

Innhold Vis
ExLlamaV3 er inferens-biblioteket som lar deg kjøre store språkmodeller på vanlig forbrukerhardware. Utvikleren turboderp har hatt en imponerende produktiv periode, og oppdateringene som har kommet de siste ukene gjør ExLlamaV3 til en av de raskeste lokale inferens-løsningene som finnes akkurat nå.
Tre store oppdateringer har rullet ut i rask rekkefølge: Gemma 4-støtte, forbedret caching-effektivitet og til slutt DFlash – spekulativ dekoding som i noen scenarioer mer enn dobler hastigheten. Tallene som ligger ute er ganske interessante å se på, særlig for deg som kjører modeller lokalt og alltid er ute etter å klemme ut litt ekstra ytelse.
Her er hva som har skjedd, hva tallene faktisk betyr, og hva du kan forvente å oppleve i praksis.
Hva er ExLlamaV3?
ExLlamaV3 er et inferens-bibliotek spesifikt designet for å kjøre store språkmodeller på moderne forbruker-GPU-er, altså kortene de fleste av oss faktisk har hjemme. Det er ikke det eneste verktøyet i denne kategorien – llama.cpp har nylig lagt til MTP-støtte med 2,4 ganger hastighetsforbedring, og det finnes alternativer som vLLM og andre – men ExLlamaV3 skiller seg ut med sitt eget kvantiseringsformat.
Formatet heter EXL3, og det er basert på QTIP-teknologi. Det du trenger å vite er at EXL3 lar deg kjøre modeller på langt lavere bit-bredder enn vanlig. Llama-3.1-70B – en 70 milliarder parameter-modell – er fullt brukbar ned til 1,6 bpw (bits per weight). Med output-laget kvantisert til 3 bpw og en 4096-token cache er det mulig å kjøre modellen på under 16 GB VRAM. Det er et tall verdt å la synke inn: en 70B-modell på ett enkelt forbrukerkort.
ExLlamaV3 støtter tensor-parallell og ekspert-parallell inferens, kontinuerlig dynamisk batching, spekulativ dekoding og over 50 ulike modell-arkitekturer inkludert Llama, Qwen, Mistral og Gemma-varianter. Anbefalt backend for server-bruk er TabbyAPI, som gir en OpenAI-kompatibel API.
Hva er DFlash – og hvordan fungerer spekulativ dekoding?
Den største oppdateringen er DFlash, som er implementasjonen av spekulativ dekoding i ExLlamaV3. For å forstå hvorfor dette er interessant, er det verdt å bruke et minutt på å forklare hva spekulativ dekoding faktisk gjør.
Vanlig tokengenerering i en stor modell er sekvensiell – én token om gangen, en prosess som ikke er spesielt effektiv å parallellisere. Spekulativ dekoding snur dette på hodet: en liten, rask «draft»-modell genererer et knippe token-forslag på forhånd, og den store modellen verifiserer dem alle på én gang. Hvis forslagene er riktige (noe de er overraskende ofte i forutsigbare sekvenser), får du effektivt mange tokens per steg i stedet for én.
DFlash er ExLlamaV3s variant av dette, og implementeringen inkluderer n-gram/suffix-caching som et ekstra trinn. N-gram-hurtigbufferen plukker opp repetitive mønstre fra konteksten og bruker dem som draft-forslag uten å trenge en separat modell i det hele tatt. Resultatet er at du kan få spekulativ-dekoding-ytelse uten overhead fra å kjøre to modeller simultant.

