

Innhold Vis
IBM Granite 4.1 er en ny familie av open source språkmodeller lansert 30. april 2026, tilgjengelig i tre størrelser: 3B, 8B og 30B parametere. Alle modellene er lisensiert under Apache 2.0, støtter et kontekstvindu på opptil 512 000 tokens, og er trent på rundt 15 billioner tokens gjennom et flerfase-treningsprogram. Det som gjør Granite 4.1 interessant er ikke størrelsen – det er at 8B-modellen matcher eller slår den tidligere 32B Mixture-of-Experts-modellen fra Granite 4.0.
IBM har jobbet med Granite-serien i flere år, og 4.1 er den første virkelig store oppdateringen til den dense, decoder-only arkitekturen. Der 4.0 satset på hybrid MoE-arkitektur for å presse ytelse ut av færre aktive parametere, er 4.1 en annen tilnærming: tren en enklere, tettere modell bedre. Resultatet er at en 8B-modell fra 2026 gjør det den trengte 32B parametere aktivt for å klare for bare noen måneder siden.
Jeg synes dette er et fascinerende skifte. Effektivitetsforbedringer i AI-trening betyr at modeller fra i fjor allerede er teknisk utdaterte – ikke fordi de er dårlige, men fordi samme ytelse nå kommer i en pakke som er fire ganger lettere å kjøre lokalt.
Hva er IBM Granite 4.1, og hva skiller det fra 4.0?
Granite 4.1 er en familie av rene dense transformer-modeller med tre størrelser: 3B, 8B og 30B parametere. Begge instruct- og base-varianter er tilgjengelig for alle tre størrelsene, og IBM tilbyr i tillegg FP8-kvantiserte versjoner som halverer minnefotavtrykket uten vesentlig ytelsestap.
Sammenlignet med Granite 4.0-serien er dette et arkitekturvalgsskifte. IBM gikk til Mixture-of-Experts (MoE) i 4.0 for å få mer kapasitet per aktiv parameter – en strategi som fungerer bra på server-skala, men som kompliserer lokal deployment. Granite 4.1 er tvert imot: enkel, forutsigbar arkitektur, men trent mye bedre. Alle tre modellstørrelsene bruker Grouped Query Attention med 8 KV-hoder, RoPE-posisjonkoding, SwiGLU-aktivering og RMSNorm – standardkomponenter du kjenner igjen fra Llama-familien og lignende modeller.
Det viktigste tallet er dette: Granite 4.1 8B instruct matches or exceeds Granite 4.0 32B MoE ifølge IBMs egne benchmarks. Det betyr at du kan kjøre den på et vanlig gaming-oppsett med 16GB VRAM og få ytelse tilsvarende en modell som krevde serverhardware.
Hva er de tekniske spesifikasjonene for 3B, 8B og 30B?
Arkitekturdetaljene er godt dokumentert av IBM. Her er det som skiller de tre størrelsene fra hverandre på komponentnivå:
- Granite 4.1 3B: 2560 embedding-dimensjoner, 40 lag, 40 attention-hoder. Designet for edge-deployment og ressursbegrensede miljøer.
- Granite 4.1 8B: 4096 embedding-dimensjoner, 40 lag, 32 attention-hoder. Balansepunktet mellom ytelse og ressurskrav – dette er modellen de fleste kommer til å bruke.
- Granite 4.1 30B: 4096 embedding-dimensjoner, 64 lag, 32 attention-hoder. For de som vil ha maksimal ytelse og har hardware til det.
Alle tre støtter kontekstvindu opptil 512 000 tokens, noe som er enormt. For referanse: 512K tokens tilsvarer omtrent 384 000 ord, eller rundt 4-5 gjennomsnittlige romaner. I praksis betyr det at du kan gi modellen et helt codebase, en lang juridisk kontrakt, eller tusenvis av sider dokumentasjon på én gang. RULER-benchmarken for long context viser at 8B-modellen scorer 83,6 på 32K tokens og 73,0 på 128K – akseptable tall, selv om ytelsen faller noe ved ekstremt lange kontekster som forventet.
IBM har også lagt til FP8-kvantisering som standard. Det betyr omtrent 50 prosent reduksjon i diskplass og GPU-minne sammenlignet med FP16/BF16. For 8B-modellen betyr det at du kan kjøre instruct-varianten på kortere enn 8GB VRAM i FP8-format – noe som åpner for deployment på forbruker-GPU-er som RTX 3060 eller 4070.

Hvordan er Granite 4.1 trent?
