

Innhold Vis
Scenema Audio gjør noe de fleste TTS-modeller ikke klarer: den separerer stemmeidentitet og emosjonell leveranse fullstendig. Du kan ta hvem som helst sin stemme fra 10-20 sekunders referanseopptak, og deretter bestemme akkurat hvordan talen skal leveres – med redsel, sinne, barns nysgjerrighet eller et hviskende raseri – uavhengig av hva referansepersonen selv sa i klippet.
Det høres enkelt ut, men det er faktisk et fundamentalt skille fra det meste som finnes i dag. De fleste voice cloning-verktøy overfører stemmens identitet – klangen, tonefall, aksent – men emosjon og leveranse følger enten kildematerialet eller er et separat parameter du skrur på i etterkant. Scenema Audio er bygget med dette skillet som selve kjernen i arkitekturen.
Teamet bak har jobbet med Scenema – en «prompt to film»-plattform – og audio-komponenten er nå sluppet som open source med modellvekter tilgjengelig. Her er hva modellen faktisk gjør, og hva den krever av maskinen din.
Hva er Scenema Audio, og hva gjør det unikt?
Scenema Audio er en ekspressiv TTS-modell og stemmekloningsmotor bygget på audio-delen av LTX 2.3 sin 22-milliard parameter audiovisuelle modell. Arkitekturen er en audio diffusion transformer – altså samme diffusjonstilnærming som er blitt standarden for bildegenerering, nå brukt på tale.
Det tekniske poenget er todeling: «hvem snakker» og «hvordan snakkes det» håndteres som separate inputs. Referanseaudio gir stemmeidentiteten – klang, resonans, aksent, pustekarakter. Tekstprompten gir leveransen – tempo, emosjon, intensitet, dramatikk. Ingen av delene låser den andre.
I praksis betyr dette at du kan ta en rolig oppleserstemme fra et 15-sekunders klipp og få den til å rope av sinne, hviske med sorg eller le av nervøsitet – uten å ha noe opptak av personen som faktisk gjør det. Det er dette «zero-shot» betyr her: modellen trenger ikke eksempler på den spesifikke emosjonen fra den aktuelle stemmen. Den generaliserer fra prompt.
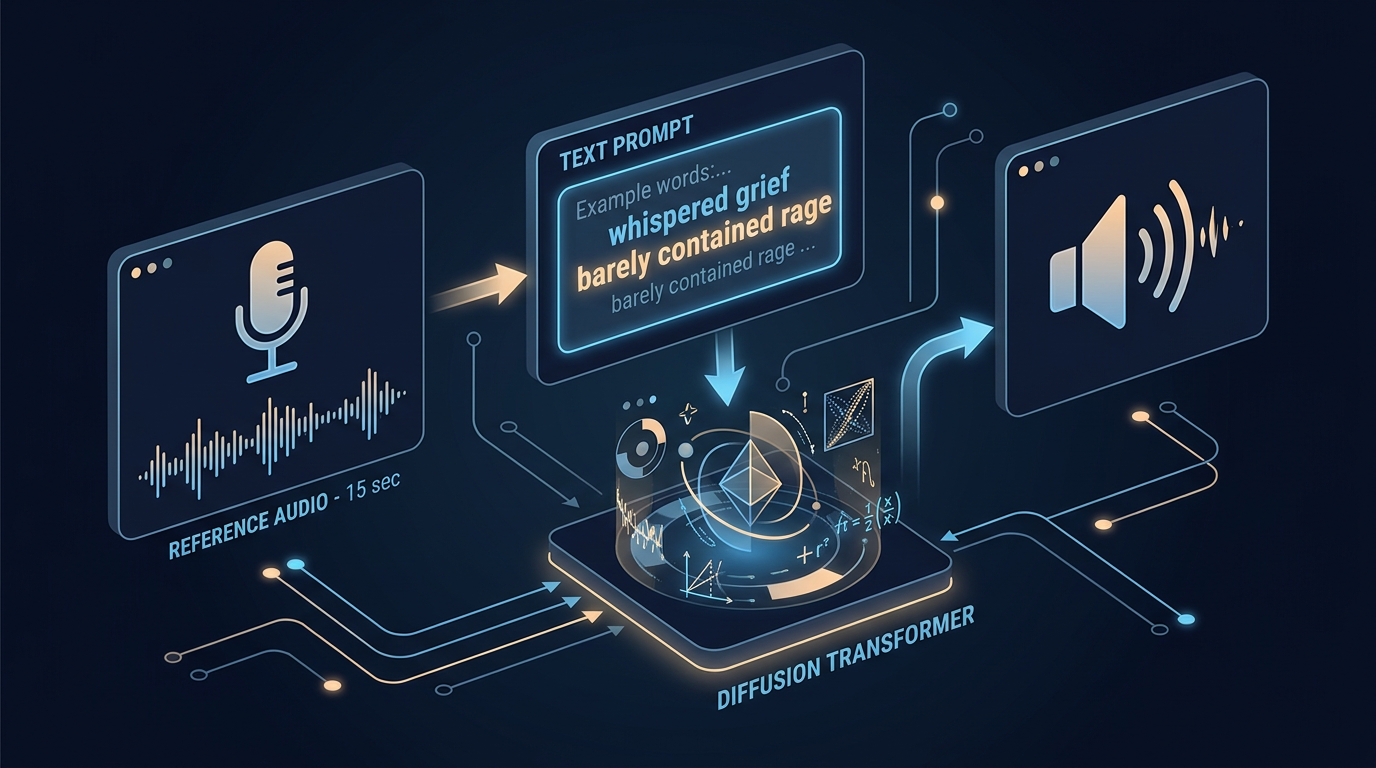
Hva er de tekniske kravene?
