

Innhold Vis
TwELL er et nytt CUDA-optimert dataformat fra Sakana AI og NVIDIA som gir opptil 20,5% raskere AI-inferens og 21,9% raskere trening av store språkmodeller. Resultatet er ikke fra ny hardware eller en helt ny modellarkitektur – det er fra å utnytte noe som allerede er der: at LLM-ene i stor grad regner med nuller.
Forskerteamet publiserte resultatene 11. mai 2026, og tallene er konkrete: en 2-milliarder parameter modell kjørt på 8× H100 PCIe GPU-er leverer 20,5% bedre inferenshastighet og 21,9% kortere treningstid. Energiforbruket per token faller med 17%. Det er ikke marginale gevinster – det er den typen tall som gjør at folk faktisk endrer produksjonsoppsett.
Teknikken bygger på L1-regularisering og sparsity – konsepter som ikke er nye, men som Sakana AI og NVIDIA nå har omsatt til ekte GPU-gjennomstrøming med egne CUDA-kjerner. Det interessante er ikke bare tallene, men at det er overraskende enkelt å få til.
Hva er TwELL, og hvorfor gir det raskere inferens?
TwELL står for Tile-wise ELLPACK, og er et sparse dataformat – altså en måte å pakke matrisedata på for GPU-en. Problemet som løses er gammelt: store deler av beregningene i en LLM er multiplikasjoner med nuller. En LLM med 99,5% sparsity i feedforward-lagene betyr at bare 0,5% av aktiveringene faktisk bærer informasjon i et gitt lag. De resterende 99,5% er null. Standard beregningsformater regner likevel gjennom dem alle, fordi de ikke er designet for å hoppe over nuller effektivt.
ELLPACK er et kjent format for sparse matriser, men det er ikke direkte tilpasset hvordan GPU-er faktisk utfører matrisemultiplikasjon. TwELL løser dette ved å partisjonere kolonner i horisontale «fliser» (tiles) som matcher den interne flisestørrelsen til matmul-kjernene. Konstruksjonen av formatet skjer dessuten direkte i epilogen av gate-projeksjonsberegningen – uten en ekstra kernel-lansering og uten synkroniseringskostnader. Det vil si at overhead-en er nesten null.
Resultatet er at GPU-en faktisk hopper over null-verdiene i stedet for å late som om den gjør det. Pearson-korrelasjonen mellom gjennomsnittlige ikke-null aktiveringer per lag og speedup-bidraget er -0,996 – nesten perfekt. Jo sparsere et lag er, jo mer gevinst gir det.
Hva er L1-regularisering, og hvordan skaper det 99,5% sparsity?
Tradisjonelle Transformer-modeller bruker SiLU som aktiviseringsfunksjon i feedforward-lagene. SiLU produserer sjelden eksakt null – den gir negative tall som er nære null, men ikke null. Det gjør det vanskelig å utnytte sparsity på GPU-en.
Trikset fra Sakana AI og NVIDIA er todelt. Først: bytt SiLU med ReLU. ReLU returnerer eksakt null for alle negative inngangsverdier. Deretter: legg til L1-regularisering under trening med en koeffisient på bare 2×10⁻⁵ – altså et svært lite straffeled som presser vektene mot null. Det er ikke mye, men det er nok.
Effekten er dramatisk. I en 1,5 milliarder parameter modell faller gjennomsnittlig antall aktive nevroner per lag fra 911 til 29. Det er en sparsity på 99,5%. Større modeller (2B) ender på 24 gjennomsnittlig aktive nevroner per lag mot 39 for 0,5B-modellen – større modeller blir altså relativt sett sparsere, noe som forklarer hvorfor speedup-tallene øker med modellstørrelse.
Det er én ting å merke seg: med L1-koeffisient på 2×10⁻⁵ dør over 30% av nevronene permanent. «Døde nevroner» i ReLU-nettverk er et kjent fenomen der aktiviseringer aldri igjen blir positive og dermed ikke bidrar til læring. Forskerteamet rapporterer likevel ingen målbar nøyaktighetsreduksjon over alle modellstørrelser som ble testet – noe som tyder på at modellene har god redundans.
