

Innhold Vis
Atlas er en inferensmotor for store språkmodeller skrevet i ren Rust og CUDA – uten Python, uten PyTorch – og er nå tilgjengelig som open source. Motoren ble opprinnelig bygget for å presse maksimal ytelse ut av NVIDIAs DGX Spark (GB10-maskinvare), og klarte å oppnå over 100 tokens per sekund stabilt på Qwen3.5-35B. Det som gjør Atlas interessant er ikke bare ytelsen – det er at teamet bak fullstendig forkastet den tradisjonelle Python-stacken og bygde alt fra bunnen av.
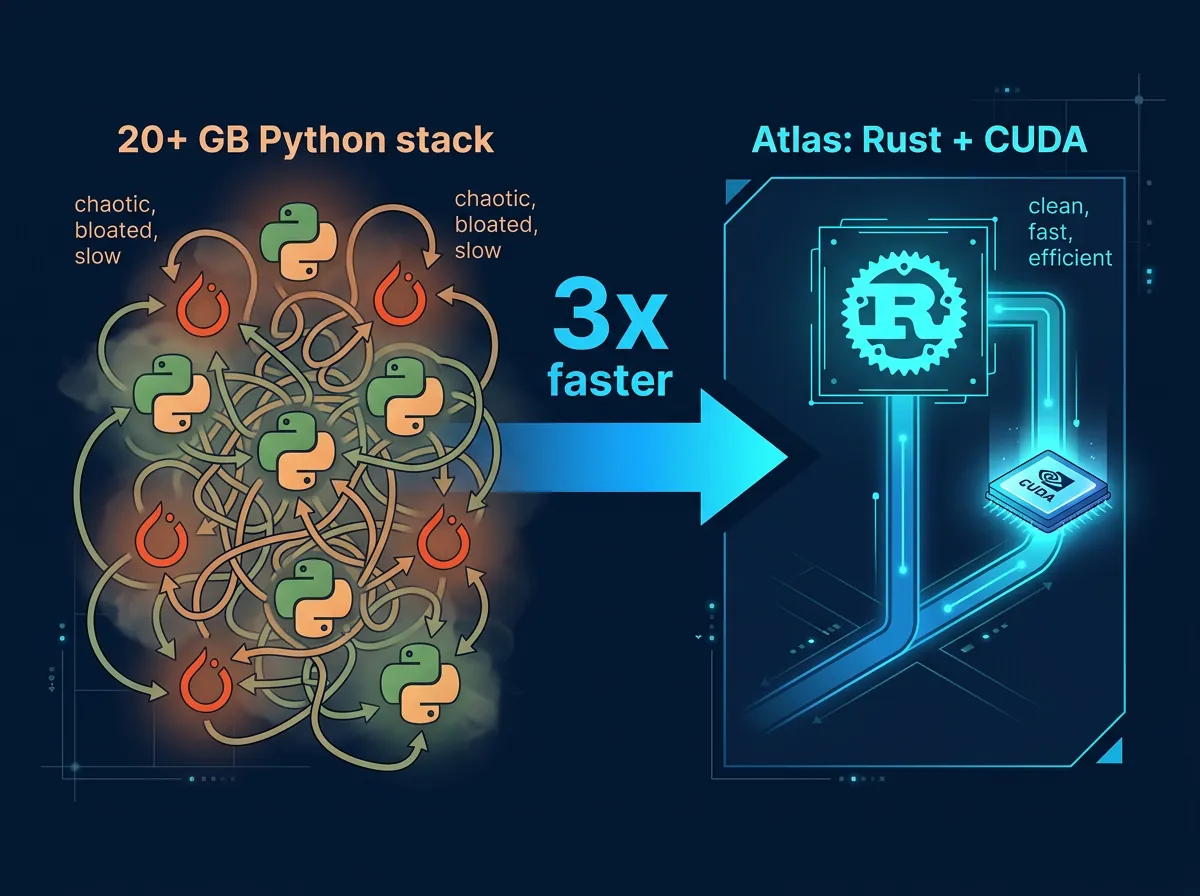
Kildekoden er tilgjengelig på GitHub under Avarok Cybersecurity med dual-lisens: AGPLv3 for community-bruk og kommersiell lisens for bedrifter som ikke vil binde seg til copyleft. Arkitekturen er et direkte svar på et konkret problem: 20+ GB Python-maskineri mellom prompten og GPU-en var flaskehalsen, ikke selve silisiumet.
Resultatet er et ~2,5 GB Docker-image med kaldstart under to minutter – mot vLLMs 40+ minutter på samme maskinvare. Det er en ganske sjenerøs margin å konkurrere mot.
Hva er Atlas, og hvorfor ble det bygget?
Atlas er et relativt nytt prosjekt, men bakgrunnen er konkret: teamet hadde en DGX Spark og ville vite hva den faktisk kunne gjøre. Det de fant var at den generiske Python-infrastrukturen i vLLM og lignende motorer spiste ytelse de ikke trengte å tape.
