

Innhold Vis
Open source AI er i ferd med å endre maktbalansen i kunstig intelligens. Der det for to år siden var et klart hierarki – GPT-4 på toppen, open source et stykke bak – er bildet i 2026 langt mer nyansert. Llama 4, Qwen3, Mistral Small 4 og DeepSeek konkurrerer med lukkede modeller på de fleste benchmarks. Og viktigere: de kjører på hardware du allerede eier.
Jeg har fulgt open source AI siden Stable Diffusion 1 tok verden med storm i 2022. Det som begynner som hobbyprosjekter i kjellerne til entusiaster, ender gjerne som industristandard to år senere. Open source AI følger samme mønster – bare raskere.
Denne guiden dekker hele landskapet: hva begrepene faktisk betyr, hvilke modeller som er verdt å prøve, hvordan du kjører dem lokalt, og hva alt dette betyr for deg som privatperson eller bedrift i 2026.
Hva betyr egentlig «open source» i AI?
Begrepet brukes løst, og det er verdt å rydde opp. Det finnes tre hovedkategorier:
Proprietært betyr at selskapet beholder full kontroll. GPT-4o, Claude 4.6, Gemini Ultra – du bruker dem via API eller chat-grensesnitt, men vet ingenting om vektene, treningsdataen eller arkitekturen. Alt skjer på selskapets servere.
Open weights betyr at modellvektene (selve «hjernen») er offentlig tilgjengelige, men kildekoden og treningsdataen kan fortsatt være lukket. Meta’s Llama-serie er det tydeligste eksempelet. Du kan laste ned og kjøre modellen, men Meta deler ikke alt om hvordan den ble trent.
Ekte open source betyr at alt er åpent: vekter, kildekode, treningsdata og arkitekturvalg. Det finnes overraskende få AI-modeller i denne kategorien. BLOOM og Falcon er eksempler, men de fleste «open source» AI-modeller er egentlig open weights.
I praksis snakker nesten alle om open weights når de sier «open source AI». Og for deg som bruker? Det spiller liten rolle. Det viktige er at du kan laste ned modellen og kjøre den lokalt – uten å sende dataen din til et selskap i USA eller Kina.
Hvilke open source-modeller er best i 2026?
Landskapet har eksplodert. Her er de viktigste familiene du bør kjenne til:

Llama (Meta) er den uoffisielle standarden. Llama 4 Scout og Maverick, lansert i 2026, holder seg godt mot proprietary-konkurrentene på de fleste oppgaver. Apache 2.0-lisens, som betyr full kommersiell bruk uten lisensavgifter. Finnes i størrelser fra 8B til 400B+ parametere. Støttes av nesten alle kjøringsverktøy.
Qwen (Alibaba) er imponerende på teknisk nivå. Qwen3.5 122B bruker Mixture-of-Experts arkitektur, der bare 10 milliarder parametere er aktive om gangen – det gir god ytelse uten at det krever monster-hardware. Kinesisk opprinnelse gjør at noen er skeptiske til databehandling og tilbakedører, noe jeg forstår. For lokal kjøring der ingen data forlater maskinen din, er det derimot et mye mindre problem. GGUF-versjoner fra Unsloth gjør dem enkle å kjøre via Ollama og LM Studio.
Mistral (europeisk) er det naturlige valget for de som vil ha GDPR-trygg open source AI med europeisk opprinnelse. Mistral Small 4 er en 119B MoE-modell med Apache 2.0-lisens som kombinerer reasoning, multimodal og koding i ett. 40% lavere latency og 3x høyere throughput enn forgjengeren. Parisisk opprinnelse gjør det til et naturlig valg for europeiske bedrifter.
DeepSeek (Kina) slo verden i januar 2025 og viser tegn på å fortsette. DeepSeek R1 og V3 konkurrerer med GPT-4 til en brøkdel av treningskostnaden. MIT-lisens. Samme Kina-skepsis som for Qwen gjelder her – og begge selskaper er underlagt kinesisk etterretningslov. For lokal kjøring uten nettforbindelse er risikoen annerledes enn via cloud-API.
GLM-5 (Tsinghua University) er en av de nyere utfordrerne. GLM-5 med 744 milliarder parametere utfordrer Claude Opus 4.6 på avanserte oppgaver og er lisensiert for kommersiell bruk. Et tegn på at akademisk open source AI holder seg relevant.
Hva trenger du av hardware?
Her er den ærlige sannheten: du trenger ikke en superdatamaskin for å kjøre open source LLM-er. Men du trenger å vite hva du går til.
VRAM er flaskehalsen. En typisk 7B-modell krever 8GB VRAM for full ytelse. En 13B-modell trenger 16GB. For 70B+ modeller trenger du enten 48GB+ VRAM (RTX 6000 Ada eller to RTX 3090 i SLI) eller RAM-offloading som er markant saktere.
