

Innhold Vis
ATLAS er et open source-prosjekt som kjører en 14 milliarder parameter AI-modell lokalt på en RTX 5060 Ti og oppnår 74,6% på LiveCodeBench – høyere enn Claude Sonnet 4.5’s 59,0% på samme test. Prosjektet dukket opp på Hacker News denne uken og skapte en livlig debatt om hva benchmarktall faktisk betyr.
En RTX 5060 Ti 16GB koster omtrent 5000 Kroner. Claude Sonnet 4.5 via API koster anslagsvis 0,066 dollar per oppgave på samme benchmark. ATLAS kjører den samme oppgaven for 0,004 dollar – lokalt, uten sky, uten datadeling. Tallene er unektelig imponerende. Men som vanlig med benchmarks er det mer under overflaten.
La meg grave litt i hva ATLAS faktisk er, hvordan det fungerer, og hva sammenligningen egentlig forteller oss.
Hva er ATLAS?
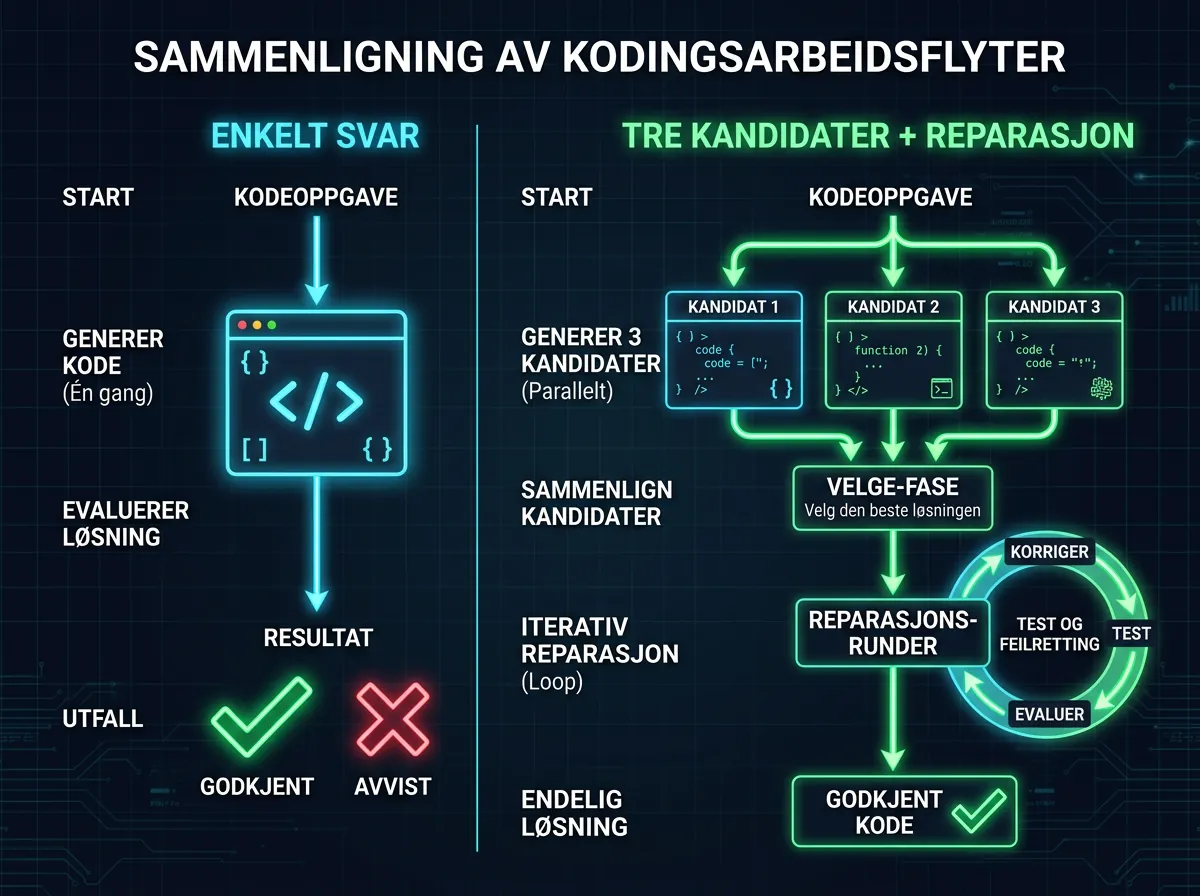
ATLAS står for Adaptive Test-time Learning and Autonomous Specialization. Det er ikke en ny modell – det er et rammeverk som pakker inn en eksisterende, frossen modell i intelligent infrastruktur. Selve hjernen er Qwen3-14B kvantisert til Q4_K_M-format, kjørende via en modifisert versjon av llama.cpp med spekulativ dekoding.
