

Innhold Vis
Hva om du kunne spre FLUX 2 over to GPUer som ikke engang er i samme maskin – og gjøre det via et vanlig nettverkskabel? En utvikler på Reddit har gjort akkurat det, med en egenbygd NVENC encoder bridge som deler modelllagene mellom to kort over Ethernet LAN. Resultatet: 4,4 sekunder per bilde med en 5090 og en laptop-4090 splittet på to separate maskiner.
Dette er ikke et Nvidia-produkt. Det er ikke en offisiell funksjon i ComfyUI eller noe annet rammeverk. Det er en person som har bygget noe fra bunnen av – og det fungerer.
For deg som sitter med én GPU og drømmer om å kjøre de tyngste modellene lokalt, er dette interessant lesing. Og for deg som allerede har to kort, er det kanskje på tide å se nærmere på hva som er mulig uten å betale fem sifre for NVLink-hardware.
Hva er problemet med multi-GPU og lokal AI?
Nvidia fjernet NVLink fra sine forbrukerkort allerede med RTX 4000-serien. Det betyr at selv om du kjøper to RTX 4090-er eller to RTX 5090-er, kan de ikke dele VRAM som én minnepool slik profesjons-GPU-er kan. De kommuniserer via PCIe-bussen, som har en effektiv båndbredde på rundt 30 GB/s – knapt nok for tunge diffusjonsmodeller som FLUX 2.
Resultatet er at store modeller som ikke passer i én GPUs VRAM tradisjonelt sett har krevd enten offloading til systemminne (langsomt) eller dyre workstation-kort med NVLink. Alternativt: vent på at noen finner en vei rundt begrensningen.
Den veien er nå her.
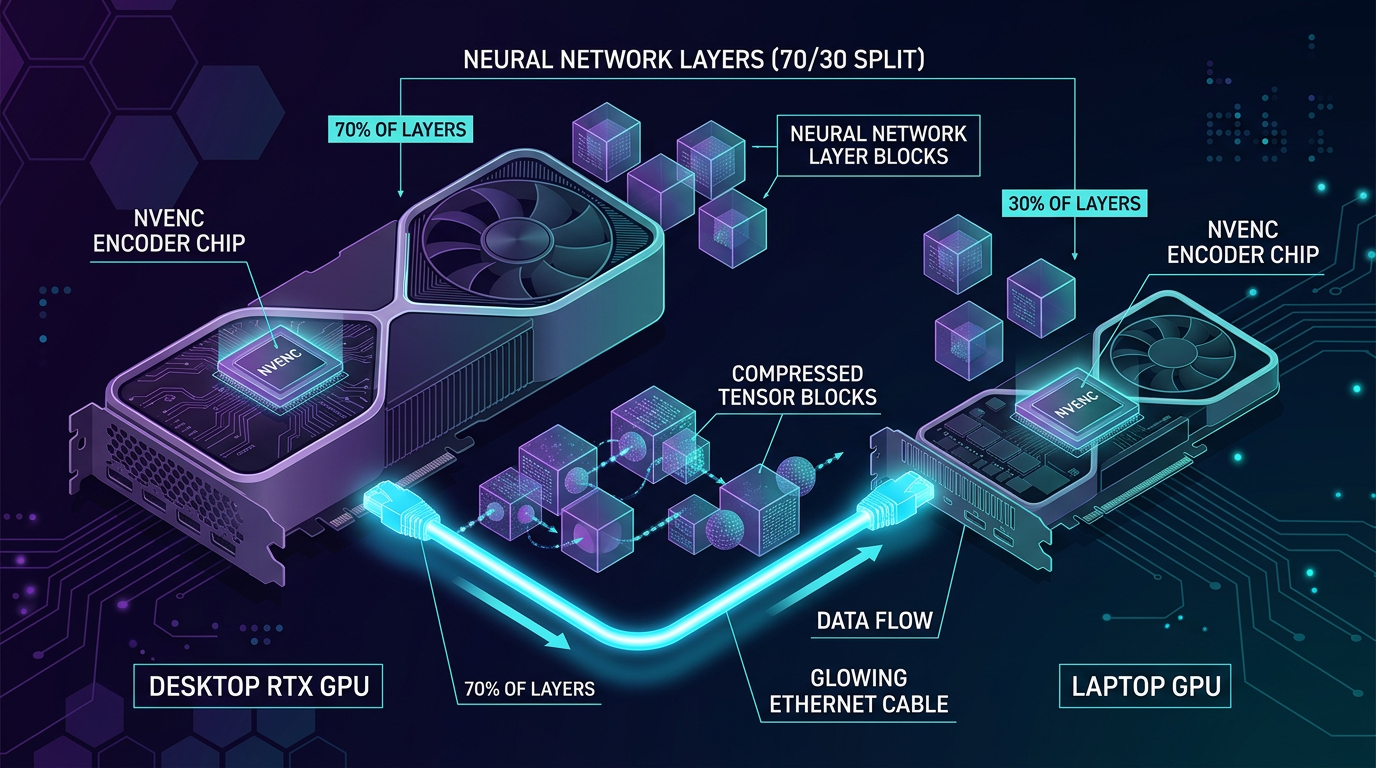
Hvordan fungerer NVENC encoder bridge-løsningen?
