

Innhold Vis
PR 22673 er merget inn i llama.cpp master, og det betyr at multi-token prediction (MTP) nå er tilgjengelig for alle som kjører modeller lokalt. Ingen eksperimentelle byggversjoner, ingen patcher. Bare git pull og en ny flagg i kommandolinjen.
Hvis du ikke har hørt om MTP før: det er teknologien som lar en modell gjette flere tokens i én operasjon i stedet for å plodde seg gjennom dem ett og ett. Resultatet er at inferensen går raskere uten at du trenger kraftigere hardware. Jeg har forklart mekanikken i detalj tidligere – den korte versjonen er at modellen trener inn en liten «gjettefunksjon» som predikerer de neste 2-4 tokenene, mens hoveddelen verifiserer dem i én iterasjon.
Det praktiske gjennombruddet er at dette nå er offisielt innebygd i llama.cpp. Ikke et sideprosjekt, ikke en fork. Merge inn i master.
Hva er PR 22673, og hva gjør den?
PR 22673 legger til støtte for MTP-hoder direkte i llama.cpp. Implementasjonen laster MTP-hodet fra samme GGUF-fil som selve modellen – det er altså ikke nødvendig med en separat draft-modell slik speculative decoding tradisjonelt krever. MTP-hodet har sin egen context og KV-cache, og aktiveres med flagget --spec-type draft-mtp.
Akkurat nå er implementasjonen i første omgang testet og optimalisert mot to modeller: Qwen 3.6 27B (den dense varianten) og Qwen 3.6 35B-A3B (mixture-of-experts). Arkitekturelt er det ingenting i veien for at andre MTP-trente modeller vil fungere etter hvert som støtten modnes.
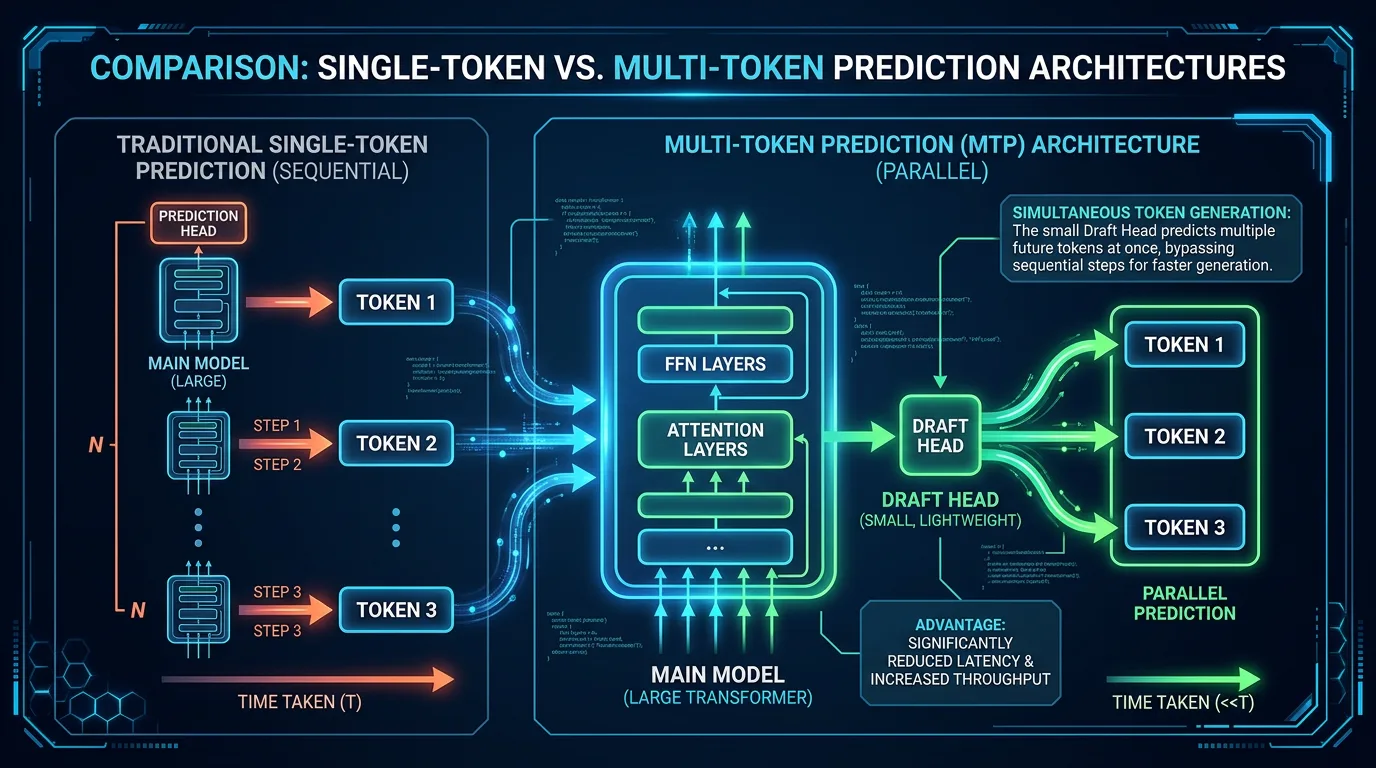
Hva slags speedup kan du forvente?
