

Innhold Vis
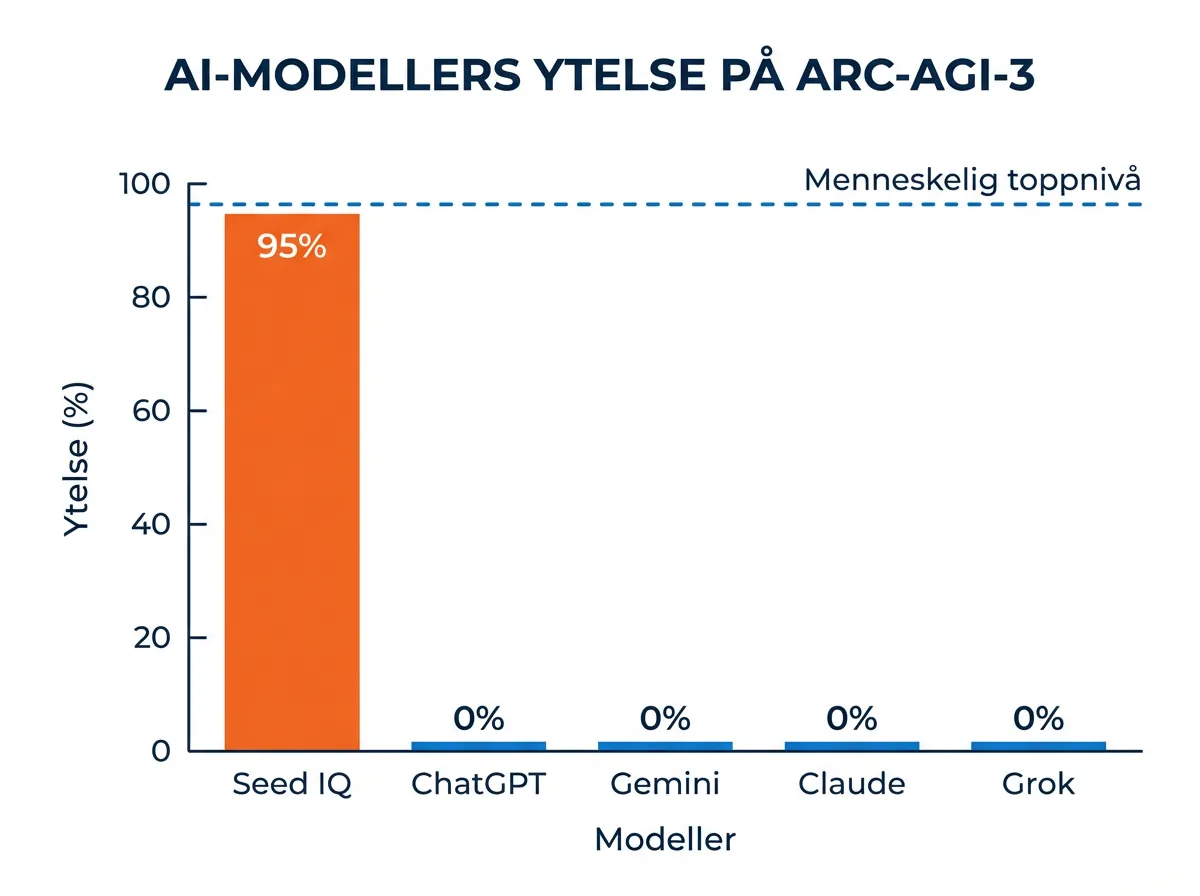
ARC-AGI-3 ble lansert 25. mars 2026 – og allerede samme dag kunngjorde et lite team bak et system kalt Seed IQ at de hadde løst alle syv spillene i benchmarken med en score på 95% relativt til det nest beste mennesket. ChatGPT, Gemini, Grok og Claude fikk alle score null. Det er verdt å stoppe opp ved.
