

Innhold Vis
Ollama er ikke lenger det eneste – eller beste – alternativet for å kjøre lokale AI-modeller. Et blogginnlegg på Hacker News denne uken traff en nerve blant lokal-AI-entusiaster: artikkelen «The local LLM ecosystem doesn’t need Ollama» samlet 547 stemmer og 169 kommentarer. Det er mye for et teknisk rant om et verktøy folk flest aldri har hørt om.
Poenget i artikkelen er enkelt: Ollama er blitt mer et mellomledd enn en hjelper. Det finnes bedre alternativer, og de tekniske argumentene for å droppe Ollama er sterkere enn mange tror.
Jeg har fulgt Ollama siden det kom, og jeg skjønner godt hvorfor det ble populært. Men la meg ta deg gjennom hva kritikerne faktisk sier – og om det holder vann.
Hva er Ollama, og hvorfor ble det så populært?
Ollama er et verktøy som lar deg laste ned og kjøre lokale AI-modeller med én kommando. ollama run llama3 og du er i gang. Det var revolusjonerende da det kom – ingen konfigurering, ingen CUDA-pining, bare en modell som kjørte på din egen maskin.
For mange var Ollama inngangsporten til lokal AI. Det er lett å forstå. Men bak den enkle fasaden skjuler det seg noen problematiske valg – og én stor teknisk avhengighet som ikke alltid er synlig for brukeren.
Hviler Ollama på skuldrene til llama.cpp?
Det er her det begynner å bli interessant. Ollama er egentlig bare et tynt lag oppå llama.cpp – et C++-bibliotek laget av Georgi Gerganov. llama.cpp er selve motoren som gjør at modellene faktisk kjører. Ollama er dashbordet.
Problemet ifølge kritikerne: Ollama lot i over ett år være å kreditere llama.cpp som avhengighet, til tross for at MIT-lisensen eksplisitt krever opphavsrettsnotis. Det er ikke et lite poeng for et open source-prosjekt. Da Ollama i 2025 forsøkte å lage sin egen backend uavhengig av llama.cpp, introduserte de feil som llama.cpp hadde løst år tidligere.
Og tallene er ganske tydelige: llama.cpp kjører 1,8 ganger raskere enn Ollama med identisk maskinvare i benchmarks. Du betaler en ytelsespris for bekvemmeligheten.
Hva er de konkrete problemene med Ollama?
Foruten attribusjonsproblemet er det noen arkitektoniske valg som irriterer mer erfarne brukere:
Modelfile-systemet er egentlig et steg tilbake. GGUF-formatet (standarden for kvantiserte modeller) inneholder allerede all nødvendig metadata – temperatur, kontekstlengde, chat-template. Ollama legger til sitt eget proprietary lag på toppen. Det betyr at du lærer Ollamas syntax i stedet for å lære GGUF direkte.
Hashed filnavn og registry-lock-in. Ollama bruker sin egen registry med hashed filnavn. Det gjør det vanskeligere å flytte modeller ut av Ollama-systemet igjen. Du laster ned en modell «gjennom Ollama», men du eier den ikke på en måte som er lett å bruke andre steder.
Navneforvirring med modeller. Ollama presenterte DeepSeek-R1 distill-modeller uten «Distill»-prefikset. Det høres trivielt ut, men det forvirret mange brukere som trodde de kjørte fullversjon av DeepSeek-R1. Distillerte modeller er raskere og lettere, men de er ikke det samme som originalmodellen.
Sikkerhetshull. CVE-2025-51471 er en tokenlekkasjevulnerabilitet i Ollamas registry-pulleringer. Det er ikke katastrofalt, men det viser at det tynnere laget også er et potensielt angrepsflate.
