

Innhold Vis
Mistral Small 4 er en 119 milliarder parameter Mixture-of-Experts-modell lansert av Mistral AI 16. mars 2026. Den kombinerer tre separate spesialistmodeller – Magistral (reasoning), Pixtral (multimodal) og Devstral (agentic koding) – i ett enkelt API-endepunkt. Europeisk, Apache 2.0-lisensiert, og kan kjøres lokalt. Ingen norsk dekning ennå.
Det som gjør Small 4 interessant er ikke bare størrelsen eller benchmark-tallene – det er selve designfilosofien. I stedet for å tvinge deg til å velge mellom en rask chat-modell, en dedikert reasoning-modell og en koding-spesialist, samler Small 4 alt i én. Du sender en parameter med kallet og velger selv hvor mye kapasitet du trenger. Det er praktisk.
Og så er det europeisk. Mistral er Paris-basert, Apache 2.0-lisensiert, og modellen kan deployes lokalt. For norske bedrifter med GDPR-krav som sliter med «sender vi data til USA?»-spørsmålet, er det et argument som teller.
Hva er Mixture of Experts – og hvorfor betyr det noe?
119 milliarder parametere høres enormt ut, og det er det. Men MoE-arkitekturen gjør modellen langt mer praktisk enn tallet tilsier. Av de 128 ekspertene i modellen er bare 4 aktive per token – noe som betyr at effektiv beregning tilsvarer en 6,5 milliarder parameter tett modell.
Resultatet er at du får ytelsen til en stor modell til kostnadene til en liten. Mistral oppgir 40% lavere latency og 3x høyere throughput sammenlignet med Small 3 – noe som ikke er trivielt hvis du bygger systemer som håndterer mange forespørsler parallelt.
Til sammenligning var Mistral Small 3.2 en tett 24B-modell uten reasoning og uten multimodal støtte. Small 4 er ikke en inkrementell oppdatering – det er et annet dyr.
Hva er reasoning_effort – og hvorfor er det smart?
Den praktisk sett viktigste nyheten er reasoning_effort-parameteren. Du bestemmer selv hvor mye kapasitet modellen bruker:
- reasoning_effort=»none» – Rask, direkte svar. Tilsvarer Small 3.2-stilen.
- reasoning_effort=»high» – Dyp steg-for-steg resonnering. Tilsvarer det du tidligere fikk med Magistral.
Før dette måtte du vedlikeholde to separate modell-integrasjoner i koden din: én for daglige oppgaver, én for komplekse resonneringsoppgaver. Nå er det én. Det er den typen forenkling som faktisk gjør en forskjell i produksjonssystemer.
En benchmark-detalj verdt å merke seg: på AA LCR (logisk resonnering) oppnår Small 4 score 0,72 med 1 600 tegn output, mens konkurrentene når tilsvarende score med 5 800-6 100 tegn. Kortere output betyr lavere inferenskostnader – noe som direkte påvirker hva du betaler per API-kall.
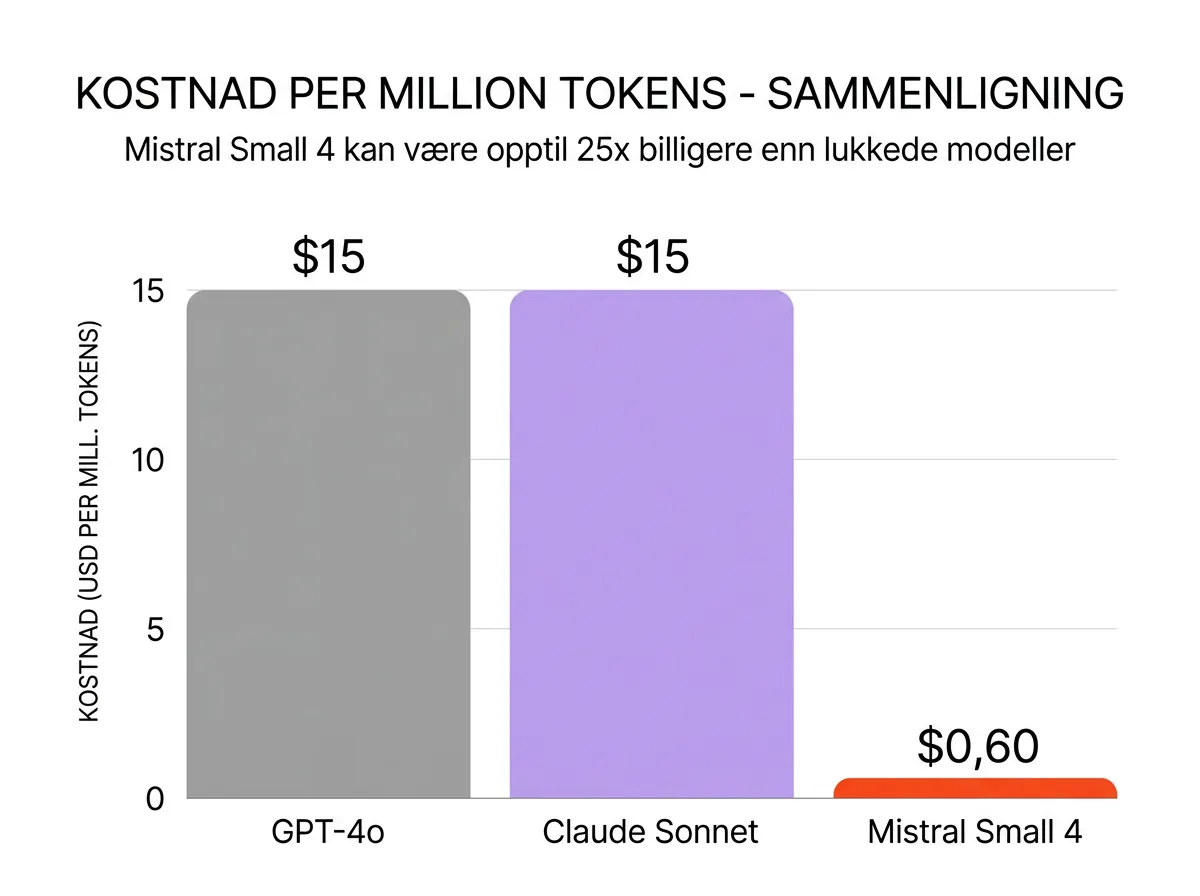
Hva koster Mistral Small 4 sammenlignet med GPT-4o og Claude?
Offisiell pris for Small 4 var ikke publisert på alle prisoversikter per 17. mars 2026, men Hacker News-diskusjoner nevner $0,60 per million output-tokens som et nøkkeltall. Sjekk Mistrals prissider for oppdaterte tall.
Sett opp mot lukkede modeller:
- GPT-4o: $5-15 per million output-tokens
- Claude 3.5 Sonnet/Haiku: $3-15 per million output-tokens
- Mistral Small 4 (estimert): $0,60 per million output-tokens
Det er en kostnadsdifferanse på 5-25x, avhengig av modell og brukstilfelle. For et selskap som prosesserer 10 millioner tokens i måneden, er det en månedlig besparelse på mellom 500 og 2 000 kroner – hvert eneste år. For systemer med høyere volum, mer.
Det er selvfølgelig ikke garantert at kvaliteten er identisk for alle brukstilfeller. Én Hacker News-kommentator testet og fant modellen god for enkle oppgaver, men utilstrekkelig for komplekse ting som query-generering og retrieval. Benchmarks er heller ikke alltid til å stole på – som en annen kommentator sa: «I really wish the benchmarks were even slightly trustworthy for AI models.» Ta dem med en klype salt og test selv.
For de som vil bruke Small 4 via OpenRouter, er OpenRouter-guiden et naturlig startpunkt – den forklarer hvordan du kobler deg til flere modeller gjennom ett API.
Er Mistral Small 4 et godt valg for GDPR-sensitive bedrifter?
Apache 2.0-lisensen betyr full kommersiell bruk uten restriksjoner. Modellen kan lastes ned og kjøres internt – ingen data sendes noe sted. For norske advokatfirmaer, regnskapsbyrå og helsevesen som ønsker AI-analyse av dokumenter uten å eksponere klientdata, er det relevant.
Mistral er Paris-basert og er et av få frontier AI-laboratorier utenfor USA og Kina. Den GDPR-vinkelen er reell, selv om «europeisk» ikke automatisk løser alle compliance-spørsmål. Du bør verifisere Mistrals Data Processing Agreement om du bruker API-versjonen.
Lokal deployment krever imidlertid seriøs hardware. Full modell på BF16 veier 242 GB – du trenger 4x NVIDIA H100 for produksjonskjøring, eller 2x H200 som minimum. For de fleste SMBer er GGUF-kvantiserte versjoner (tilgjengelig via Unsloth på HuggingFace) og 128 GB RAM det realistiske alternativet – men det er fremdeles enterprise-territorium.
API-veien er mer tilgjengelig. Da forblir data hos Mistral, men hos et europeisk selskap underlagt EU-regulering – noe mange norske bedrifter vil vurdere som akseptabelt sammenlignet med OpenAI og Google.

