

Innhold Vis
Cohere Transcribe er en ny open-source tale-til-tekst-modell lansert 26. mars 2026. Med bare 2 milliarder parametere er den skreddersydd for deg som vil kjøre lokal transkripsjon på vanlig forbrukerhardware – uten å betale per minutt til en skybasert tjeneste. Modellen støtter 14 språk og er allerede rangert som nummer én for nøyaktighet på Hugging Faces Open ASR Leaderboard.
Automatisk transkripsjon har lenge vært dominert av OpenAI Whisper – en solid modell som mange fortsatt bruker i alt fra podkastproduksjon til møtereferater. Men Whisper er ikke alltid den raskeste løsningen, og nøyaktigheten varierer med dialekt og støyforhold. Cohere Transcribe er et direkte forsøk på å slå Whisper på begge fronter, med en modell som er liten nok til å kjøre på din egen maskin.
Apache 2.0-lisens betyr full kommersiell bruk, ingen strenger. Modellen er tilgjengelig på Hugging Face under navnet cohere-transcribe-03-2026.
Hva er Cohere Transcribe?
Cohere Transcribe er en ASR-modell (Automatic Speech Recognition) bygget fra bunnen av – ikke finjustert på toppen av noe annet. Arkitekturen kombinerer en stor Conformer-encoder som trekker ut akustiske representasjoner fra lyd, koblet med en lettere Transformer-dekoder som produserer tekst-tokens. Inndata er log-Mel spektrogram, noe som er standard for lydmodeller av denne typen.
2 milliarder parametere er ganske lite for en modell som gjør krav på å toppe leaderboards. Til sammenligning har Whisper Large v3 – som Cohere benchmarker mot – 1,5 milliarder parametere. Cohere har altså laget en modell litt større enn Whisper Large, men med markant bedre ytelse ifølge egne tall.
Gjennomstrømmingen er imponerende: 525 minutter lyd prosessert per minutt. Det betyr at en times meeting-opptak er transkribert på under to minutter. For den størrelsesklassen modellen er i, hevder Cohere dette er best-in-class.