Jeg har fulgt ARC-benchmarkserien siden ARC-AGI-1. Det er en av de få testene jeg faktisk synes gir mening – fordi den ikke måler hva du har memorisert, men om du kan generalisere til ukjente problemer på en menneskelignende måte. Ideen til François Chollet: oppgavene skal være lette for mennesker, men harde for AI. Og ARC-AGI-3 introduserer noe nytt igjen – dynamiske spill med bevegelige objekter, adaptiv kompleksitet og tidsbegrenset interaksjon.
Men før jeg skriver dette som en triumf, er det et par ting vi bør snakke om. Seed IQ er ikke en LLM. Scoringsmetoden er litt uvanlig. Og en tidligere OpenAI-forsker peker på reelle svakheter i selve benchmarken. Så la oss ta det fra begynnelsen.
Hva er ARC-AGI-3?
ARC-AGI-serien er utviklet av ARC Prize, organisasjonen bak AGI-benchmark-initiativet startet av François Chollet (tidligere Google, nå Zapier). Hele premisset er å lage tester der AI ikke kan «jukse» ved å gjenkjenne mønstre fra treningsdata – fordi oppgavene er designet til å kreve fluid intelligens, ikke memorisering.
ARC-AGI-1 brukte visuelle sekvenser der du måtte finne regelen og fullføre mønsteret. ARC-AGI-2 skrudde opp kompleksiteten. ARC-AGI-3 gjør noe annet igjen: det er dynamiske spill der du styrer en karakter gjennom syv nivåer med stigende vanskelighetsgrad. Objekter beveger seg. Reglene endrer seg. Kameraet er begrenset. Du må planlegge fremover og tilpasse deg underveis.
De beste LLM-ene – inkludert GPT-5.2, Claude Opus 4.5 og Gemini – klarer ifølge den offentlige leaderboarden bare rundt 105 handlinger og scorer null poeng. Det er ikke en liten gap. De klarer bokstavelig talt ikke å komme i gang.
Hva er Seed IQ – og hvordan virker det?
Seed IQ er ikke en stor språkmodell. Det er et multi-agent-system basert på noe de kaller «topologisk persepsjon» og «adaptiv multi-agent autonom kontroll» (AMAAC). Ideen er at hvert nivå av spillet håndteres av forskjellige agenter – én for langsiktig planlegging, én for kortsiktig navigasjon, én for persepsjonstracking av objekter, og så videre.
Det kritiske poenget er at Seed IQ ikke er trent på disse spillene. Ifølge demoen bygger systemet en verdensmodell på direkten, mens det spiller. Hvis kartet endrer seg, rekonstruerer det forståelsen sin i sanntid. Det prøver en strategi, det feiler, nullstiller og finner en ny vei. På nivå syv – som beskrives som det vanskeligste fordi kameraet er begrenset og du bare ser deler av verden om gangen – løser Seed IQ det uten problemer fordi det allerede har akkumulert kunnskap fra de seks foregående nivåene.
Det er faktisk ganske elegant. Ikke fordi det er noe magi, men fordi det er et annet paradigme enn det LLM-er er bygget på.
Hva betyr 95% score egentlig?
Her er noe jeg måtte lese to ganger. 95% er ikke en absolutt score – det er en relativ score beregnet mot det nest beste menneskets ytelse. Formelen er (1/1,026)² = 0,95. Det betyr at Seed IQ brukte 1,026 ganger så mange handlinger som det nest beste mennesket for å fullføre spillene. Altså omtrent 2,6% mer enn det beste alternativet på leaderboarden.
Til sammenligning: Seed IQ kom inn på 681 handlinger totalt. Beste menneskescore var 548 handlinger. Ikke identisk, men i samme størrelsesorden – og dramatisk bedre enn de beste AI-agentene fra større laboratorier som sto på null.
Jeg synes det er ærlig å presentere det slik. Det er ikke «AI slår mennesker». Det er «AI presterer på menneskelig nivå, definert som innenfor en viss margin av den nest beste menneske-scoreren». Det er en rimelig definisjon, og det er mer nyansert enn «95% score» høres ut ved første lesning.
Er benchmarken selv troverdig?