Hvilke speedup-tall kan man faktisk forvente?
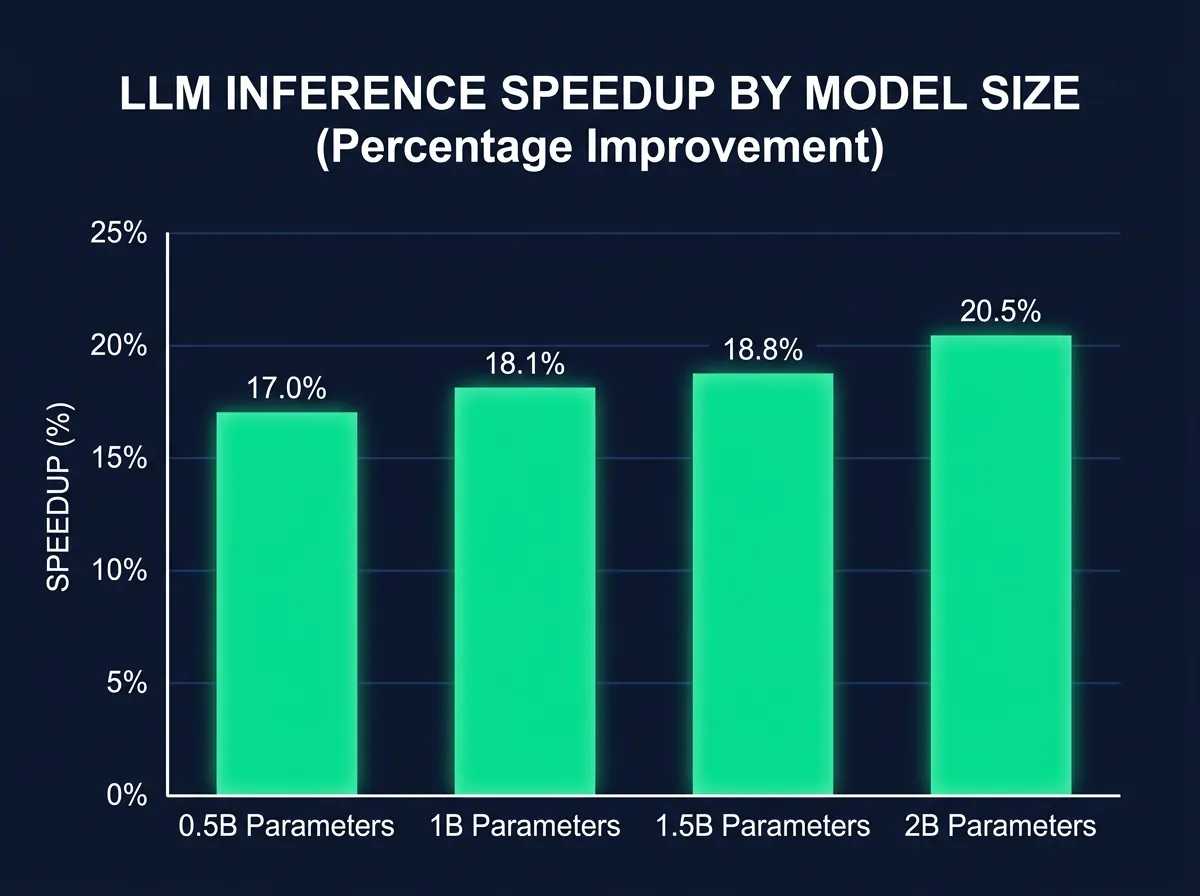
Her er de eksakte tallene fra testen kjørt på 8× H100 PCIe GPU-er med 2048 tokens sekvensslengde og 1 million tokens batchstørrelse:
- 0,5B-modell: +17,0% inferens, -1,5% trening, -11,8% energi per token, -19,2% minnebruk
- 1B-modell: +18,1% inferens, +7,1% trening, -14,6% energi per token, -25,5% minnebruk
- 1,5B-modell: +18,8% inferens, +11,6% trening, -15,0% energi per token, -28,1% minnebruk
- 2B-modell: +20,5% inferens, +21,9% trening, -17,0% energi per token, +22,3% minnebruk*
*2B-modellen bruker en større mikro-batch under trening, noe som gjør at aktiveringsminnet faktisk øker noe – men treningen er likevel raskere fordi gjennomstrømmingen per steg øker mer enn minnekostnaden.