Hva sier hastighetstallene?
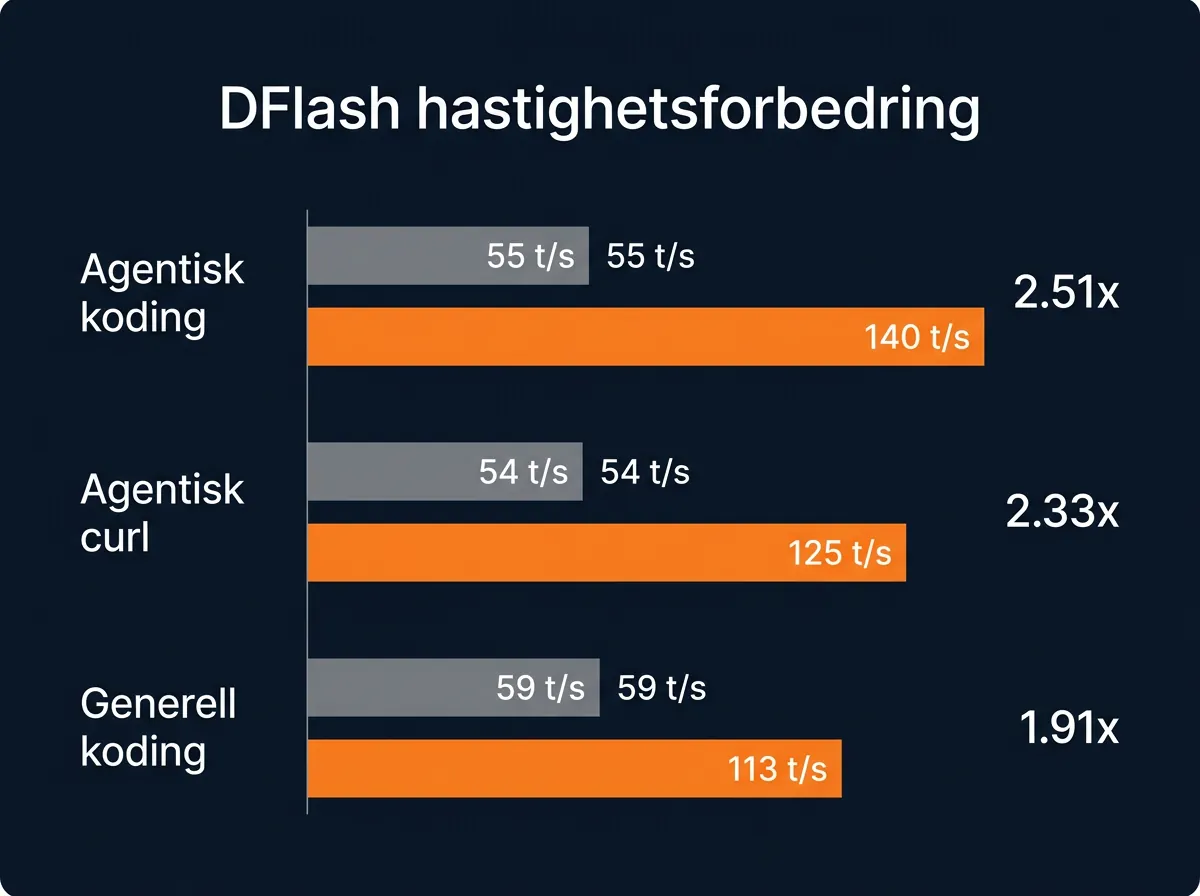
La meg ta tallene fra DFlash-oppdateringen, som ble delt offentlig av turboderp. Tre kategorier ble testet: agentisk koding, agentisk curl-bruk og generell koding. Baseline er standard ExLlamaV3 uten noen draft-mekanisme.
For agentisk kode-generering: baseline på 55,98 tokens per sekund. Med n-gram/suffix-cache: 89,58 t/s – det er en 1,60x forbedring. Med DFlash: 140,61 t/s, altså 2,51 ganger raskere enn utgangspunktet.
Agentisk curl-bruk: baseline 54,03 t/s, n-gram 74,62 t/s (1,38x), DFlash 125,94 t/s (2,33x forbedring). Generell koding: baseline 59,21 t/s, n-gram 75,34 t/s (1,27x), DFlash 113,12 t/s (1,91x).
Mønsteret er tydelig: jo mer forutsigbar og repetitiv outputen er, jo mer gevinst. Agentisk kode har mange gjentakende mønstre (funksjonskall, syntaks, boilerplate) og drar størst nytte av draft-mekanismene. Generell koding er allerede mer variert og gir «bare» 91% hastighetsøkning – noe som i praksis fremdeles er veldig bra.
Det er viktig å merke seg at disse tallene er fra optimale kjøringer. I praksis vil du se variasjon avhengig av modell, kontekstlengde og hvilken type tekst du genererer. Men retningen er klar: ExLlamaV3 med DFlash er betydelig raskere enn uten, særlig for kodingsoppgaver.
Hva betyr dette i praksis?
Hvis du kjører lokale modeller for koding eller agentiske workflows, er dette en direkte oppgradering. 140 tokens per sekund for kode-generering er fort nok til at du faktisk ikke venter – det bare strømmer. Det er en merkbar kvalitetsforskjell i bruksopplevelsen kontra 55 t/s baseline.
Gemma 4-støtten som kom tidligere er også verdt å nevne – spekulativ dekoding for Gemma 4-31B er nå tilgjengelig via DFlash, og det er en god modell å teste kombinasjonen på. Jeg har tidligere skrevet om Googles beslutning om å fjerne MTP fra offentlige Gemma 4-modeller, noe som gjør tredjeparts-inferens-verktøy som ExLlamaV3 enda mer relevante for å hente ut maksimal ytelse.
For de som er nysgjerrige på alternativene: FastDMS har tatt en annen tilnærming med KV-cache-komprimering og har imponerende resultater mot vLLM. Og open source AI-verktøy-landskapet generelt er i en veldig aktiv periode akkurat nå – det er nesten vanskelig å henge med.
Hvem er ExLlamaV3 for?
Ikke for nybegynnere – det er greit å si det rett ut. Dette er et verktøy for folk som allerede vet hva de driver med: som forstår hva bpw betyr, som har konvertert modeller til EXL3-format, og som er komfortable med kommandolinje og Python-miljøer. Installasjon via prebuilt wheels er relativt greit, men du er på egne bein hvis noe ikke fungerer.
For deg som er på det nivået, er ExLlamaV3 en av de mest kapable inferens-løsningene for forbrukerhardware. EXL3-formatet er genuint imponerende for minne-effektivitet – en 70B-modell på 16 GB VRAM er ikke en lite imponerende bragd. Og DFlash-tallene snakker for seg selv.
Turboderp holder et høyt tempo akkurat nå. Det er verdt å holde øye med hva som kommer videre.







