

Innhold Vis
En bruker på Reddit delte nylig sitt hjemme-AI-oppsett: to gamle RTX 2080 Ti med 22GB VRAM hver, koblet i ett system og kjørende Qwen3.6 27B til 38 token/s. Det er litt av et regnestykke, og det minner meg om at god lokal AI ikke alltid handler om å kjøpe det nyeste og dyreste.
RTX 2080 Ti er fra 2018. Ikke akkurat bransjenyheter. Men med litt kreativitet og rett kvantisering kan to slike kort til sammen gi deg 44GB effektiv VRAM – og det er faktisk nok til å kjøre en 27-milliarders-parametermodell i full flyt.
La meg ta deg gjennom hva som skjer under panseret her, og hva dette betyr for deg som vurderer å sette opp din egen lokale AI-server.
Hva gjør dette oppsettet spesielt?
Det som er poenget med dette oppsettet er ikke bare at det funker – det er at det funker billig. RTX 2080 Ti brukte du 10-12 000 kr på i 2019. I dag kan du plukke opp brukte kort for 2 000-4 000 kr stykket. To kort = 44GB VRAM til kanskje 6 000-8 000 kr totalt.
Til sammenligning: en ny RTX 5090 med 32GB VRAM koster over 20 000 kr. Intel Arc Pro B70 med 32GB er på rundt 10 000 kr og har sine egne software-utfordringer. To gamle 2080 Ti gir deg faktisk mer VRAM enn noe enkelt-GPU under 20 000 kr.
Brukeren kjører kortene effektbegrenset til 150 watt hver – ned fra de opprinnelige 250 watt. Totalt strømforbruk under last: under 300 watt for begge. Det er stille og relativt strømsparende for hva du får.

Hvordan er oppsettet konfigurert?
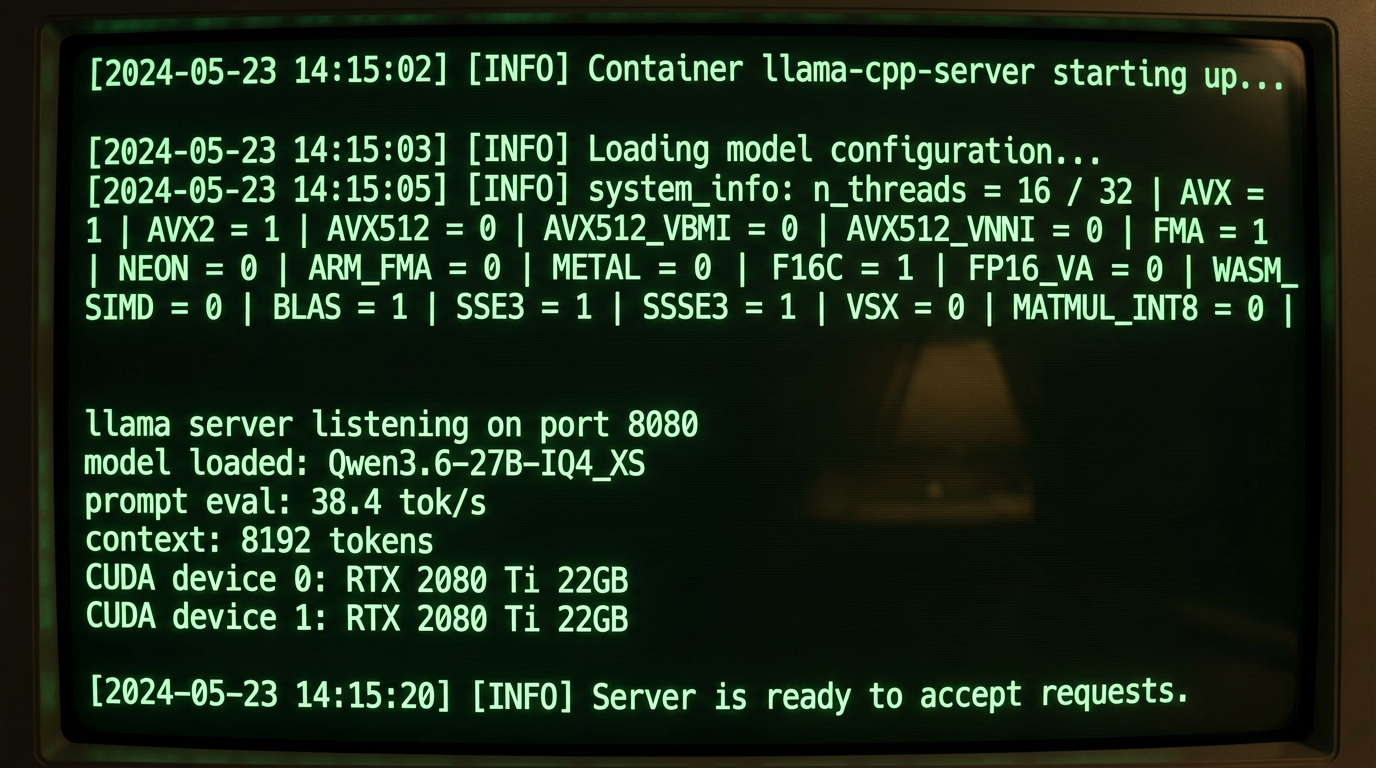
Kjernen er llama.cpp kjørt via Docker med CUDA 12-støtte. Docker-image som brukes er ghcr.io/ggml-org/llama.cpp:full-cuda12-b9128, og serveren startes med modellen Qwen3.6-27B-IQ4_XS-uc.gguf med temperatur 0.6 og top-p 0.95.
