

Innhold Vis
Flare-TTS 28M er en open source text-to-speech-modell trent fra bunnen av på én enkelt GPU – av én person, på 24 timer. Modellen er laget av LH-Tech-AI, bruker GlowTTS-arkitekturen via CoquiTTS-rammeverket, og er tilgjengelig på HuggingFace. Kun 28 millioner parametere. Støtter engelsk.
Det er ikke den beste TTS-modellen på markedet. Det vet skaperen godt. Men det er ikke poenget. Poenget er at en enkeltperson nå kan trene sin egen stemmemodell fra scratch – på hardware de fleste av oss faktisk har tilgang til. Det er ganske fascinerende, og verdt å forstå hva som gjør det mulig.
Her er hva Flare-TTS 28M er, hva det faktisk kan, og hva det forteller oss om hvor lett det er blitt å bygge AI-modeller selv.
Hva er Flare-TTS 28M?
Flare-TTS 28M er en text-to-speech-modell med 28 millioner parametere, trent på LJSpeech-datasettet – et klassisk engelsk lydkorpus med én enkelt stemme, cirka 24 timers innlesing. Treningsprosessen tok rundt 24 timer på en NVIDIA A6000 GPU, over cirka 300 epoker.
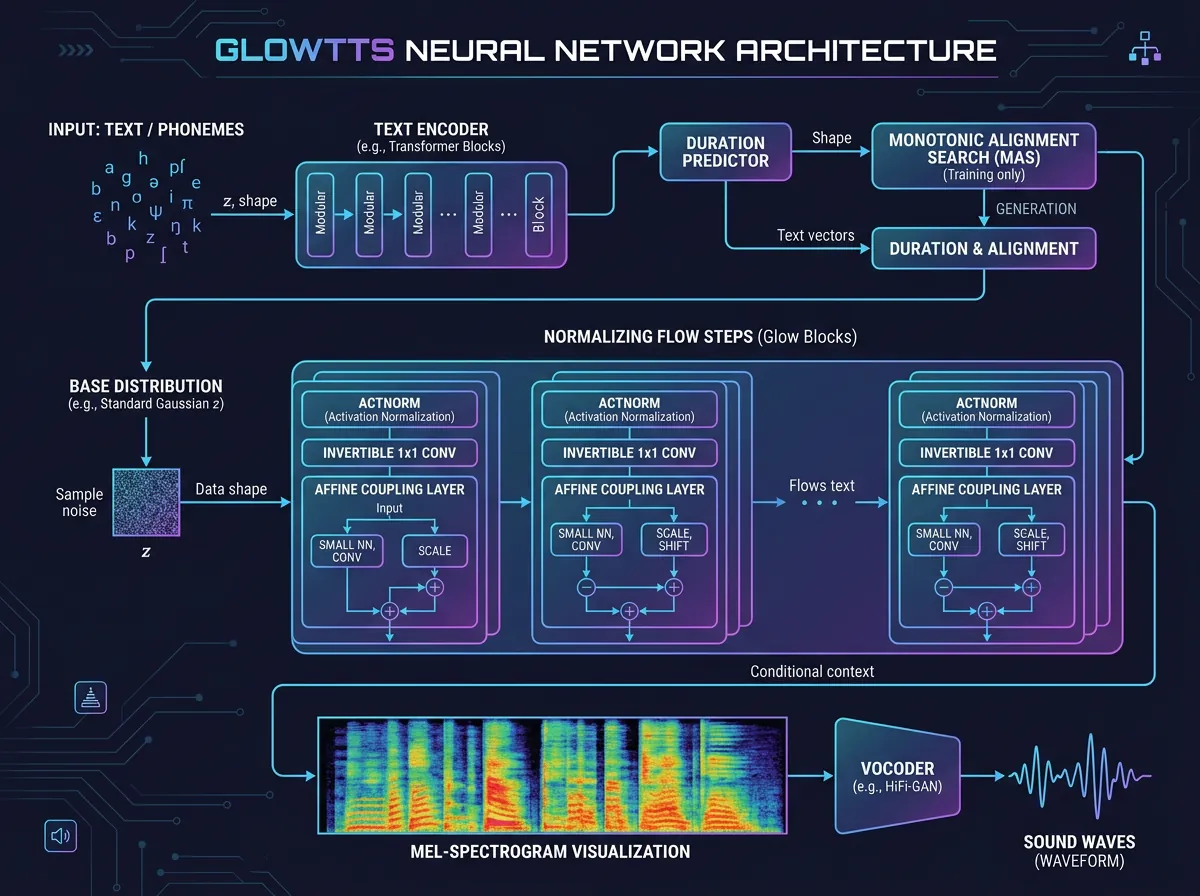
Arkitekturen er GlowTTS, en flow-basert modell som ble introdusert av Kakao Enterprise i 2020. GlowTTS er kjent for å generere tale raskt og stabilt sammenlignet med eldre arkitekturer – og den er godt dokumentert via CoquiTTS, det open source TTS-rammeverket som brukes her.
