
Innhold Vis
Mistral Medium 3.5 er en ny 128 milliarder parameter-modell lansert av Mistral AI 29. april 2026. Den er åpen, veier 128B tette parametere (ikke MoE), har 256 000 tokens kontekstvindu – og kombinerer instruksjonsføling, reasoning og koding i ett enkelt sett med vekter.
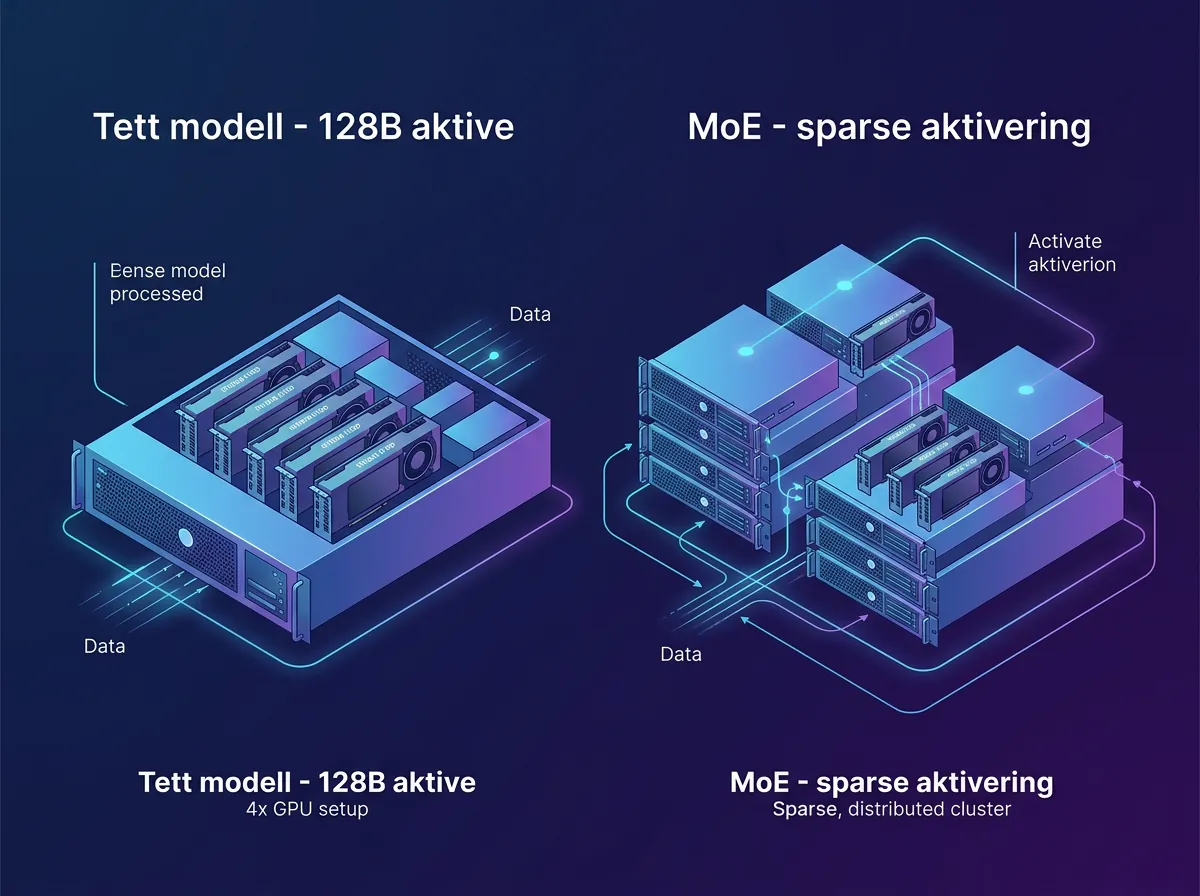
Det er et interessant trekk fra det franske AI-selskapet. De fleste store open source-modeller de siste månedene har vært Mixture-of-Experts (MoE), altså at modellen bare aktiverer en brøkdel av parameterne per token. Mistral Medium 3.5 er derimot en tett modell – alle 128 milliarder parametere er alltid aktive. Det gjør den mer forutsigbar å sette opp, men krever mer VRAM.
Lisensen er modifisert MIT – altså open weights med noen kommersielle begrensninger for veldig store selskaper. For de fleste er den fritt tilgjengelig via Hugging Face.
Hva er spesifikasjonene til Mistral Medium 3.5?