Kjernen i løsningen er NVENC-brikken som sitter på alle Nvidia-kort med NVENC-støtte. Denne brikken er designet for å komprimere videosignaler i sanntid, men utvikleren har funnet en ny bruk for den: å komprimere tensordata fra nevrale nettverk før de sendes mellom GPU-er.
Prinsippet bygger på det samme som torch-nvenc-compress demonstrerte for PCIe-overføring: ved å bruke PCA-forbehandling og NVENC-komprimering kan diffusjonsaktiveringer komprimeres med en faktor på over 6:1 med minimalt tap av kvalitet. Det som normalt krever 180 GB/s effektiv båndbredde kan dermed sendes over en mye smalere kanal.
I dette tilfellet er kanalen ikke engang PCIe – det er Ethernet. Modelllagene partisjoneres mellom de to GPU-ene, aktiveringstensorene komprimeres via NVENC, sendes over nettverket og dekomprimeres på mottakersiden. Alt dette skjer automatisk, transparent for selve modellen.
Støttede modeller i første versjon: FLUX 2 Dev, LTX 2.3 og Kling 9b. Alle Nvidia-kort med NVENC-støtte skal fungere, og utvikleren oppgir at prosjektet har en detaljert README for rask oppstart.
Hva er de faktiske ytelsestallene?
Utvikleren har testet flere konfigurasjoner, og tallene er overraskende gode tatt i betraktning at dette er en nettverksbasert løsning:
Den primære testoppsettet – RTX 5090 hjemme og en laptop med RTX 4090 – produserte bilder på 4,4 sekunder over Ethernet LAN. Det er ikke RTX 5090 alene, men det er heller ikke noe man trenger å skjemmes over.
Det mest imponerende resultatet er kanskje cafe-testen: 70% av modellen lastet på desktop hjemme, 30% på en laptop på en kafe – koblet via Tailscale VPN over mobil-tethering. 1 megapiksel bilder på under 8 sekunder. Over mobilnett. Det er ikke tall man forventer fra en «hobb-løsning».
WiFi 6 fungerte ifølge utvikleren «veldig bra», noe som gir mening gitt at komprimerte aktiveringstensorer er langt mindre dataintensive enn rå modellvekter ville vært.
Multi-GPU i én PC støttes også, for dem som vil unngå nettverkskompleksiteten helt.

Hva betyr dette for folk som kjører lokale modeller?
FLUX 2 Dev er en kraftig modell, men den er tung. Med 12 GB VRAM er det begrenset hva du kan gjøre uten å ty til kvantisering. Med en laptop som støttende GPU – selv over WiFi – åpnes det for å kjøre modellen i høyere presisjon eller med større oppløsning enn én enkelt GPU tillater.
Det interessante her er ikke bare ytelsen, men infrastrukturen. Løsningen krever ikke at kortene er i samme maskin. Den krever ikke en gang at de er koblet med kabel direkte – Tailscale og WiFi fungerer. Det betyr at en gammel spillmaskin som samler støv i et annet rom potensielt kan bli en sekundær «inference node» for en mer moderne arbeidsstasjon.
Vi har sett lignende ideer for LLM-er. To gamle RTX 2080 Ti kan kjøre Qwen3.6 27B med 38 token/s over PCIe. llama.cpp b9095 fikk NCCL-fri tensor parallelisme på dual Blackwell PCIe uten å måtte bruke CUDA-avhengig kommunikasjon. Dette NVENC bridge-prosjektet tar den logikken ett steg videre og applicerer den på diffusjonsmodeller – og fjerner kravet om fysisk nærhet mellom GPU-ene.
Hva er kravene for å ta det i bruk?
Kravene er relativt beskjedne. Du trenger Nvidia-kort med NVENC-støtte på begge maskiner – det betyr i praksis de fleste GeForce-kort fra GTX 10-serien og nyere. Windows er oppgitt som operativsystem. PyTorch med CUDA må være installert.
Nettverksdelen er fleksibel: LAN, WiFi 6 og til og med mobile hotspot via Tailscale VPN er bekreftet å fungere. Det eneste kravet til nettverket er at det er lavt nok i latens og har nok gjennomstrømning til å håndtere de komprimerte aktiveringstensorene.
Prosjektet har en detaljert README som skal gjøre oppsett raskt. Utvikleren har planlagt støtte for flere modeller fremover, noe som betyr at dette sannsynligvis ikke er begrenset til FLUX 2, LTX 2.3 og Kling 9b i lengden.
For deg som er interessert i FLUX 2 og hva den faktisk leverer, er dette et tillegg til verktøykassa som gjør det mer tilgjengelig å kjøre modellen lokalt uten å kompromisse på kvalitet. Og for deg som følger utviklingen av Nvidia og AI-hardware generelt, er det fascinerende å se hvor langt community-utviklede løsninger strekker seg for å omgå begrensningene Nvidia har lagt inn ved å fjerne NVLink fra forbrukerkortene.
Kilden er en Reddit-tråd i r/StableDiffusion. Prosjektet er åpent og aktivt. Vil du bruke gammel hardware til noe nytt – er dette verdt å sjekke ut.