Modellen er Qwen3.6 27B i IQ4_XS-kvantisering – en av de tetteste kvantiseringene i GGUF-formatet. IQ4_XS er en «importance matrix»-kvantisering, som betyr at modellen bruker litt mer CPU-tid på å komprimere smartere enn standard Q4. Resultatet er lavere minnebruk med minimalt tap av kvalitet sammenlignet med Q5 eller Q6.
KV-cache er satt til f16 – altså full 16-bit presisjon for kontekstbufferen. Det er mer minnekrevende enn q8 eller q4 KV-cache, men gir bedre konsistens i svar ved lange kontekster. Med 44GB VRAM tilgjengelig er det faktisk mulig å ha råd til f16 KV-cache på en 27B-modell.
Hva er IQ4_XS, og hvorfor betyr det noe?
Kvantisering handler om å redusere presisjonen til modellens vekter fra 16-bit eller 32-bit ned til 4-bit eller lavere. En 27B-modell i full presisjon (f16) bruker rundt 54GB VRAM – umulig på to 2080 Ti. Med IQ4_XS-kvantisering krymper den til rundt 16-18GB, og begge kortene kan dele lasten.
IQ4_XS er et av de smartere kvantiseringsformatene i llama.cpp. Der standard Q4_K_M bruker faste blokkverdier, bruker IQ-formatene en importance matrix som analyserer hvilke vekter som er mest kritiske for modellens ytelse og beskytter dem. Prinsippet ligner TurboQuant – smarter komprimering fremfor brutal bit-reduksjon.
38 token/s med en 27B-modell er solid. For referanse: 10-20 token/s er vanlig for størrelsen i lignende oppsett. At to gamle 2080 Ti slår det er egentlig et tegn på at VRAM-mengde er viktigere enn GPU-generasjon for inferens-ytelse.
Hvorfor fungerer to gamle GPU-er bedre enn én ny?
Her er den interessante biten. LLM-inferens er i stor grad minnebåndbredde-begrenset, ikke beregningsmessig begrenset. Du venter ikke på at GPU-en skal gjøre mattestykker – du venter på at vektene skal lastes fra VRAM til GPU-kjernene.