Her blir det interessant. En tidligere OpenAI-forsker som jobbet på OpenAI Five – prosjektet som slo Dota 2-verdensmestere – og som er konkurransekoder, har pekt på det han mener er alvorlige svakheter og bias i ARC-AGI-3.
Jeg har ikke fullstendig tilgang til kritikken hans i detalj, men premisset er kjent fra alle benchmark-diskusjoner: det er alltid mulig å optimere mot en spesifikk test uten å faktisk løse det underliggende problemet testen prøver å måle. Dette er noe jeg har skrevet om tidligere – benchmarks er krydder, ikke hovedrett.
Spørsmålene som bør stilles om enhver slik resultat:
- Ble systemet trent på lignende spill? Eller er det virkelig generalisering?
- Ble kompleksiteten på spillene justert etter at de første resultatene ble kjent?
- Kan resultatene verifiseres uavhengig?
- Hva er den faktiske transferability til andre oppgaver utenfor disse spillene?
I demoen nevnes det at ARC Prize-teamet faktisk økte kompleksiteten på spillene like etter at Seed IQ scoret 12% på den opprinnelige versjonen. Den beste agenten fra ARC Prize-teamet selv gikk fra 12% ned til 0,25% etter kompleksitetsøkningen. Seed IQ holdt stand. Det er interessant, men det er også akkurat det slags detaljer som gjør slike resultatpåstander vanskelig å vurdere fra utsiden.
Hva skiller Seed IQ fra LLM-er på denne typen oppgaver?
Store språkmodeller er designet for sekvensielle tekst-til-tekst-transformasjoner. De er ikke bygget for sanntids persepsjon av dynamiske verdener, korrigering av strategi midt i et spill, eller akkumulering av episodisk kunnskap på tvers av syv nivåer med progressive miljøendringer.
Det er ikke en feil ved LLM-er – det er bare ikke det de er laget for. Og det er kanskje det mest interessante poenget her. ARC-AGI-3 ser ut til å måle noe LLM-er er fundamentalt dårlige på, mens Seed IQ er spesifikt designet for akkurat det. Det sier noe om hva slags kapabiliteter vi faktisk trenger for å komme nærmere generell intelligens.
Jeg har skrevet om ARC-AGI-2-resultater for GPT-5.2 – der scorer modellen 52,9%. Det høres bra ut. Men ARC-AGI-3 er en helt annen oppgavetype. Å sammenligne de to scoreene direkte gir lite mening, fordi de måler forskjellige ting.
Hva betyr dette for AGI-diskusjonen?
Jeg er forsiktig med å trekke for store konklusjoner. Seed IQ er et lite team med en interessant arkitektur som presterer godt på en spesifikk benchmark på lanseringsdagen. Det er ikke det samme som «vi har nådd AGI».
Men det peker på noe reelt: det finnes tilnærminger til AI som ikke er basert på å skalere transformere-arkitekturer med flere parametere og mer data. Topologisk persepsjon, aktiv inferens, og multi-agent systemer med lokal verdensmodell-bygging er genuint interessante alternativer.
Hele diskusjonen minner meg om hva som skjedde med sjakk. Deep Blue slo Kasparov. Så kom AlphaZero og slo alle tidligere tilnærminger med en helt annen metode. Og nå er det programmer som spiller sjakk på måter ingen av oss hadde forutsett. Generell intelligens vil sannsynligvis ikke komme fra én enkelt arkitektur – men fra en kombinasjon av tilnærminger, der ARC-AGI-serien er en av de beste testene vi har for å finne ut hva som faktisk mangler.
Seed IQ-resultatet er verdt å følge med på. Ikke fordi det beviser noe endelig, men fordi det er det riktige eksperimentet. Og det er sjelden man kan si det om AI-benchmarks anno 2026.
Jeg har linket til Seed IQ-demovideoen hvis du vil se systemet i aksjon – det er faktisk ganske fascinerende å se det navigere nivå syv med begrenset kamerasyn. Hva tenker du – er dette den typen benchmark som faktisk sier noe meningsfullt om AI-kapabiliteter?