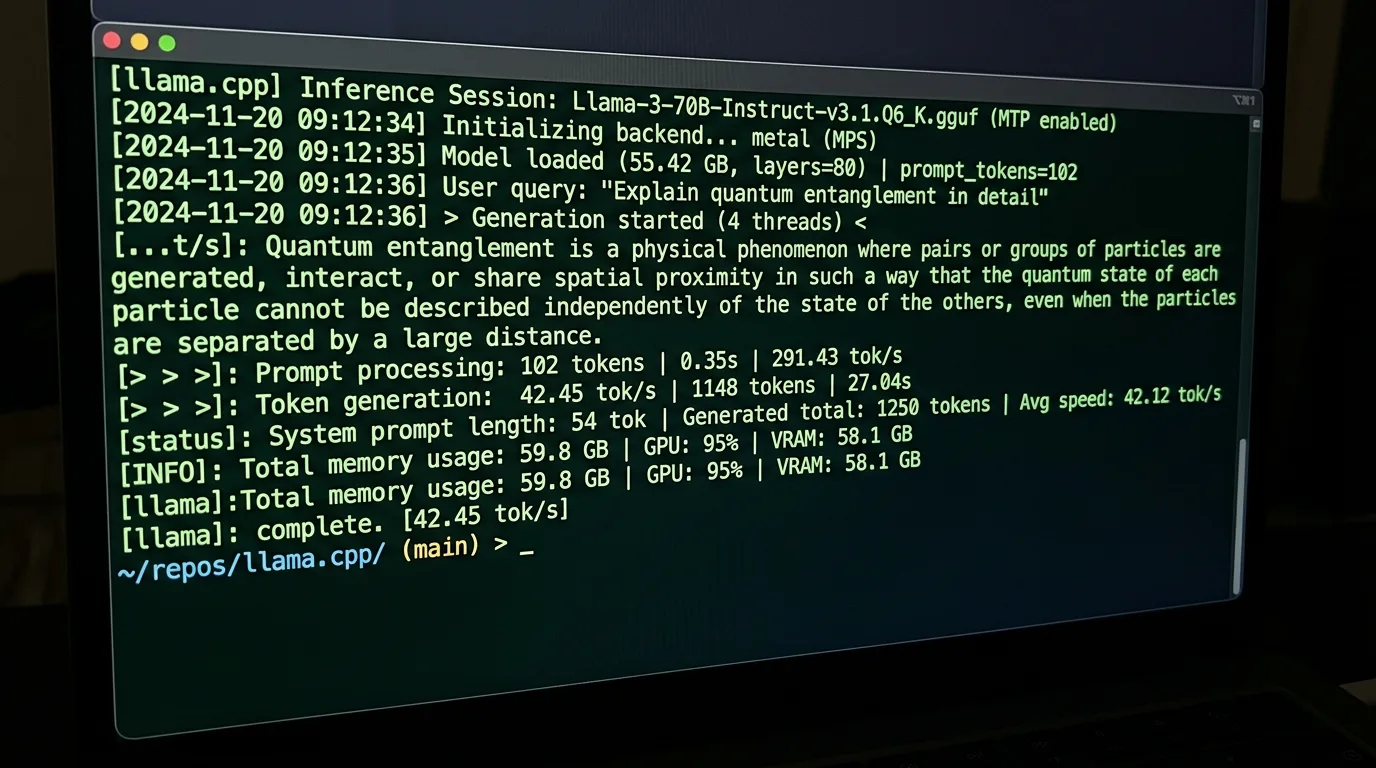
Benchmarktallene fra PR 22673 viser 1,9x speedup på RTX 3090 – fra 22,39 tok/s til 42,45 tok/s med MTP aktivert. Med 3 draft-tokens og en steady-state akseptansegrad på rundt 75 % er potensialet 2-3x i gjennomsnitt. Minnekostnaden er omtrent 2,5 GB ekstra VRAM – under 10 % av det en typisk modell bruker.
