
Innhold Vis
SenseNova-U1 er en ny åpen kildekode-modell fra det kinesiske selskapet SenseTime, lansert 28. april 2026. Det som gjør den interessant er ikke at den genererer bilder – det kan de fleste modeller. Det interessante er hvordan den gjør det: uten VAE, uten separat visuell encoder, og uten diffusion-prosessen som alle andre bruker. Alt skjer i én samlet modell som behandler tekst og piksler nativt.
Tilnærmingen heter NEO-Unify, og det er en ganske radikal ombygging av måten multimodale modeller vanligvis fungerer på. I stedet for å sy sammen separate komponenter – én som forstår bilder, én som komprimerer dem, én som genererer – er hele kjeden integrert fra bunnen av. Modellen tilbys i to størrelser (8B og ~3B parametere) under Apache 2.0-lisens, som betyr at du kan bruke den kommersielt og kjøre den lokalt.
Men er dette et gjennombrudd eller markedsføring? La meg grave litt i hva som faktisk er nytt her.
Hva er problemet med diffusion-modeller?
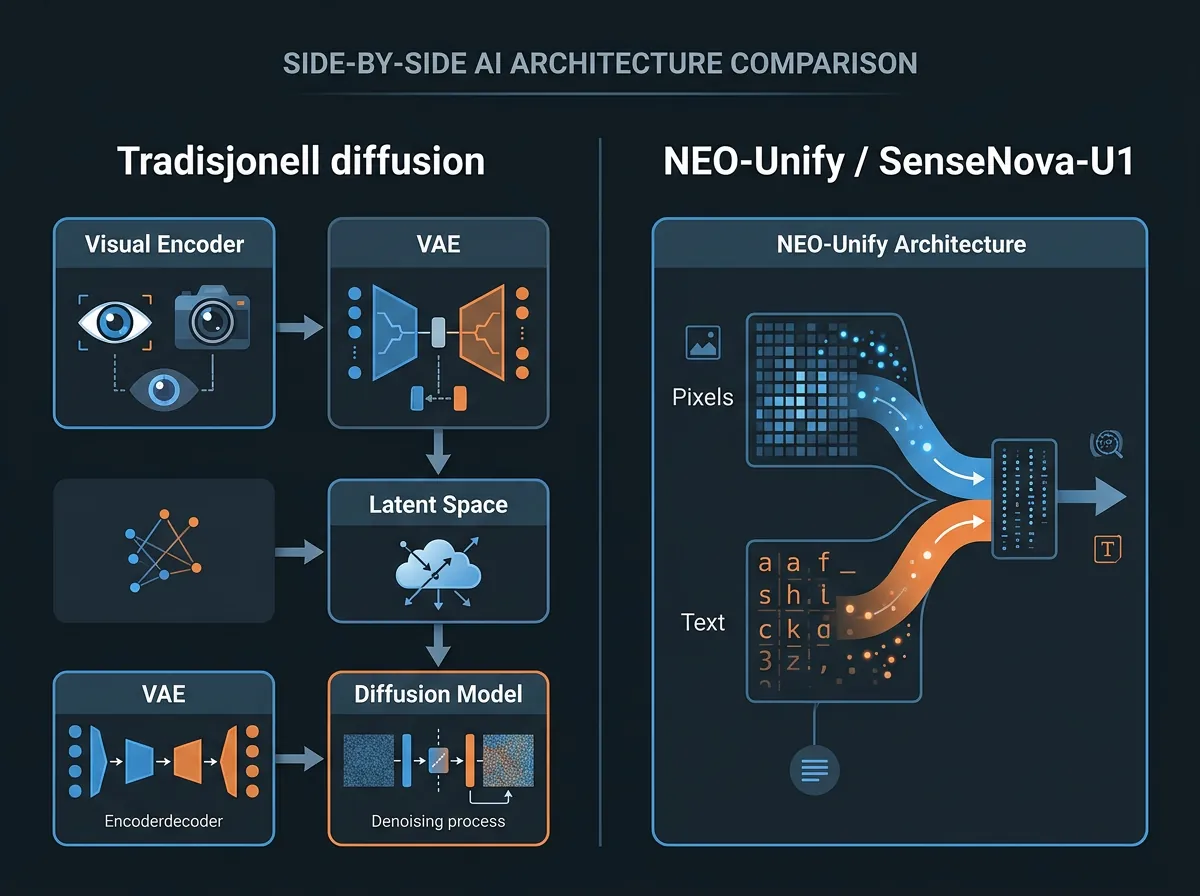
For å forstå hva SenseNova-U1 prøver å løse, er det verdt å ta et steg tilbake. Modeller som Flux og Stable Diffusion er bygget rundt en prosess som kalles diffusion: de starter med støy og progressivt «renser» bildet over mange steg. For å gjøre dette effektivt komprimerer de først bildet til et latent rom via en VAE (Variational Autoencoder). Modellen jobber på disse komprimerte representasjonene, ikke på faktiske piksler.
Det fungerer veldig godt for naturalistiske bilder. Men det er tre klassiske svakheter:
- Tekstrendering: Modellen forstår ikke tekst som tekst. Den ser det som visuelt mønster i latent rom, og resultatet er nesten alltid feilstavede rotete bokstaver.
- Tett informasjon: Infografikk, plakater med punktlister, tegneserier med snakkebobler – alt som krever presisjon og struktur sliter diffusion-modeller med.
- Forståelse og generering er adskilte: En diffusion-modell vet ikke hva den genererer – den bare genererer. Vil du redigere et bilde med instruksjoner krever du typisk et separat system.