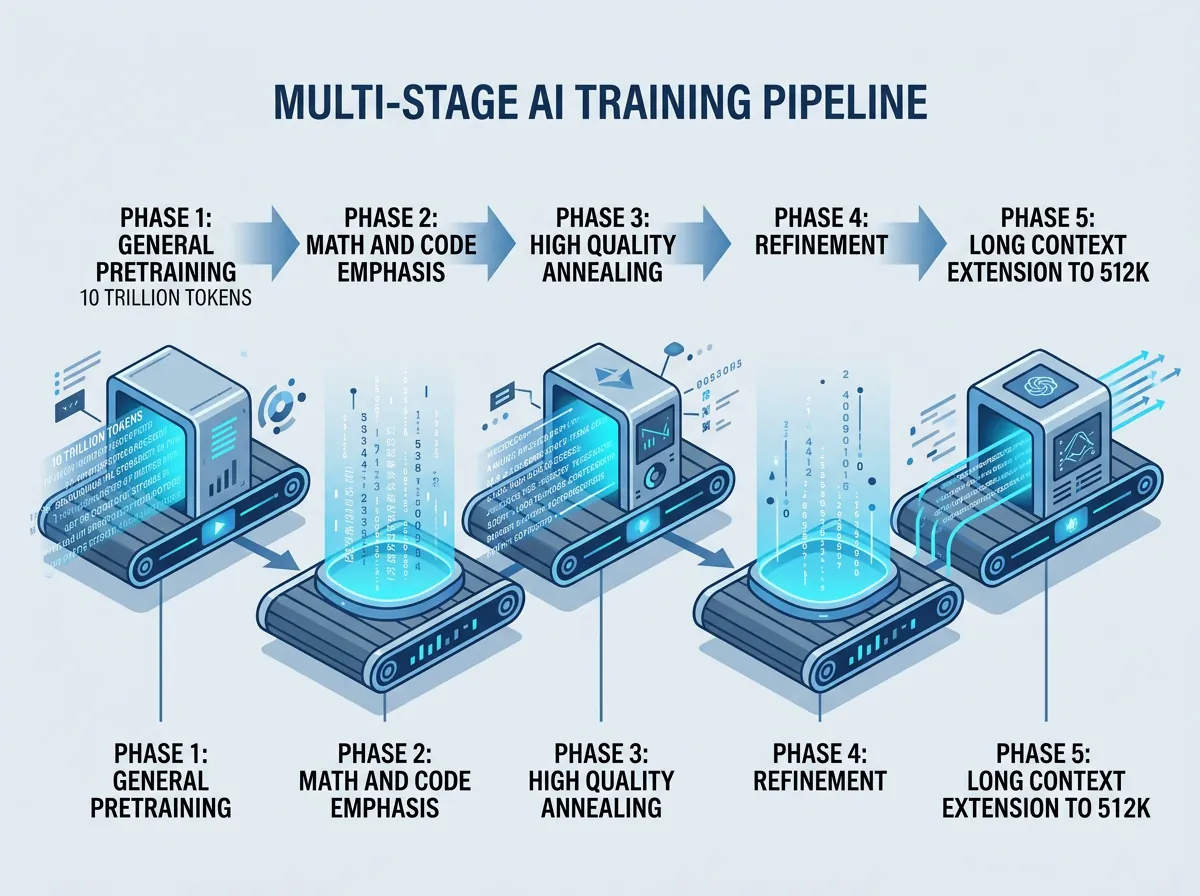
Treningspipelinen er grundig dokumentert i IBMs HuggingFace-bloggpost, og den er verdt å lese hvis du er interessert i dette. Totalt ble modellene trent på rundt 15 billioner tokens fordelt over fem faser:
- Fase 1 (10 billioner tokens): Generell pre-trening med CommonCrawl (59%), kode (20%) og matematikk (7%)
- Fase 2 (2 billioner tokens): Økt vekt på matematikk (35%) og kode (30%)
- Fase 3 (2 billioner tokens): Høykvalitets annealing med chain-of-thought data
- Fase 4 (0,5 billioner tokens): Finpussing med høykvalitets CommonCrawl og balansert kode/matematikk
- Fase 5: Long context extension – kontekstvinduet ble utvidet fra 32K til 128K og deretter til 512K tokens
Etter pre-training fulgte supervised fine-tuning på 4,1 millioner høykvalitets kuraterte eksempler, med et LLM-as-Judge-rammeverk som evaluerte instruksjonsfølging, nøyaktighet, fullstendighet og naturalighet. Deretter kom reinforcement learning i fire trinn, inkludert RLHF som ga en forbedring på 18,9 poeng på Alpaca-Eval. Det siste trinnet var identitets- og matematikk-RL som hentet tilbake litt av ytelsen som forsvant under RLHF – en kjent avveiing mellom allsidighet og faglig presisjon.
Hva er benchmark-tallene faktisk verdt?