Scenema Audio er ikke en liten modell. Den er trukket ut av et 22-milliard parameter audiovisuelt system, og det merkes på VRAM-kravene.
Pipeline-arkitekturen er slik:
- Tekst splittes automatisk ved setningsgrenser
- Gemma 3 12B brukes som tekstenkoder – den forstår nyanser i promptbeskrivelsene
- 8-trinns diffusjonspipeline genererer audio
- SeedVC håndterer stemmeidentitetsoverføring fra referanseklippet
- MelBandRoFormer (vokal separasjon) brukes i etterkant
VRAM-kravene avhenger av hvilken presisjon du kjører:
- 16 GB VRAM: INT8 transformer + NF4 Gemma – fungerer, men er tregt
- 24 GB VRAM: Samme konfigurasjon, men raskere gjennomstrømming
- 48 GB VRAM: Full bf16-presisjon, beste kvalitet
Med andre ord: RTX 3090 eller 4090 er minstemålet for praktisk bruk. Har du 16 GB kan du teste, men for flyt i produksjon vil du ønske deg mer. Se gjerne på hva VoxCPM2 og OmniVoice krever for sammenligning – de to siste store open source TTS-utgiversleppene hadde lignende VRAM-behov.
Hvordan fungerer den emosjonelle promptingen?
Dette er der Scenema Audio skiller seg mest fra konkurrentene. I stedet for å velge «emosjon: glad» fra en nedtrekksliste, beskriver du leveransen i fri tekst – akkurat som du ville instruert en skuespiller.
Eksempler på prompter som faktisk fungerer:
- «Delivered with barely contained rage, voice trembling at the edge of control»
- «A child discovering something magical for the first time, breathless wonder»
- «Grief so heavy the words barely make it out, long pauses between phrases»
- «Dry corporate calm that doesn’t quite mask the panic underneath»
Gemma 3 12B – tekstenkoderen – er valgt nettopp fordi den forstår disse nyansene. En enklere tokenizer ville flattnet ut forskjellen mellom «hviskende redsel» og «rolig frykt». Med en 12-milliarder parametersmodell som enkoder har du langt mer ekspressiv kontroll enn de fleste TTS-systemer tilbyr.
Det som er verd å merke seg sammenlignet med DramaBox – som nylig ble publisert her – er at DramaBox bruker instruksjoner utenfor anførselstegn som reginotater, mens Scenema Audio bruker en separat performance-prompt helt løsrevet fra selve teksten. Begge løser det ekspressive problemet, men på forskjellige måter. DramaBox er kanskje mer intuitiv for folk som tenker «manus», mens Scenema Audio gir mer granulær kontroll over leveransen.

Lisens og tilgjengelighet
Koden er MIT-lisensiert – det vil si full frihet til kommersiell bruk, modifisering og distribusjon. Modellvektene er under LTX-2 Community License Agreement, som er noe mer restriktiv enn MIT men fortsatt tillater kommersiell bruk innen gitte rammer.
Dette er et bedre utgangspunkt enn mange kommersielle alternativer. ElevenLabs – det mest kjente voice cloning-verktøyet – koster fra rundt 200 kroner i måneden for basis voice cloning, og de dyrere planene for høyt volum kan komme opp i det mangedobbelte. Scenema Audio er gratis å kjøre lokalt hvis du har maskinvaren.
For de som vil prøve uten lokal GPU finnes den som en del av Scenema-plattformen på scenema.ai, med en gratis plan som gir 200 credits. Det er nok til å teste konseptet, men produksjonsbruk vil kreve et betalt abonnement.
Hvem er dette for?
Scenema Audio har åpenbare bruksområder for alle som jobber med innhold som trenger differensiert stemmelevering. Spillutviklere som trenger NPC-er med ekte emosjonell variasjon uten å booke skuespillere for hvert scenario. Podcastprodusenter som vil lage dramatiserte innslag. Audiobook-produksjon der man har én innleser men trenger variasjon i karakterer.
Det er også interessant i kombinasjon med lipsync-teknologi. Jeg skrev nylig om LipDub – open source lipsync bygget på LTX 2.3 – og det er ikke tilfeldig at begge er basert på samme audiovisuelle grunnmodell. Kombinert gir de deg en komplett pipeline: emosjonell tale med klonet stemme, deretter lipsync på karakter. Det begynner å ligne en fullstendig AI-filmstudio for dialog.
For de som er nysgjerrige på bredden av open source TTS-alternativene som har dukket opp det siste halvåret: Flare-TTS 28M er i den andre enden av skalaen – en 28 millioner parameter modell trent på 24 timer, veldig lett og rask. Scenema Audio er den tunge, ekspressive motpolen. De to fyller fundamentalt forskjellige behov.
Scenema Audio er ikke for alle – 16-24 GB VRAM er fortsatt en høy terskel for de fleste hjemmebrukere. Men for den som allerede har maskinen og jobber seriøst med lyd- eller videoproduksjon, er dette en av de mer gjennomtenkte arkitektoniske tilnærmingene til ekspressiv TTS som er sluppet som open source.