SenseNova-U1 angriper alle tre på én gang ved å eliminere grensen mellom forståelse og generering.
Hva er NEO-Unify-arkitekturen?
NEO-Unify fjerner to komponenter som alle eksisterende bildegeneringsmodeller er avhengige av: den visuelle encoderen og VAE-en. I stedet behandles piksler og tokens som én sammenhengende strøm av informasjon – det selskapet kaller «a unified compound» av språk og visjon.
Kjernen er en såkalt Mixture-of-Transformer (MoT) backbone. Det er en type arkitektur der ulike deler av modellen spesialiserer seg på forskjellige typer informasjon, men de trenes og kjøres samlet. Resultatet er at modellen kan tenke visuelt og lingvistisk i samme prosess, ikke via en adapter mellom to separate modeller.
Noen konkrete tall fra benchmarkene: bilderekonstruksjon på MS COCO 2017 gir 31,56 PSNR og 0,85 SSIM, mot Flux VAEs 32,65 / 0,91. Det er marginalt svakere på ren pikselkvalitet, men modellen trenger ikke VAE for å komme dit – og den får med seg semantisk forståelse på kjøpet. På bilderedigering (ImgEdit-benchmark) scorer den 3,32, og støtter kontekstvindu på opp til 32 000 tokens.
Hva kan SenseNova-U1 gjøre i praksis?
Det er her det blir konkret. Fordi modellen faktisk forstår innholdet den genererer, åpner det for brukstilfeller som er vanskelig eller umulig med rene diffusion-pipelines:
Tekstrendering i bilder. Vil du lage en plakat med en lang tittel, et slide-deck med punktlister, eller en tegneserie med snakkebobler? SenseNova-U1 har en direkte tekstforståelsesvei, noe Flux og Stable Diffusion mangler. Teksten i bildet genereres med den samme forståelsen som resten av innholdet.
Infografikk og tett layout. Annoterte diagrammer, flersidede layouter, CV-er, presentasjoner, kunnskapsillustrasjooner – modellen er eksplisitt designet for det selskapet kaller «high-density information rendering». Det er en direkte konsekvens av at modellen prosesserer semantisk innhold, ikke bare latent støy.
Bilderedigering med resonnering. I stedet for et separat inpainting-system kan du gi instruksjoner som «fjern personen i bakgrunnen» eller «bytt ut logoen» og modellen bruker sin forståelse av innholdet til å redigere presist. Det er nærmere det du forventer fra et visuelt intelligent system enn fra en diffusion-modell.
Interleaved tekst og bilde. Modellen kan generere innhold der tekst og bilder veksles i én samlet flyt – tenk reiseguider, oppskrifter med steg-for-steg bilder, eller instruksjonsmanualer. Denne funksjonen er fortsatt i beta og RL-optimalisering er ikke fullført, men potensielt er det en stor fordel over systemer som holder modalitetene adskilt.
Hvilke modellvarianter finnes?
Det er to modeller tilgjengelig via HuggingFace:
- SenseNova-U1-8B-MoT: Den store varianten med 8 milliarder parametere, tett backbone. Mest kapabel, høyere VRAM-krav.
- SenseNova-U1-A3B-MoT: En mixture-of-experts-variant med ~3 milliarder aktiverte parametere. Raskere og mer tilgjengelig for folk med begrenset GPU-minne.
Begge finnes i SFT-versjon (supervised fine-tuned) og RL-trent versjon. Generasjonshastigheten på H100/H200 med optimalisert kjøring er oppgitt til rundt 9 sekunder for et 2048×2048 bilde med TP2+CFG2 parallellisme. Det er ikke lynraskt, men heller ikke tregt for den oppløsningen.
Lisensen er Apache 2.0, som er det beste du kan håpe på fra open source AI. Kommersiell bruk er tillatt, du kan kjøre den på egne servere, og du kan bygge produkter på toppen av den.

Er dette verdt å følge med på?
Jeg er alltid skeptisk til kinesiske modeller – ikke av prinsipp, men fordi det er vanskelig å vite hva som er reell kapabilitet og hva som er curated demo-output. SenseTime er ikke ukjent i bransjen, men de er heller ikke Anthropic eller Google når det gjelder transparens rundt treningsdata og prosess.
Det som er genuint interessant her er arkitekturvalget. Å fjerne VAE og visuell encoder er ikke bare et optimaliseringstriks – det er en fundamentalt annen måte å tenke på forholdet mellom forståelse og generering. Mercury 2 prøvde noe lignende med reasoning i diffusion-domenet. SenseNova-U1 tar et annet veivalg: eliminerer diffusion-prosessen helt til fordel for én samlet modell.
Begrensningene er reelle. Kontekst på 32 000 tokens er greit men ikke imponerende. Finstiltrekk på menneskekropper er eksplisitt nevnt som svakt. Og tekstrendering kan fremdeles produsere skrivefeil i tette layouts – forbedret er ikke det samme som løst. Interleaved generering er i beta.
Sammenlignet med OpenAIs tilnærming til bildemodeller er dette mer åpen og tilgjengelig – du kan faktisk kjøre det selv. Det er verdt å teste for deg som jobber med infografikk, slides eller andre brukstilfeller der diffusion-modeller historisk har mislyktes med tekst.
Kildekoden ligger på GitHub (OpenSenseNova/SenseNova-U1). Modellvektene er på HuggingFace. Installasjon krever Python og uv. Har du en GPU med nok VRAM til 3B-varianten er det en lav terskel å prøve det selv – og det er kanskje den beste måten å se om markedsføringen holder vann.