Jeg har tidligere skrevet om TurboQuant-kombinasjonen på MacBook Pro, der MTP tok Qwen 27B fra 21 til 34 tokens per sekund – en økning på 62 % på Apple Silicon. Tallene varierer med hardware, men retningen er den samme overalt.
En ting å merke seg: prompt-processing går litt tregere med MTP aktivert, fordi det oppstår noen ekstra device-to-host-overføringer for embeddings. Det er en kjent begrensning som PR-forfatteren er tydelig på er et optimaliseringsområde fremover. Selve genereringshastigheten – det du faktisk merker i bruk – er der speedupen er.
Hvordan aktiverer du MTP i llama.cpp?
Forutsetningen er at du bruker en GGUF-fil som faktisk inneholder et MTP-hode. Vanlige kvantiseringer uten MTP-hode vil ikke profitere på flagget. Per nå er det primært AtomicChat-samlingen på HuggingFace som tilbyr MTP-GGUF-filer for Qwen 3.6-modellene.
Selve aktiveringen er enkel. Etter at du har oppdatert llama.cpp til siste master, kjører du det slik:
./llama-cli -m modellen-din-mtp.gguf --spec-type draft-mtp -n 512 -p "Din prompt her"
Flagget --spec-type draft-mtp er alt som trengs. llama.cpp laster MTP-hodet automatisk fra GGUF-filen og setter opp sin egen context og KV-cache for det.
Hva er forskjellen fra vanlig speculative decoding?
Vanlig speculative decoding – som llama.cpp har støttet en stund – krever to separate modeller: en stor og en liten draft-modell som deler vokabular. Du trenger altså Llama 70B og Llama 8B samtidig, noe som dobler minnekravet og kompliserer oppsettet.
Med MTP er gjettefunksjonen trent direkte inn i modellens arkitektur. Det betyr én fil, ett minneavtrykk, og ingen jakt etter en kompatibel draft-modell. Gemma 4 er et godt eksempel på hva som skjer når produsenten fjerner MTP-hodet fra den offentlige modellen – du mister speedupen umiddelbart. Med Qwen 3.6 er MTP-hodet med i de offentlige GGUF-filene, og nå kan llama.cpp faktisk bruke det.
Kompatibiliteten er bred. PR-en er bygget med støtte for vision input, tensor-parallellisme, pipeline-parallellisme, og kan kjedes med andre spekulative metoder som ngram-mod. Det er ikke en halvferdig implementasjon – det er produksjonsklar kode.
Hvem bør bry seg om dette?
Alle som kjører Qwen 3.6-modeller lokalt bør oppdatere llama.cpp og bytte til en MTP-GGUF nå. Det er nærmest gratis ekstra ytelse – samme hardware, samme modell, 1,9x til 2,5x raskere output.
For andre modeller er situasjonen litt mer avventende. MTP-støtten er nå i master, men den faktiske gevinsten avhenger av at modellprodusentene trener MTP-hoder og inkluderer dem i sine GGUF-distribusjoner. Det er rimelig å forvente at DeepSeek og andre vil følge etter Qwen på dette.
Frem til da er det verdt å holde øye med HuggingFace-samlinger som spesifikt tilbyr MTP-varianter. Når modellen har hodet og llama.cpp støtter det, er én flagg det eneste som skiller deg fra dobbel hastighet.