Et interessant funn: NVIDIA RTX PRO 6000 (som har 188 shader-multiprocessorer mot H100 PCIe sine 114) viser enda større relative speedup. Det betyr at teknikken skalerer bedre på GPU-er med høy parallelisme, og ikke er spesifikt avhengig av H100-arkitekturen.
Til sammenligning er dette i samme størrelsesorden som hva FlashQLA fra Qwen leverte for attention-kjerner – men TwELL angriper feedforward-lagene i stedet, som utgjør en stor del av beregningene i en LLM.
Er sparsity jevnt fordelt gjennom modellen?
Nei – og det er et viktig poeng. Sparsity er ikke uniform gjennom lagene. De første to lagene i en 28-lags 1,5B-modell er minst aktive. Aktiviteten topper seg i tidlige-midtre lag og faller igjen mot slutten. Dessuten er det stor variasjon innenfor hvert lag: de første tokenene i en sekvens aktiverer langt flere nevroner enn de siste, med en tilnærmet eksponentiell nedgang.
Det betyr at en effektiv implementasjon ikke kan anta uniform sparsity. TwELL håndterer dette ved å beregne tile-dimensjoner dynamisk per lag i stedet for å bruke en global fast verdi. Det er mer kompleksitet i implementasjonen, men nødvendig for å høste gevinstene på tvers av alle lag.
Hva betyr dette i praksis for folk som kjører LLM-inferens?
Teknikken krever at modellen trenes fra bunnen med ReLU og L1-regularisering – det er ikke noe man putter på en eksisterende Llama 3 eller Qwen 2.5-vekt. Det begrenser umiddelbar anvendelighet noe.
For de som faktisk trener egne modeller – og det er et voksende antall aktører, fra forskningslaboratorier til selskaper som vil ha domenespesifikke modeller – er dette konkret interessant. En 20% forbedring i inferenshastighet uten tap av modellkvalitet er ikke noe man avviser. Det er en reell kostnadsbesparing.
Dette er også en del av en bredere trend der optimalisering flyttes ned i stack-en, nærmere GPU-en og CUDA-kjernene, i stedet for å søke gevinster på arkitekturnivå. ATLAS inference engine viste lignende filosofi – Rust og tilpassede CUDA-kjerner som slo vLLM med 131 tokens per sekund. Det ser ut til at mye av den neste bølgen med ytelsesgevinster i AI kommer nettopp fra dette nivået.
Kodebasen og CUDA-kjernene er publisert på Sakana AIs GitHub. Det er dermed mulig å utforske implementasjonen direkte.
Det interessante spørsmålet fremover er om denne typen teknikker kan brukes i kombinasjon – sparsity i feedforward-lag kombinert med kvantisering og effektive attention-kjerner. Hvis gevinstene er uavhengige og additive, snakker vi potensielt om modeller som er to-tre ganger raskere å kjøre enn dagens baseline uten å røre modellkvaliteten. Det ville være en vesentlig endring.
Som alltid med forskning av denne typen: produksjonsresultater på diverse arbeidsbelastninger vil avgjøre om 20,5% inferens-speedup holder. Men resultatene er lovende nok til at dette er verd å følge med på, spesielt for alle som har GPU-kostnader som en reell begrensning. Les også AI-nyheter fra mars 2026 for mer om hva som rører seg i GPU-optimalisering og LLM-ytelse. Og for en annen tilnærming til raskere inferens, se Mercury 2 – reasoning diffusion LLM som angriper problemet fra en helt annen vinkel.