Løsningen var radikal: de rev ut hele stacken og erstattet den med Rust og tilpassede CUDA-kjerner skrevet direkte for SM121-arkitekturen i GB10. Over 20 egenutviklede kjerner, kompilert for nøyaktig den maskinvaren de kjørte på. Ingen generiske abstraksjoner. Ingen Python-runtime som sitter mellom prompt og GPU.
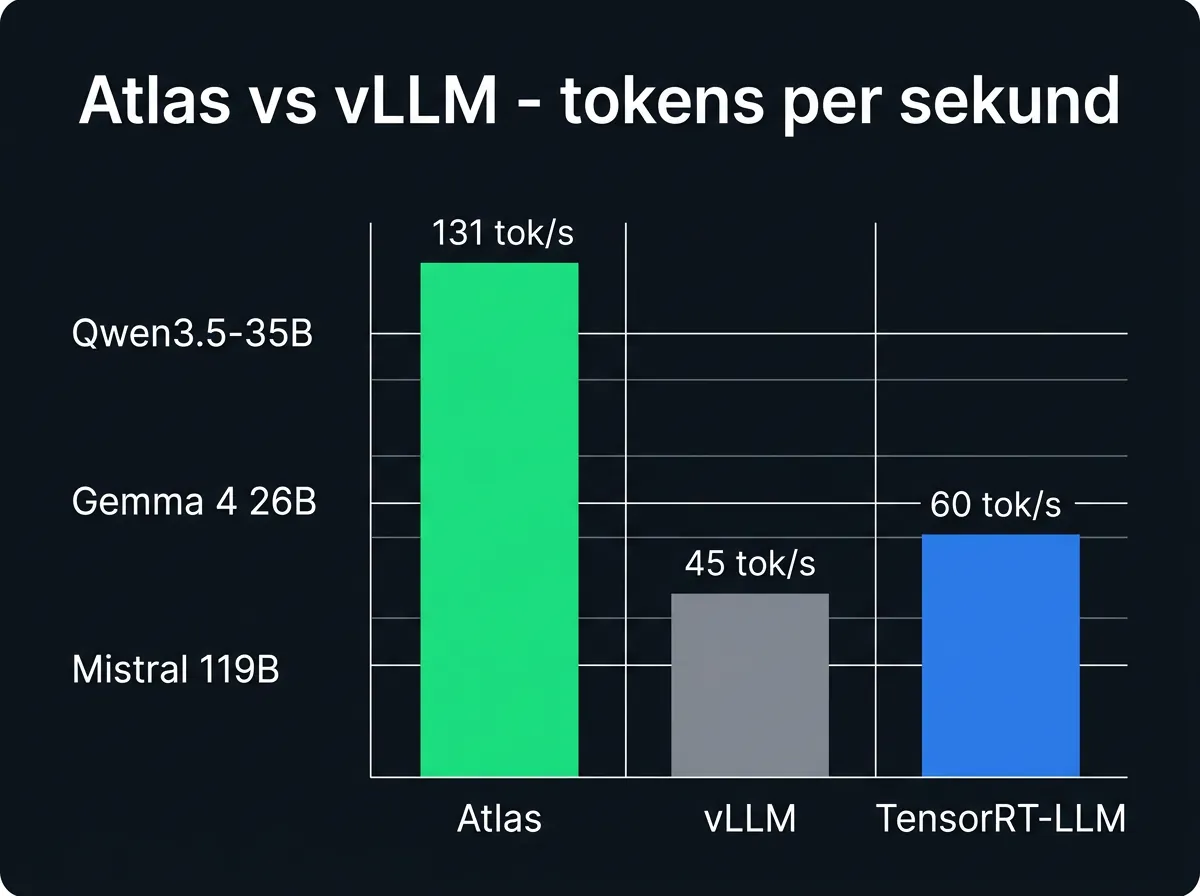
Sammenlignet med vLLM – som er den de fleste bruker for lokal inferens på seriøs maskinvare – måler Atlas seg slik på Qwen3.5-35B-A3B med MTP speculative decoding (K=2): 131 tokens per sekund. Det er «meaningfully faster» enn NVIDIAs egen vLLM-bygging på identisk maskinvare. Teamet har publisert reproduserbare benchmark-scripts, så det er mulig å verifisere tallene selv.
Hva slags ytelse kan du forvente?