Apple Silicon (M1/M2/M3/M4) er overraskende bra fordi unified memory fungerer som VRAM. En Mac Studio med 192GB unified memory kan kjøre modeller som tidligere krevde datacenter-hardware. Og MLX-rammeverket gjør Apple Silicon 50% raskere enn llama.cpp på tilsvarende hardware.
Kvantisering løser mye. En 70B-modell kvantisert til Q4 tar rundt 40GB – kjørbart på to RTX 3090. Q8-kvantisering gir nær full kvalitet på halvparten av minnebruken. Dette er grunnen til at GGUF-format (brukt av llama.cpp, Ollama og LM Studio) er blitt de facto standard for lokal kjøring.
Verktøy for å kjøre modeller lokalt
Du trenger ikke skrive en linje kode for å komme i gang. Her er de tre viktigste verktøyene:
Ollama er den enkleste inngangen. Installer én kommando, kjør ollama run llama4, og du har en lokal AI-assistent. OpenAI-kompatibelt API betyr at alle verktøy som snakker med ChatGPT kan peke mot Ollama i stedet. Gratis, open source, støtter alle de viktigste modellene. Jeg har skrevet mer om Ollama og RTX 4090-oppsett hvis du vil dykke dypere.
LM Studio er for deg som vil ha et grafisk grensesnitt. Last ned appen, bla gjennom Hugging Face-kataloget direkte fra appen, klikk last ned, og kjør. Perfekt for nybegynnere. Fungerer på Windows, Mac og Linux. Inkluderer chat-grensesnitt og API-server rett ut av boksen.
vLLM er for produksjonsoppsett. Hvis du skal betjene AI til mange brukere, eller integrere i en pipeline som trenger høy gjennomstrømning, er vLLM standarden. Brukes av selskaper som kjører sine egne inference-cluster. Krever mer teknisk bakgrunn, men gir dramatisk bedre ytelse for serving-scenarioer.
For de fleste privatpersoner og småbedrifter: start med Ollama. Den har nesten null terskel og dekker 90% av brukstilfellene.
Open source video-AI – LTX Video og Sky Reels
Tekst-til-video er ikke lenger forbeholdt selskapene med milliarder av dollar i budsjett.
LTX Video 2 er etter min mening kongen av open source video-AI. Kjører lokalt på consumer GPU, genererer realistiske 2-5 sekunders klipp fra tekstbeskrivelse eller referansebilde, og er Apache 2.0-lisensiert. For enkle subject-baserte scener (en person, ett dyr, én bevegelse) er det production-ready. Jeg har brukt det til å animere stillbilder med svært gode resultater.
Sky Reels fra Kuaishou er et annet alternativ med sterk ytelse, særlig på naturscener og langsomme kamerabevegelser. Begge modellene er tilgjengelige via Hugging Face og kan kjøres lokalt med nok VRAM (typisk 16-24GB for god ytelse).
Begrensningen? Komplekse scenarioer med flere personer og koordinerte bevegelser er fortsatt utfordrende for open source video-modeller. Her holder de lukkede alternativene (Veo 3.1, Kling 2.3) et forsprang.
Open source transkripsjon: Whisper, NB-Whisper og Cohere
Whisper fra OpenAI, sluppet som open source i 2022, er fortsatt referansestandarden for lokal talegjenkjenning. Den er robust, støtter norsk, og kjører på CPU – om enn sakte. GPU-akselerert via faster-whisper er dramatisk raskere.
NB-Whisper er Nasjonalbibliotekets fine-tuning av Whisper på norsk tale. Hvis du transkriberer norske opptak – podcaster, møter, forelesninger – gir NB-Whisper markant bedre resultater enn standard Whisper, særlig for dialekter og faglig vokabular.
Cohere Transcribe er open source og slår Whisper på nøyaktighet ifølge uavhengige benchmarks. Apache 2.0-lisens, støtter 100+ språk, og har spesielt god ytelse på lange opptak med mye støy. Et sterkt alternativ for de som vil ha bedre enn Whisper uten sky-avhengighet.