Hvem slår Cohere Transcribe?
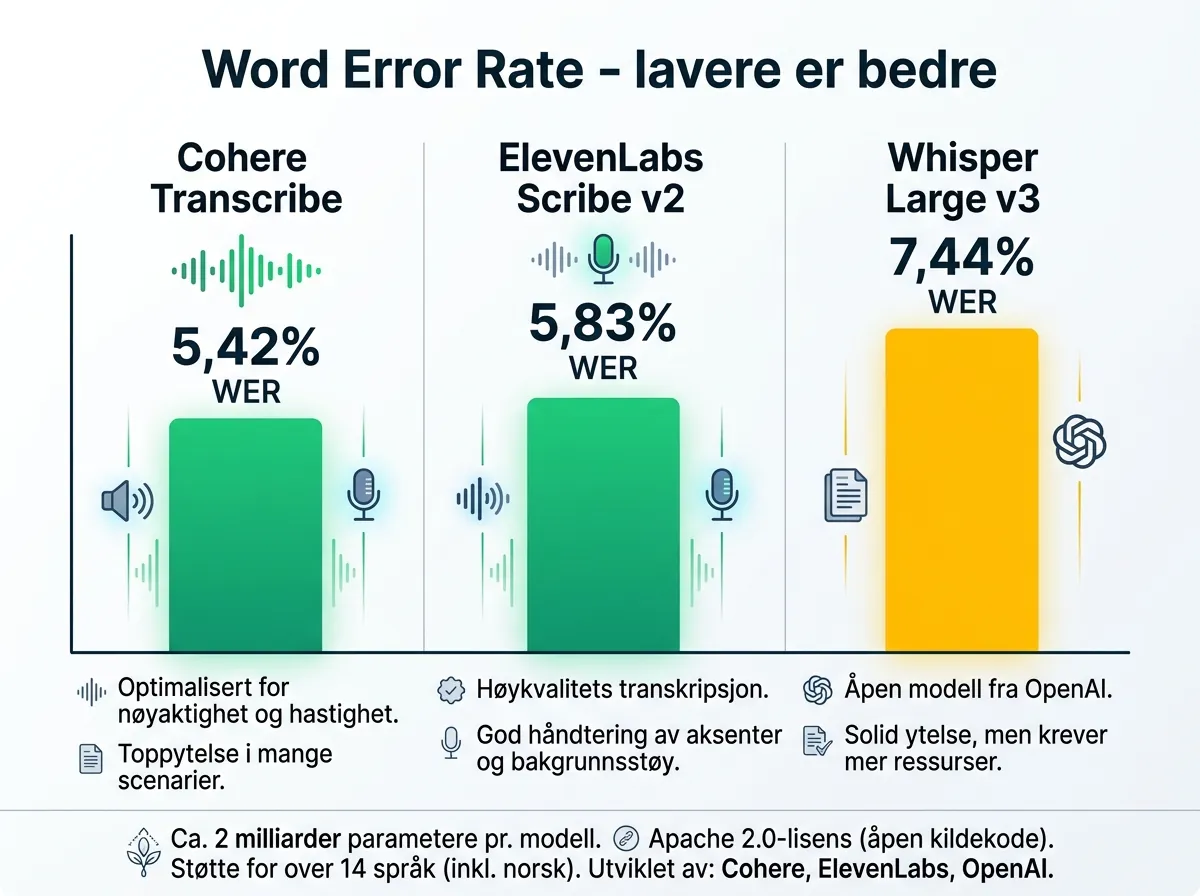
På Open ASR Leaderboard oppnår modellen en gjennomsnittlig Word Error Rate (WER) på 5,42%. Lavere er bedre – jo lavere WER, jo færre ord er transkriberte feil.
- Cohere Transcribe: 5,42% WER (rangert #1)
- ElevenLabs Scribe v2: 5,83% WER
- OpenAI Whisper Large v3: 7,44% WER
- IBM Granite 4.0 1B: dårligere
- Zoom Scribe v1: dårligere
I parvise menneskelige evalueringer (der folk valgte mellom to transkripsjoner uten å vite hvilken modell som lagde dem) vant Cohere Transcribe 61% av sammenligningene. Innen enkeltspråk: italiensk 60% vinnrate, japansk hele 70%. Modellen sliter imidlertid med portugisisk, tysk og spansk sammenlignet med rivalene – noe Cohere åpent innrømmer.
Det er verdt å merke seg at dette er Coheres egne benchmarks. Ikke akkurat upartisk kilde. Men WER på Open ASR Leaderboard er et uavhengig mål, og det er vanskelig å triksle seg til en #1-plassering der uten at det faktisk fungerer.
Hvilke språk støttes?
14 språk per lansering:
- Europeisk: Engelsk, fransk, tysk, italiensk, spansk, portugisisk, gresk, nederlandsk, polsk
- Asiatisk: Kinesisk, japansk, koreansk, vietnamesisk
- MENA: Arabisk
Norsk er ikke på listen. Det er litt irriterende for oss, men heller ikke overraskende – norsk er et lite språk og en nisje selv blant transkripsjonssystemer. Vil du ha god norsk transkripsjon med dialektstøtte, er NB-Whisper fortsatt det beste alternativet – spesialbygget av Nasjonalbiblioteket med norsk lyddata.
Hvordan bruker du Cohere Transcribe?
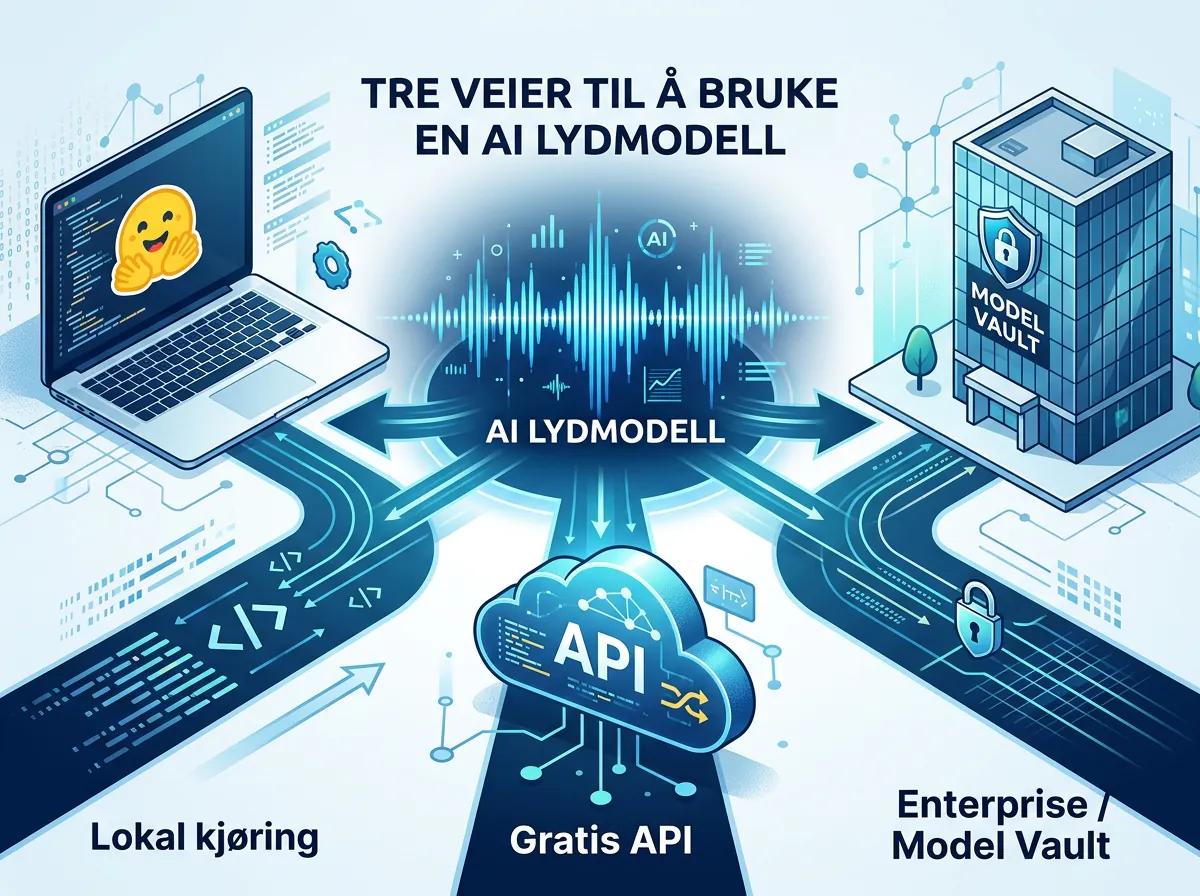
Tre veier til modellen:
1. Hugging Face (lokal kjøring): Last ned modellen CohereLabs/cohere-transcribe-03-2026 og kjør den selv. Krever en forbrukerkvalitets-GPU – Cohere sier ikke eksakt hvor mye VRAM, men 2B parameter-modeller pleier å gå greit på 8-10 GB VRAM med kvantisering.