Slik kjører du Mistral Small 4 lokalt eller i skyen
Tilgjengelig via:
- HuggingFace: mistralai/Mistral-Small-4-119B-2603
- vLLM: Anbefalt servingrammeverk, custom Docker-image tilgjengelig (
mistralllm/vllm-ms4:latest) - NVIDIA NIM: build.nvidia.com – gratis prototyping
- LM Studio / llama.cpp: Via Unsloth GGUF-kvantiseringer
- Mistral API: Direkte via mistral.ai/news/mistral-small-4
For de som allerede bruker Ollama for lokale modeller, er GGUF-veien via LM Studio det mest naturlige startpunktet. Merk at Transformers-integrasjon krever en BF16 dequantization workaround inntil FP8-støtte er merget – se Mistrals offisielle lansering for oppdatert status.
Mistral er også grunnleggende medlem av NVIDIA Nemotron Coalition – en allianse av AI-laboratorier som co-utvikler frontier-modeller på DGX Cloud-infrastruktur. Det gir dem distribusjon via NVIDIAs enterprise-nettverk, noe som potensielt gjør Small 4 tilgjengelig gjennom flere kanaler fremover.
Reasoning-modeller i 2026 – en ny kategori
Det skjer noe interessant i landskapet av reasoning-modeller akkurat nå. Mercury 2 kom som verdens første reasoning diffusion LLM, og nå kommer Mistral med konfigurerbar reasoning i en open source-pakke. Tendensen er tydelig: reasoning er i ferd med å bli en standard-funksjon, ikke en premium-tillegg.
For praktiske formål betyr det at du snart ikke trenger å betale OpenAI o3-priser for å få modeller som «tenker seg om» på vanskelige problemer. Small 4 er et konkret eksempel på dette skiftet – og til en prislapp som er et sted mellom 5 og 25 ganger lavere enn de lukkede alternativene.
Én modell for chat, reasoning og bildeanalyse er et enkelt verdibidrag. Ingen «which AI model for which task»-fatigue. Du sender reasoning_effort="high" når du trenger det, "none" når du ikke gjør det, og betaler deretter. Det er egentlig ganske greit.








5 kommentarer