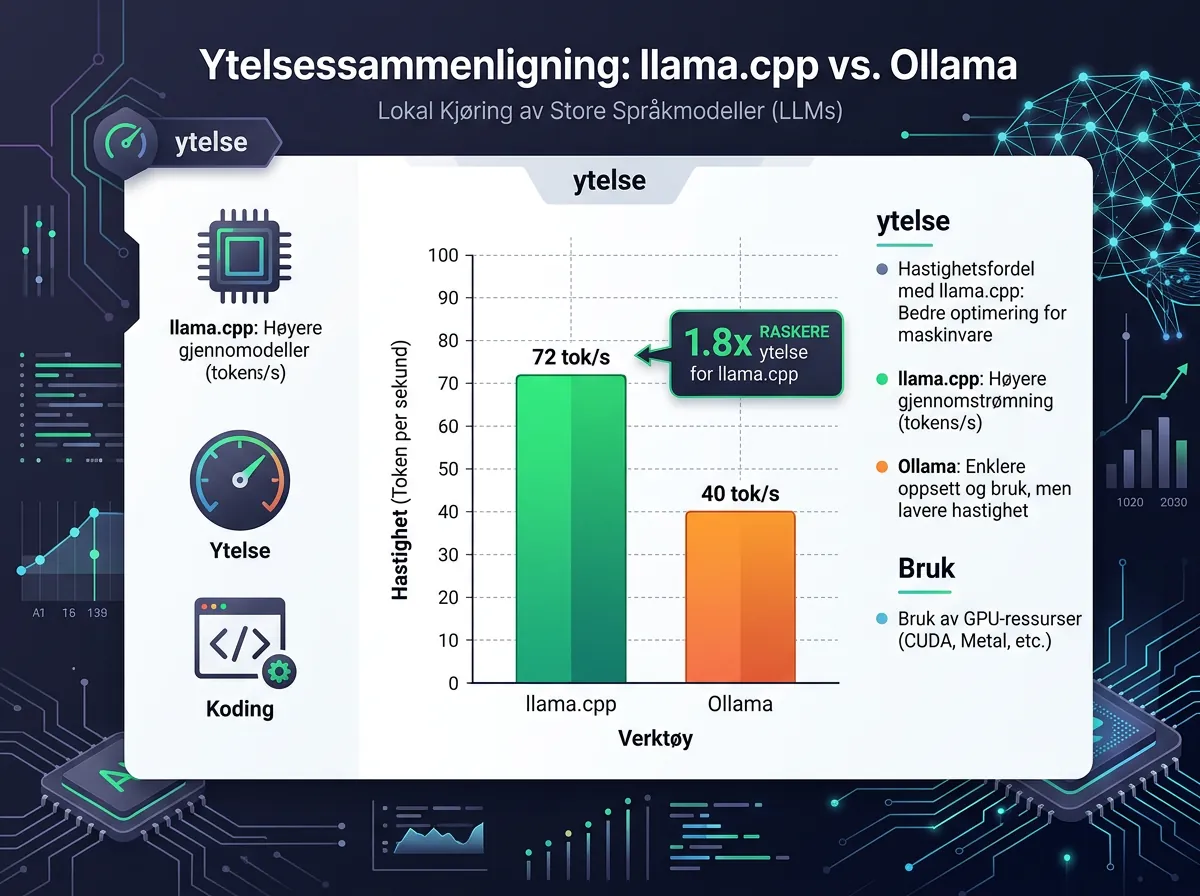
Hvilke alternativer finnes for lokal LLM-kjøring?
Her er det gode nyheter: du har faktisk mange valg, avhengig av hva du trenger.
llama.cpp direkte er det raske valget for deg som vil ha ytelse uten mellomledd. Det er kommandolinje-basert, men llama.cpp ble kjøpt av Hugging Face i februar 2026 og vedlikeholdes aktivt. Ikke lenger et sideprosjekt – dette er infrastruktur.
LM Studio er et GUI-alternativ som bruker llama.cpp som backend. Har et pent brukergrensesnitt, støtter modellnedlasting direkte fra Hugging Face, og er et naturlig neste steg for deg som liker Ollamas enkelhet men vil ha mer kontroll.
Jan (jan.ai) og Msty er to open source desktop-applikasjoner som har vokst seg populære som Ollama-alternativer. Begge er mer transparente om hva de faktisk gjør under panseret.
ramalama fra Red Hat er interessant for de som kjører containere. Det krediterer eksplisitt upstream-avhengigheter – stikk i strid med det Ollama ble kritisert for – og er designet for produksjonsmiljøer.
llama-swap og LiteLLM er for deg som trenger å orkestrere flere modeller. llama-swap håndterer switching mellom modeller, mens LiteLLM er en enhetlig API-proxy som gjør at du kan bytte mellom lokale og skybaserte modeller med én og samme kodebase.