To RTX 2080 Ti gir 44GB kombinert VRAM. Det betyr at modellen kan bo helt i GPU-minnet uten å delvis laste fra system-RAM. Når modellen ikke trenger å bruke system-RAM som spill, øker hastigheten dramatisk.
En RTX 4070 med 12GB VRAM er raskere per kjerne, men tvinges til å bruke CPU-minnet for en 27B-modell. Da er du ned på 5-8 token/s. Minneflaskehalsen trumfer generasjonsforskjellen. Dette er også bakgrunnen for at prosjekter som LARQL ser på fordeling av modeller over flere maskiner – det handler om VRAM, ikke FLOPS.
Hva koster det å kjøre dette?
Med begge kortene begrenset til 150W er totalt strømforbruk under last ca. 300-320 watt (inkl. resten av systemet). I Norge, med strømpris rundt 0,90-1,10 kr/kWh, tilsvarer det ca. 0,30-0,35 kr per time med full last.
Kjører du modellen 8 timer daglig i en måned: ca. 75-85 kr i strøm. Det er langt under prisen på Claude Pro (230 kr/mnd) eller ChatGPT Plus (250 kr/mnd) – og du har ingen bruksgrenser, ingen telemetri, og full kontroll over hva som kjøres.
Hardvarekostnad: To brukte RTX 2080 Ti til 3 000 kr stykket = 6 000 kr engangsbeløp. Det er ikke ingenting, men over ett år er dette rimeligere enn de fleste AI-abonnementer. Jeg har gått gjennom den samme type regnestykke for RTX 4090 og Ollama – prinsippet er det samme.
Hva er Qwen3.6 27B, og er det en god modell å velge?
Qwen3.6 27B er Alibabas siste versjon i 27-milliarders-parameterfamilien. Jeg er personlig skeptisk til kinesiske AI-modeller av prinsipp, men det er ingen tvil om at Qwen-familien holder teknisk høy kvalitet. Benchmarks viser at 27B-varianten konkurrerer godt med modeller på dobbel størrelse.
For et hjemme-oppsett der du ikke sender sensitive data til en ekstern tjeneste, er det et fornuftig valg hvis du ønsker en kompetent generell modell som passer i 16-18GB VRAM. Alternativer på tilsvarende størrelse du kan se på: Llama 3.3 70B i Q3-kvantisering (om du har enda mer VRAM), Mistral Small 24B, eller Gemma 3 27B.
Qwen3.6 27B er også modellen som ble brukt i DFlash-testene på AMD Strix Halo, der man fikk 2,23x raskere decode med spesialiserte kernels. Dual 2080 Ti-oppsettet her tar ikke i bruk slike optimaliseringer – 38 token/s er rene llama.cpp-tall uten ekstra triks.
Kan du gjøre det samme?
Dersom du allerede har en gammel gaming-PC med én RTX 2080 Ti liggende, er svaret: kanskje. Du trenger et PCIe-breddekort som støtter to x16-slots, og du må sjekke om PSU-en din takler to kort (minimum 750W anbefales for dette oppsettet med 150W-begrensning per kort).
NVLink-bro mellom to 2080 Ti gir raskere GPU-til-GPU-kommunikasjon, men llama.cpp kan også bruke kortene uten NVLink ved å dele modell-lagene mellom dem via CPU-buss. Hastigheten er noe lavere uten NVLink, men det funker.
Docker-oppsettet med llama.cpp er godt dokumentert og relativt enkelt å komme i gang med. Du trenger NVIDIA-driver og nvidia-container-toolkit installert på vertssystemet, så er det i stor grad copy-paste fra docker-compose-eksempelet i den originale Reddit-tråden.
38 token/s er ikke det raskeste du kan få fra Qwen3.6 27B, men det er mer enn raskt nok for daglig bruk, chat og koding. Og det er nok imponerende at to kort fra 2018 fremdeles holder seg relevante i 2026.








1 kommentar