Fordeler med open source AI
La meg være konkret om hva du faktisk får:
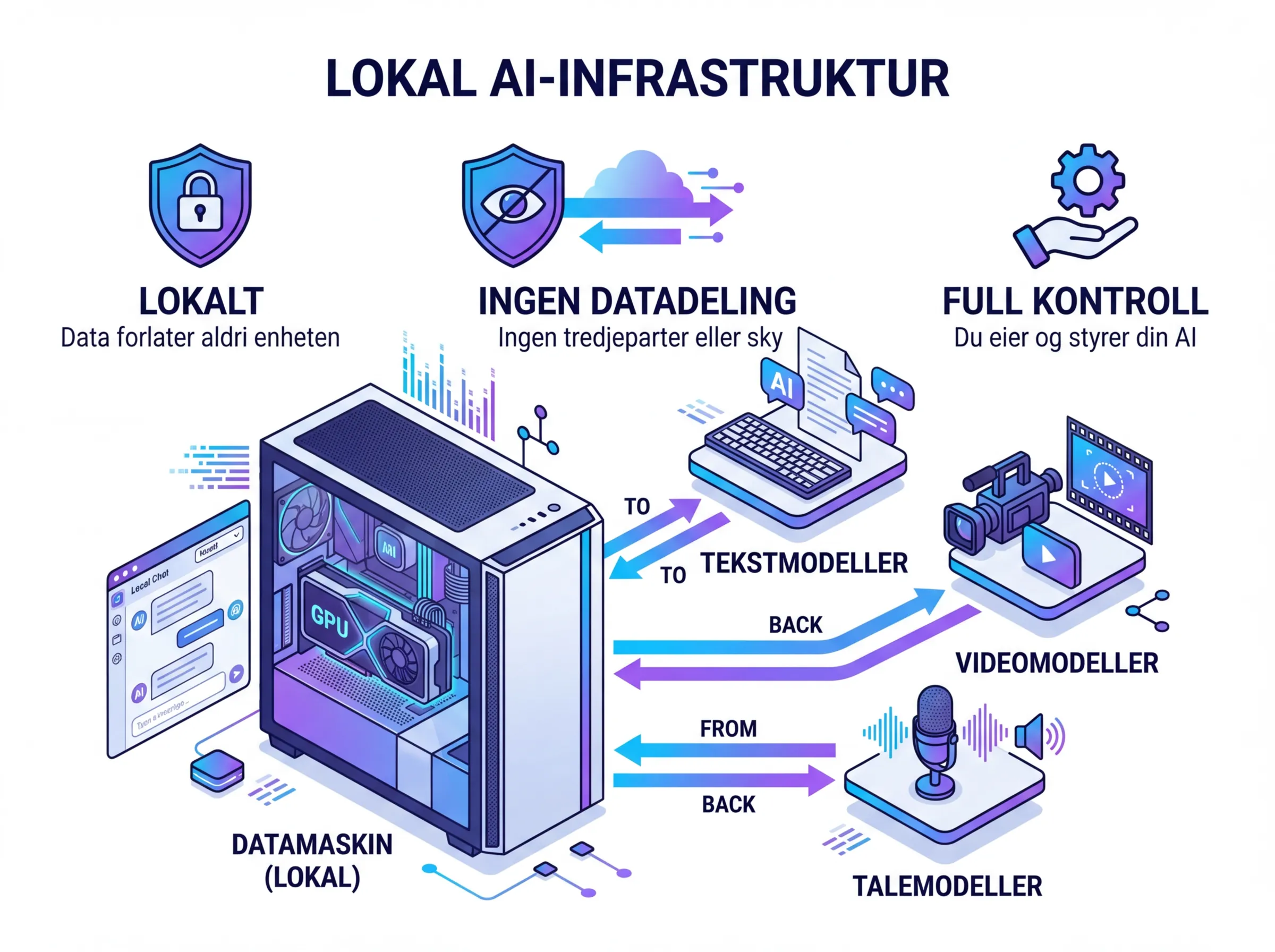
Personvern og datakontroll. Dataen din forlater aldri maskinen. For bedrifter som håndterer sensitiv kundeinformasjon, kontrakter, eller personopplysninger, er dette ikke bare en fordel – det er en GDPR-nødvendighet. Du trenger ikke gå gjennom databehandleravtaler, ikke bekymre deg for at et selskap bruker dataen til trening, ikke lure på hvem som leser loggene dine.
Kostnad på sikt. API-kostnader legger seg opp. ChatGPT Plus er rundt 200 kr i måneden per bruker. For en bedrift med 20 ansatte er det 48 000 kr i året – bare for én tjeneste. Lokal infrastruktur krever en engangs-investering, men marginalkostnaden per spørring er nær null.
Tilpasning. Du kan fine-tune open source-modeller på din egen data. Har du 10 000 kundedialoge? Fine-tune Llama på dem og få en modell som kjenner ditt produkt bedre enn noen generell AI-assistent. Det er ikke mulig med GPT-4o eller Claude (med mindre du betaler OpenAI/Anthropic for custom fine-tuning til svimlende priser).
Offline-drift. Ingen internettforbindelse nødvendig. Relevant for skip, oljeplattformer, jernbanetunneler – alle steder der nettforbindelsen er upålitelig eller for sensitiv til å sende data over.
En interessant teknisk nyvinning i dette rommet er TurboQuant – en open source komprimeringsalgoritme som gjør open source-modeller enda mer effektive på begrenset hardware. Kvantisering er det som gjør lokale modeller mulig for vanlige brukere, og verktøy som dette driver utviklingen fremover.
