llama 3. Samme token kan ha en helt annen ID i Qwen. Hvis utkast-modellen sier «neste token er 42033» og den store modellen tolker 42033 som noe helt annet, får du meningsløst tull som output – eller avvisning.
Derfor kan du ikke pare Llama 3.2 90B med Qwen 3 0.5B, selv om Qwen er liten og rask. De snakker ikke samme tokenspråk. Du trenger en liten variant av akkurat samme modell som den store.
SSD – speculative speculative decoding
Når det enkle trikset ikke er nok, finnes det en variant som stikker to nivåer dypere: SSD, eller speculative speculative decoding. Navnet er kjedelig, men ideen er fascinerende.
SSD er i praksis speculative decoding brukt rekursivt. I stedet for å gjette ett steg fremover, gjetter utkast-modellen flere mulige grener av fremtiden – som Doctor Strange som ser gjennom millioner av mulige tidslinjer. Én av disse grenene vil statistisk sett treffe riktig. Og siden vi allerede har beregnet den grenen, kan vi hoppe rett til resultatet uten å vente.
Fordelen er enda høyere gjennomstrømning når det fungerer. Ulempen er at hvis utkast-modellen begynner å avvike – gjetter feil konsekvent – så kan dette skalere i feil retning og faktisk gjøre ting tregere. I praksis finnes det måter å håndtere dette på, og SSD er støttet i populære verktøy.
Hva er Multi-Token Prediction (MTP)?
MTP, eller Multi-Token Prediction, er neste steg i den samme logikken – men med en grunnleggende forskjell: i stedet for å bruke to separate modeller, baker du utkast-modellen rett inn i den store modellen under trening.
Resultatet er at du bare trenger én modell å laste inn. Ingen liten modell å holde styr på, ingen vokabular-krav å passe på. Den store modellen har allerede «lært» å forutsi flere tokens fremover som en del av sin arkitektur.
Pionerene her er DeepSeek og Qwen. Begge har implementert MTP i sine nyeste modeller – DeepSeek V3 og Qwen 3.5-variantene har det innebygd. Speculative decoding ble opprinnelig utviklet av Google, men ironisk nok er det kinesiske modellmiljøet som har tatt MTP-ideen lengst ut i produksjon.
Ulempen med MTP er at det er dyrt og komplisert å trene. Og siden det er bakt inn i arkitekturen, kan du ikke bare «legge det til» etterpå slik du kan med vanlig speculative decoding. Modellen må trenes fra grunnen av med MTP i tankene.
Kenguru-analogien: SSD vs MTP
Den beste analogien for å skille de to: speculative decoding (og SSD) er som å feste kengurubein til en menneskefot. Det er noe du kan koble på og av. MTP er som å erstatte foten din med kengurubeinet fra starten av.
Med SSD bestemmer du selv når du vil ha ekstra fart – men du må ha begge modellene tilgjengelig. Med MTP er den ekstra hastigheten alltid der. Du kan ikke skru den av. Det er bare slik modellen fungerer.
Dette gjør MTP enklere å deploye i produksjon – men det betyr også at det er vanskeligere å legge til støtte for det i verktøy som llama.cpp og vLLM. Implementasjonene er modellspesifikke, og selv om det finnes pull requests for både GLM og Qwen 3.5 i llama.cpp, er det ikke noe du bare slår på. Det krever spesialtilpasset kode per modell.
Hvilke modeller har MTP i dag?
Per april 2026 er de tydeligste eksemplene på modeller med innebygd MTP:
- DeepSeek V3 – pioneren, og fremdeles blant de raskeste open-source-modellene
- Qwen 3.5-variantene – Alibabas modellserie som har overrasket mange med sin størrelse-til-ytelse-ratio
- Gemma 4 (delvis) – har MTP i LiteRT-versjonen for edge-enheter, men det ble fjernet fra de offentlige HuggingFace-modellene på grunn av kompatibilitetsproblemer med llama.cpp og transformers-biblioteket
Gemma 4-situasjonen er litt frustrerende. Modellen har MTP, men bare i Googles eget LiteRT-rammeverk – som er åpen kildekode, men knapt 8 000 nedlastinger sammenlignet med nesten én million for GGUF-versjonen. De fleste som kjører Gemma 4 lokalt får altså ikke ytelsesfordelen.
Qwen-modellene har generelt vært imponerende i det siste. Jeg har skrevet om Qwen 3.5 4B som løste abstraksjonstest der GPT-4 feilet – og MTP er én del av forklaringen på hvorfor de yter over forventet størrelse.
Hva betyr dette hvis du kjører lokal AI?
Hvis du bruker Ollama, LM Studio, llama.cpp eller vLLM til å kjøre modeller lokalt, er dette relevant av flere grunner.
For det første: vanlig speculative decoding kan du slå på i dag i LM Studio og llama.cpp, forutsatt at du bruker en modell som finnes i flere størrelser fra samme familie. Llama 3.2 1B/3B + 90B er et klassisk eksempel. Det koster ingenting ekstra og kan gi merkbar fartsforbedring på lange svar.
For det andre: MTP-støtte i llama.cpp er på vei, men varierende. Det finnes pull requests for DeepSeek og Qwen 3.5, men det er ikke nødvendigvis aktivert som standard i alle bygg eller verktøy. vLLM for Python har også kanttilfeller der det ikke fungerer enda.
For det tredje: når du velger mellom modeller og én av dem har MTP innebygd, er det en reell ytelsesfordel – spesielt for lange genereringer. Ikke se bort fra det.
Kort oppsummert – speculative decoding vs MTP
- Speculative decoding: Liten modell gjetter tokens, stor modell godkjenner. To modeller, kan slås på/av, krever ingen spesialtrening. 2-3x fartsforbedring mulig.
- SSD (speculative speculative decoding): Gjetter flere steg fremover, rekursivt. Raskere når det fungerer, kan bli tregere hvis utkast-modellen avviker for mye.
- MTP (Multi-Token Prediction): Utkast-modellen er bakt inn under trening. Én modell, alltid aktiv, men krever spesialtilpasset støtte i kjøringsverktøy. Pionerer: DeepSeek og Qwen.
Arkitekturforskjellen mellom modeller som ser like ut på papiret kan altså ha praktisk betydning for deg som bruker dem. En modell med MTP kan gi deg merkbart mer tekst per sekund – noe som betyr kortere ventetid, mer flytende dialog, og bedre opplevelse på modest hardware.
Neste gang du ser en artikkel om at en ny modell har «innebygd speculative decoding» eller «MTP-støtte» – vet du nå hva det faktisk betyr.








7 kommentarer