Her er de målte hastighetene end-to-end gjennom HTTP-APIen på GB10-maskinvare:
- Qwen3.5-35B-A3B med MTP speculative decoding (K=2): 131 tokens/s
- Qwen3.5-35B-A3B Turbo4 KV: 77 tokens/s
- Qwen3-Next-80B FP8: 74 tokens/s
- Nemotron-3-Nano-30B FP8: 88 tokens/s
- Gemma 4-26B: 67 tokens/s
- Mistral Small 4 (119B) NVFP4: 33 tokens/s
Til sammenligning: er du vant til å jobbe med Claude via API, er 50-80 tokens per sekund allerede svært raskt i praksis. 131 tokens per sekund lokalt er noe de fleste aldri opplever. Tallene er imponerende – men husk at dette er på dedikert DGX Spark-maskinvare, som ikke akkurat er et hobbyprosjekt-budsjett.
De har også dokumentert spesifikke kjerne-forbedringer mot PyTorch-baseline: 18x raskere RoPE, 8x raskere Gated Delta Rule, og 3,9x raskere MoE W4A16 med 256 eksperter. Dette er ikke avrundede markedsføringstall – det er spesifikke operasjoner de har optimert hardt.
Hvilke modeller støtter Atlas?
Atlas bruker det de kaller «12 håndtunede mål» – kombinasjoner av maskinvare, modell og kvantisering. Støttede modeller inkluderer:
- Qwen3.5 (27B, 35B, 122B) og Qwen3.6 (35B)
- Qwen3-Next (80B) og Qwen3-VL (30B)
- Gemma 4 (26B og 31B)
- Mistral Small 4 (119B)
- MiniMax M2.7 (229B)
- Nemotron-H (30B og 120B)
Alle modeller kjøres fra én binær – riktig kjerneset velges automatisk ved oppstart basert på modellens config.json. Ingen bytte av images, ingen rebuilding per modell. Det er en elegant løsning på et problem de fleste Docker-baserte inferens-oppsett sliter med.
Jeg har tidligere skrevet om ATLAS som lokal kodingsverktøy på rimelig GPU-maskinvare – men dette er noe annet. Det er infrastrukturen under, selve inferensmotoren, som nå er åpnet opp.
Er Atlas bare for DGX Spark?
I sin nåværende form: ja, i stor grad. Atlas er optimert spesifikt for NVIDIAs GB10-arkitektur (SM121). De 20+ tilpassede CUDA-kjernene er kompilert for nettopp denne maskinvaren. Det er det som gir ytelsen – men det er også begrensningen.
DGX Spark er ikke billig maskinvare. Det er ikke noe du bestiller for å prøve ut en helg. Men for de som allerede har tilgang til GB10-maskinvare – enten privat eller gjennom jobb – er Atlas et svært interessant alternativ til vLLM og TensorRT-LLM.
Spørsmålet mange stiller er om støtte for bredere maskinvare kommer. Det er ikke bekreftet i dokumentasjonen, men dual-lisensmodellen (AGPLv3 community + kommersiell enterprise) tyder på at dette er ment å vokse. Et community kan bidra – og det er akkurat det open source-lanseringen legger til rette for.
Hva betyr dette for lokal AI-inferens generelt?
Det interessante med Atlas er ikke bare tallene – det er hva tallene forteller om tilstanden til inferens-infrastruktur generelt. Python og PyTorch har blitt standarden fordi de er fleksible og lette å jobbe med. Men fleksibilitet har en kostnad: 20+ GB med generisk maskineri som ikke vet noe om den spesifikke GPU-en den kjører på.
Atlas er en demonstrasjon av at det finnes ytelse å hente hvis man er villig til å skrive mer spesialisert kode. Rust gir minnehåndtering uten garbage collection og uten C++s kompleksitet. CUDA-kjerner skrevet for ett spesifikt chip kan gjøre ting PyTorch aldri kan.
Det er ikke første gang noen prøver dette – vibevoice.cpp er et annet eksempel på at Microsoft har fjernet Python fra lokale AI-kjøringer. Og prosjekter som LARQL viser at kreative arkitekturvalg kan gi uventet ytelse på billigere maskinvare. Men Atlas er kanskje det mest ambisiøse forsøket: fullstendig omskriving av hele stacken, fra HTTP-handler til kernel dispatch.
Spørsmålet er om dette er fremtiden for lokal inferens, eller en spesialisert løsning for en smal målgruppe med dyr maskinvare. Jeg heller mot at begge deler er sanne – Atlas er neppe for alle, men tilnærmingen vil påvirke hvordan andre tenker på inferensytelse fremover. Nvidia og CUDA-økosystemet er allerede godt kjent for å dominere, som jeg har skrevet om i den komplette Nvidia AI-guiden.
For de med DGX Spark eller GB10-maskinvare: kildekoden er tilgjengelig på GitHub, og AGPLv3-lisensen betyr at du kan bruke og bidra fritt. Benchmark-scripts er reproduserbare, og kaldstart under to minutter er et lavt skranke for å prøve ut.
Hva tenker du – er dette den retningen lokal inferens bør gå, eller er Python-stackens fleksibilitet verdt ytelseskostnaden?








1 kommentar