Ulemper du bør kjenne til
Ingen fullstendig guide uten ærlig diskusjon om baksiden:
Hardware-krav. Du trenger en brukbar GPU for god ytelse. En 7B-modell på CPU er treig nok til å irritere. For de beste resultatene trenger du minst en RTX 4060 (8GB VRAM). Det er en engangskostnad, men det er en kostnad.
Oppsett og vedlikehold. Ollama er enkelt, men det er fortsatt teknisk. Modell-oppdateringer, konfigurasjon, API-integrasjon – det krever noen timer å sette opp og vedlikeholde. Det finnes ingen kundestøtte å ringe.
Kvalitetsgap på toppen. For de aller mest avanserte oppgavene – kompleks kodeGenerering, lang kontekst, multistep-reasoning – holder de beste proprietære modellene (Claude 4 Opus, GPT-4o, Gemini Ultra) fortsatt et forsprang. Gapet krymper raskt, men det er der.
Ingen moderering. Det er et tveegget sverd. Open source-modeller uten moderering kan brukes til mer – men det betyr også at du selv er ansvarlig for at de ikke brukes til noe skadelig i din kontekst.
Open source vs lukkede modeller – hvem vinner?
Spørsmålet er feil formulert. De vinner på forskjellige arenaer.
Lukkede modeller (Claude, GPT-4o, Gemini Ultra) vinner på råytelse for de mest komplekse oppgavene, på integrasjon med andre skytjenester, og på brukervennlighet for ikke-tekniske brukere. Du åpner en nettleser og bruker dem.
Open source vinner på personvern, kostnad ved scale, tilpasning og frihet. Og noe som ofte glemmes: pålitelighet. Ingen API-nedetid, ingen prisendringer over natten, ingen plutselig politikk-endring som blokkerer din brukscase.
Det er ikke enten/eller. Jeg bruker Claude daglig for oppgaver som krever toppytelse og der personvern ikke er kritisk. For automatisering som kjører 24/7, for lokale agenter som leser sensitive filer, for eksperimentering – der er open source overlegen fordi det er billigere og mer kontrollerbart.
Nvidia Research har lansert AI-Q – en open source forskningsagent som topper DeepResearch-benchmarks. Når Nvidia, som tjener penger på at folk kjøper GPU-er for å kjøre AI, satser tungt på open source – er det et klart signal om hvilken retning markedet beveger seg.
Hva krever fellesskapet – og hvorfor det er viktig
Det er en pågående diskusjon om hva «open» faktisk skal bety i AI-kontekst. Da OpenAI pensjonerte GPT-4o og GPT-5.1, krevde fellesskapet at modellene ble frigitt som open source under Apache 2.0 eller MIT-lisens. Argumentet er enkelt: forskere og lærere som bygget systemer rundt disse modellene, mister grunnmuren under seg når modellene avvikles.
Dette berører noe fundamentalt. Proprietær AI skaper avhengigheter. Selskapet som kontrollerer modellen, kontrollerer hva du kan gjøre med den, til hvilken pris, og i hvilken grad. Open source AI – selv om «open source» som nevnt er et upresist begrep – gir brukere og utviklere langt mer kontroll over sin egen teknologistabel.
Det handler ikke om at OpenAI eller Anthropic er onde. Det handler om at avhengighet av en enkelt leverandør er en sårbarhet, enten du er en privatperson, en startup eller en offentlig institusjon.
Hva betyr dette for deg i praksis?
Vil du bare ha en enkel AI-assistent som ikke sender dataen til USA? Installer Ollama, last ned Llama 4 8B, og du har det på ti minutter.
Vil du bruke AI til å transkribere møter eller intervjuer? NB-Whisper lokalt er bedre enn mange skytjenester for norsk tale, og dataen forblir på din maskin.
Vil du generere bilder uten å betale per bilde? Stable Diffusion (og etterfølgerne) er fortsatt benchmark for lokal bildeGenerering. Flux.1 Dev er open weights og gir svært gode resultater.
Driver du en bedrift med sensitive data? Lokal LLM-infrastruktur er ikke lenger et «bare for geeks»-prosjekt. Det er en reell mulighet med rimelig teknisk terskel – spesielt med moderne verktøy som LM Studio.
Open source AI i 2026 er ikke en kompromissløsning. For mange brukstilfeller er det det riktige valget – uavhengig av hva proprietære selskaper hevder. Og landskapet forbedrer seg raskere enn noen hadde trodd mulig for to år siden.
Hva bruker du selv? Kjører du allerede noe lokalt, eller er du nysgjerrig på å prøve? Skriv gjerne en kommentar – jeg er alltid interessert i å høre hva folk faktisk bruker i praksis.








7 kommentarer