Her er de viktigste tallene ifølge Mistrals offisielle lansering:
- Parametere: 128 milliarder (tett arkitektur)
- Kontekstvindu: 256 000 tokens
- Modaliteter: Tekst og bilde (inn), tekst (ut)
- Lisens: Modifisert MIT – open weights
- API-pris: $1,50 per million input-tokens, $7,50 per million output-tokens
- Tensor-typer: BF16 og FP8
- Flerspråklig: 24 språk, inkludert norsk
Kontekstvinduet på 256k er ganske sjenerøst. Til sammenligning har Mistral Small 4 (119B MoE) 32 000 tokens. Medium 3.5 kan altså håndtere betydelig lengre dokumenter og mer komplekse agentic oppgaver i én kontekst.

Hva er Mistral Medium 3.5 god til?
Modellen er tydelig posisjonert mot koding og agentic bruk. Mistrals egne benchmarktall er:
- SWE-Bench Verified: 77,6% – sterkere enn Devstral 2 og Qwen 3.5 på denne testen
- τ³-Telecom: 91,4% – agentic benchmark for komplekse flerstegs-oppgaver
Mistral har også gjort den til standardmodellen i Vibe (deres kodings-IDE) og Le Chat (chatbot). Det sier noe om hvor de selv plasserer den – dette er ikke en eksperimentell Labs-modell, men en produksjonsklar flaggskipsmodell.
En funksjon jeg synes er interessant er konfigurerbar reasoning effort per forespørsel. Du kan sette reasoning_effort="high" når du trenger dyp analyse, og reasoning_effort="none" når du bare vil ha et raskt svar. Det gir fleksibilitet uten å måtte veksle mellom modeller.
Den støtter også native function calling med JSON-output og structured outputs – begge ting som er nyttig i automatiserings-pipelines som n8n.
Kan du kjøre Mistral Medium 3.5 lokalt?
Ja, men det er ikke for de med en enkelt RTX 4090. Minimumskravene for produksjonskjøring er fire GPU-er med høy VRAM:
- 4x NVIDIA H100 80GB, eller
- 4x NVIDIA H200 141GB
I FP8-presisjon trenger modellen ~128 GB VRAM bare til vektene, pluss overhead for KV-cache og kontekst. Med fire H100-er på 80 GB hver (320 GB totalt) har du akkurat nok rom til full produksjonsinferens med 256k kontekstvindu.
Det er altså self-hosting-territory for bedrifter og dedikerte hobbyister med serverinfrastruktur – ikke noe du stapper inn i Ollama på laptopen. Til sammenligning krever lokale modeller via Ollama betydelig lavere hardware. For de fleste er API-tilgang mer praktisk.
Hva koster Mistral Medium 3.5 – og er det verdt prisen?
Via API koster den $1,50 per million input-tokens og $7,50 per million output-tokens. For å sette det i perspektiv: Claude Sonnet ligger typisk på $3/$15 og GPT-4o på $5/$15. Mistral Medium 3.5 er altså rimeligere enn begge på input, og halvparten av GPT-4o på output.
Den spiser ikke opp Mistral Small 4 på pris – Small 4 er fortsatt betydelig billigere. Men Medium 3.5 retter seg mot oppgaver der du faktisk trenger den ekstra konteksten og kodeytelsen. Skal du kjøre lange kodereviews, komplekse flerstegs-agenter, eller dokumentanalyse over store filer, er gapet i kapabilitet større enn gapet i pris.
Jeg ser det som et fornuftig innspill i mellomsjiktet – mellom de raske, billige Small-modellene og de massive frontier-modellene som koster en formue per kall.
Tett modell mot MoE – hva er forskjellen i praksis?
Mistral har tidligere lansert modeller som Small 4 (119B MoE) der bare en liten del av parameterne aktiveres per token. MoE-arkitektur gjør modeller raskere å kjøre og rimeligere per token, men kan gi litt mer uforutsigbar oppførsel.
En tett modell som Medium 3.5 aktiverer alle 128 milliarder parametere for hvert token. Det gir typisk mer konsistent ytelse og gjør det enklere å forstå oppførselen. Ulempen er mer VRAM og høyere inferens-kostnad.
Valget mellom dem avhenger av brukscase: trenger du volum og hastighet, er MoE-modeller attraktive. Trenger du pålitelighet og konsistens i kode-generering og agentic oppgaver, er en tett modell som Medium 3.5 mer passende.
Den kan også sammenlignes med åpne alternativer som Llama, DeepSeek og andre open source-modeller i samme størrelsesklasse – men 256k kontekstvindu er spesielt i denne kategorien.
Alt i alt er dette en solid lansering fra Mistral. De leverer en modell som er sterk nok til enterprise-bruk, åpen nok til å self-hoste, og priset fornuftig for API-bruk. Om den klarer å bite noen markedsandeler fra Claude og GPT-4o i kode-segmentet gjenstår å se – men tallene peker i riktig retning.