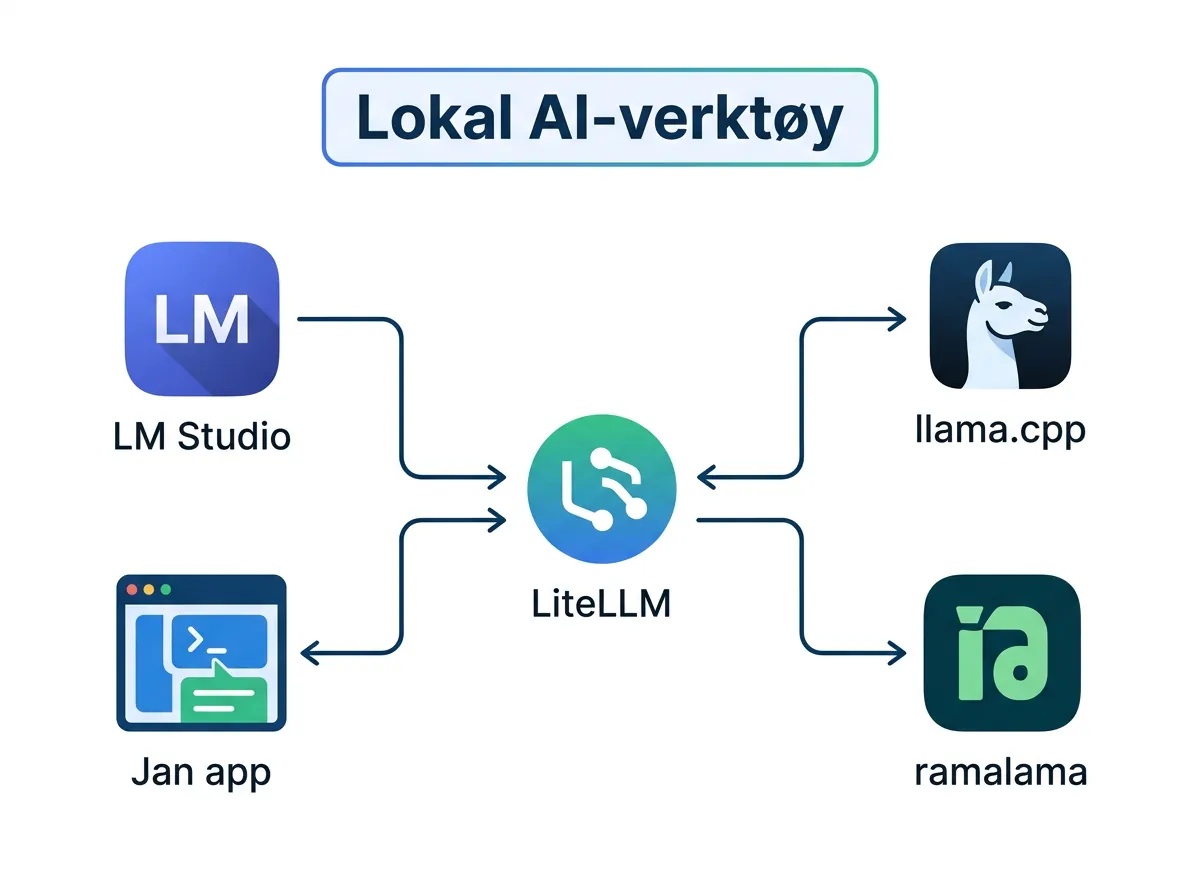
Betyr dette at du bør avinstallere Ollama i dag?
Ikke nødvendigvis. Kritikken i artikkelen er legitim, men den retter seg primært mot erfarne brukere og utviklere som allerede vet hva de driver med. Hvis Ollama fungerer for deg akkurat nå, er det ingen krise.
Men det er verdt å vite at Ollama ikke er «lokal AI». Det er et spesifikt verktøy med spesifikke avveininger. Og alternativene er modnet til et punkt der de er like enkle å bruke – i noen tilfeller enklere.
Det jeg tar med meg fra denne debatten er egentlig noe større: lokal-AI-økosystemet er veldig mye mer robust enn det var for to år siden. llama.cpp under Hugging Face, LM Studio som et fullgodt GUI, Jan og Msty som desktop-alternativer – det finnes ekte konkurranse nå. Det er bra for alle som ønsker å kjøre modeller lokalt.
Har du allerede byttet fra Ollama til noe annet? Eller er du fornøyd med det du har? Jeg er genuint nysgjerrig på hva folk faktisk bruker der ute.
Relatert: Jeg har tidligere sett på Ollama som skrivebordsagent og Intel Arc Pro B70 til lokal LLM – begge er fortsatt relevante referanser for lokal AI-oppsett.