Benchmarks er krydder, ikke sannhet. Det vet du om du har fulgt med på AI-utviklingen de siste par årene. Men tallene IBM presenterer for 8B-modellen er interessante uansett:
- MMLU: 73,84 (generell kunnskap)
- GSM8K: 92,49 (matematikk-resonnering)
- HumanEval: 87,20% (kodegenerering)
- IFEval: 87,06 (instruksjonsfølging)
- BFCL v3: 68,27 (tool calling)
HumanEval på 87,2% for en 8B-modell er bra. Det er på nivå med det GPT-4-klassen scoret for halvannet år siden på samme benchmark. Tool calling på 68,27 på BFCL v3 er litt lavere enn toppmodellene, men langt over hva du kan forvente av en modell i denne størrelsen.
Artificial Analysis, som evaluerer modeller uavhengig, gir Granite 4.1 8B en Intelligence Index-score på 12 og 30B-modellen en score på 15 – begge over gjennomsnittet for open weight non-reasoning modeller i sine respektive størrelsesklasser. Ta det for hva det er – en indikasjon, ikke en fasit.
Hva kan du faktisk bruke Granite 4.1 til?
IBM posisjonerer Granite 4.1 mot fire bruksområder: flerspråklig tekst, koding, RAG-baserte systemer og AI-agenter med tool calling. Apache 2.0-lisensen betyr at du kan bygge kommersielle produkter på toppen uten royalties eller lisensrestriksjoner – noe som er avgjørende for bedrifter som vil eie sin egen AI-infrastruktur.
For lokalt bruk er 8B-modellen det naturlige valget for de fleste. Den støtter 12 språk inkludert engelsk, tysk, spansk, fransk, japansk og arabisk – norsk er ikke på listen, men engelsk-instruksjoner på norske data fungerer fint i praksis. FP8-varianten kjører på 8GB VRAM, noe som betyr at den passer på en RTX 3080, 4070 eller tilsvarende.
Hvis du allerede bruker Ollama for lokal AI, vil Granite 4.1 sannsynligvis dukke opp i modellregistret ganske raskt. IBM har historisk støttet Ollama-deployment, og den enkle arkitekturen i 4.1 gjør integrasjon enklere enn MoE-variantene fra 4.0-serien.
For utviklere er tool calling-støtten verdt å merke seg. Granite 4.1 bruker en standardisert chat-template med native verktøystøtte via transformers-biblioteket – du kan se et fungerende eksempel i IBMs bloggpost. Det er ikke like polert som OpenAI-APIet, men det fungerer godt for agentbaserte systemer der du vil kontrollere hele stacken selv.
Hva er IBM Granite 4.1-serien utover språkmodellene?
IBM lanserte ikke bare 3B/8B/30B-modellene. Granite 4.1 er egentlig en samleterm for en hel familie av spesialiserte modeller:
- Granite Speech 4.1 2B: Tale-til-tekst-modell med 5,33% word error rate – topp på OpenASR Leaderboard
- Granite Vision 4.1: Vision-language-modell spesialisert for dokumentforståelse, tabeller og kartlesing
- Granite Embedding: Embeddings-modell som støtter over 200 språk, og som IBM hevder vil score øverst på MTEB leaderboard
- Granite Guardian 4.1: Sikkerhets- og risikoevaluering, utvidet med flere risikokategorier
Hele familien er Apache 2.0, og alt er tilgjengelig på IBMs HuggingFace-profil. Samlet sett er dette IBMs mest komplette AI-plattformlansering til dato – de konkurrerer ikke bare på LLM-ytelse, men på hele enterprise AI-stacken.
Er Granite 4.1 verdt å se nærmere på?
Ja, men med nyanser. For åpen, lokal bruk med Apache 2.0-lisens er Granite 4.1 8B et av de mest interessante alternativene som finnes akkurat nå i sin størrelse. En 8B-modell som matcher en 32B MoE-modell fra bare noen måneder siden er et konkret bevis på at trendlinjen for open source AI fortsatt peker bratt oppover.
IBM er ikke et selskap som de fleste AI-entusiaster assosierer med cutting-edge forskning, men Granite-serien har jevnt over levert modeller som overpresterer i sin størrelsesklasse. Granite 4.1 er ikke et unntak. Hvis du trenger en modell du kan kjøre lokalt, bruke kommersielt og integrere i et open source AI-oppsett uten å bekymre deg for lisenser – er dette et solid valg.
Modellene er tilgjengelig på HuggingFace nå. IBMs eget playground er tilgjengelig på ibm.com/granite/playground om du vil teste uten å laste ned noe. Hele IBM Research-bloggposten er også verdt å lese for de som vil grave dypere i treningsdetaljer og arkitekturvalgene bak modellene.
Det jeg lurer på nå er egentlig om vi nærmer oss et metningspunkt for hva dense arkitektur kan presse ut av 8B parametere, eller om det fortsatt er rom for vesentlige forbedringer. Granite 4.1 8B på 87% HumanEval og 92% GSM8K er imponerende – men det er ikke dramatisk bedre enn det de beste 8B-modellene fra Mistral og Meta leverer. Kanskje neste store sprang kommer fra treningsdataene snarere enn arkitekturen? Det får vi se.








1 kommentar