2. Cohere API (gratis eksperimentering): Cohere tilbyr modellen via sitt API uten kostnad, med hastighetsbegrensning. For testing og eksperimentering er dette den enkleste veien inn.
3. Model Vault (produksjon): Coheres enterprise-tilbud gir lavlatens privat sky-inferens uten at du trenger å drifte infrastrukturen selv. Prismodell basert på tidsinstanser.
For de fleste vil API-ruten eller lokal Hugging Face-modell være mest relevant. Og med Apache 2.0-lisens kan du integrere dette i hva som helst – kommersielle produkter inkludert.
Er dette bedre enn Whisper for hjemmebruk?
Whisper har vært standarden for lokal transkripsjon siden OpenAI slapp den i 2022. Den er god, godt testet, og det finnes en hel industri av verktøy bygget rundt den. Men Cohere Transcribe ser ut til å gjøre jobben raskere og mer nøyaktig – i alle fall på de 14 støttede språkene.
525 minutter audio per minutt er egentlig ganske vilt. Det tilsvarer at du kan transkribere en hel arbeidsdag med lydopptak på under to minutter. For podkastprodusenter, journalister, eller folk som lager møtereferater er det en markant forbedring i arbeidsflyten.
Det som gjenstår å se er hvordan den presterer i praksis med støy, uklart snakk og overlappende stemmer – de virkelig vanskelige situasjonene der enhver transkripsjonmodell sliter. Benchmarks måler gjerne ideelle forhold.
Cohere planlegger å integrere Transcribe i sin enterprise-plattform North, som er en AI-agentorkestreringsplattform. Det antyder at de ser transkripsjon som en byggeblokk i større automatiserte arbeidsprosesser, ikke bare et stand-alone verktøy.
Hva tenker du – er 14 språk nok til å gjøre dette relevant for deg? Og er du glad for at NB-Whisper finnes for dem av oss som trenger norsk? Skriv gjerne i kommentarfeltet.