Resultatet? Forståelig engelsk tale. Litt robotaktig. Skaperen beskriver det selv som «okayish» og anbefaler det ikke til produksjon. Lytteeksempel finner du her – og det er ærlig nok.
Hva er GlowTTS, og hvorfor brukes det her?
GlowTTS er en normalizing flow-arkitektur for TTS. I praksis betyr det at modellen lærer å transformere tekst til mel-spektrogrammer (lydrepresentasjoner) gjennom en serie reversible transformasjoner. Fordelen er at du kan generere tale raskt uten autoregressive flaskehalser – du trenger ikke generere én lyd av gangen.
CoquiTTS er et open source bibliotek som gjør det mulig å bruke GlowTTS (og mange andre TTS-arkitekturer) uten å implementere alt selv. Du trener, du eksporterer en model.pth og config.json, og bruker den via CLI.
Treningskode følger med i repoet som start.sh og train.py – du kan altså laste ned og replikere hele prosjektet selv. Det er noe av det mest verdifulle her: transparens. Du ser nøyaktig hva som er gjort.
Kan du kjøre Flare-TTS 28M lokalt?
Ja – og det er en av de store styrkene med dette prosjektet. Du trenger CoquiTTS installert, laster ned model.pth og config.json fra HuggingFace, og kjører:
tts --text "Hello world, this is my first trained TTS model." \
--model_path model.pth \
--config_path config.json \
--out_path output_1.wavMerk: Det er dokumentert en JSON-parseringsfeil i konfigfilen, så litt finjustering kan være nødvendig. Men prinsippet er rett frem. 28 millioner parametere er ingenting – dette er en modell du kjører komfortabelt på CPU om nødvendig.
Det finnes mange interessante TTS-alternativer i dette rommet allerede. Jeg har tidligere skrevet om VoxCPM2 og OmniVoice, to open source TTS-modeller med imponerende funksjonalitet – OmniVoice støtter over 600 språk og nullskuddsstemmekloning. Flare-TTS er ikke i nærheten av det, men prosjektet handler om noe annet: å lære og vise at du kan gjøre det selv.
Hva sier dette om tilstanden til open source AI?
Det som slår meg er ikke kvaliteten på modellen – det er at én person, med én GPU, kan trene en fullstendig fungerende TTS-modell fra scratch på én dag. Det var utenkelig for noen år siden. Treningen krevde én NVIDIA A6000 – det er riktignok ikke billig hardware, men en A6000 koster rundt 8 000-10 000 dollar brukt. Sammenlignet med hva det kostet å bygge tilsvarende systemer for fem år siden, er dette ingenting.
Open source TTS-landsskapet har eksplodert de siste to årene. Pocket TTS er et godt eksempel på lokale TTS-løsninger som faktisk fungerer i praksis. Og vi ser nå at Cohere Transcribe slo OpenAI Whisper på ASR-benchmarks – talen er tosett med åpen teknologi i begge retninger. Stemme inn, stemme ut – alt lokalt.
Flare-TTS v2 er allerede planlagt av skaperen. Med mer data, lengre trening og muligens en mer avansert arkitektur vil resultatet sannsynligvis bli betraktelig bedre. Det er interessant å følge prosjektet videre.

Er Flare-TTS 28M verdt å prøve?
Avhenger helt av hva du vil med det. Til produksjon – nei. Det sier skaperen selv. Men som læringsressurs eller utgangspunkt for eget eksperiment? Absolutt. Treningskoden er tilgjengelig, datasettet er offentlig, og arkitekturen er veldokumentert.
Hvis du vil ha lokal TTS som faktisk fungerer til daglig bruk, er VoxCPM2 og OmniVoice bedre valg i dag. Vil du lære hvordan TTS-modeller fungerer og bygges fra bunnen av, er Flare-TTS 28M et ypperlig utgangspunkt – åpen kode, ærlig dokumentasjon, og en skapers vilje til å dele noe som ikke er ferdig ennå.
Det er det åpen kildekode handler om. Du trenger ikke være ferdig for å dele. Det er nok å vise at noe er mulig.