Det smarte med systemet er at det ikke prøver å lage en bedre modell. Det prøver å bruke en liten modell smartere. Tre faser i pipelinen:
- Generering: PlanSearch trekker ut begrensninger fra oppgaven. Budget Forcing kontrollerer antall tenkende tokens.
- Verifikasjon: Et energibasert embeddings-system scorer kandidatene. Koden kjøres i sandbox.
- Reparasjon: Feilede oppgaver genererer selvtest-tilfeller. PR-CoT (Problem-Repair Chain-of-Thought) fikser løsningene iterativt.
Resultatet: 74,6% pass@1-v(k=3) på LiveCodeBench. Claude Sonnet 4.5: 59,0%. Tall som ved første øyekast ser dramatiske ut.
Hva betyr egentlig «pass@1-v(k=3)»?
Her er det ærlige svaret: det er ikke samme testbetingelser som Claude brukes under.
«Pass@1-v(k=3)» betyr at systemet genererer tre kandidater, velger den beste, og kjører reparasjonsløkker til den fungerer eller gir opp. Claude Sonnet 4.5 genererer ett svar – direkte, uten iterasjon, uten reparasjon. Det er litt som å sammenligne en sprinter som løper en gang med en som får løpe tre ganger og velge den beste runden.
Jeg har skrevet om dette mønsteret tidligere – benchmarks forteller oss noe, men sjelden det vi tror de forteller. Tall uten kontekst er halvhjertet informasjon. ATLAS-tallene er ekte, men de representerer en annen arbeidsmodus enn det du får med Claude i en editor.
En kommentator på Hacker News traff spikeren på hodet: «you can make it pass the benchmarks, then you use it and it is not practically useful unlike an extremely general model.» Det er ikke feil. Benchmarks måler det de er designet for å måle. Ikke mer.
Hva koster det egentlig å kjøre ATLAS?
La oss se på de faktiske kostnadene. RTX 5060 Ti 16GB er den rimeligere Blackwell-GPU-en, priset rundt 5 000-5 500 kroner i Norge. Strøm til en RTX 5060 Ti i full last er omtrent 160-180 watt. En norsk strømpris på 1 krone per kWh betyr at det koster deg omtrent 15-18 øre per time i drift.
ATLAS er ikke rask. Systemet genererer tre kandidater og kjører reparasjonsrunder – det er designet for batch-prosessering, ikke interaktiv bruk. Du sitter ikke og venter på et svar mens du koder. Du sender inn en oppgave, går og tar deg en kaffe, og kommer tilbake til (forhåpentligvis) et fungerende svar.
For noen bruksområder er det faktisk greit. For daglig, interaktiv kodingshjelp er det mer tungvint enn å bruke Claude Code eller en lokal Ollama-instans.

Er Qwen3-14B egentlig bra nok lokalt?
Qwen3-14B er en solid modell – Alibaba har levert bra de siste rundene. Jeg er generelt skeptisk til kinesiske AI-selskaper ut fra et personvernperspektiv, men selve teknologien er ubestridelig god. Qwen3-serien scorer høyt på tvers av benchmarks, og 14B-varianten er håndterbar på 16GB VRAM.
Som jeg dekket i artikkelen om beste AI-verktøy i 2026, er lokale modeller i stadig bedre stand. For seks måneder siden var det en merkbar kvalitetsforskjell mellom frontier-API-modeller og det beste du kunne kjøre lokalt. Den forskjellen er blitt mindre – ikke borte, men merkbart smalere.
ATLAS bruker kvantisering (Q4_K_M) for å få modellen til å passe på 16GB. Det innebærer litt kvalitetstap sammenlignet med full presisjon, men langt mindre enn man kanskje skulle tro. Den store vektoren er fortsatt intakt. Metodikken rundt – generering, verifikasjon, reparasjon – kompenserer for mye av det som går tapt i kvantiseringen.
Hva er ATLAS best egnet for?
Batch-prosessering av kodingsoppgaver der du ikke er i en interaktiv arbeidsflyt. Tenk: automatisert kodegjennomgang, generering av testsuiter, refaktorering av store kodebaser der du kan la systemet jobbe i bakgrunnen mens du gjør noe annet. Ikke «hjelp meg med denne funksjonen nå» – mer «prosesser disse 200 filene over natten».
For den bruksscenarien er kostnadsargumentet faktisk overbevisende. 0,004 dollar per oppgave vs 0,066 dollar per API-kall er en reell forskjell over tid. Men hardware-investeringen på 5 000 kr pluss driftsstrøm betyr at break-even tar tid, avhengig av volum.
En annen sak verdt å merke seg: systemet fungerer dårligere på C++ og Rust ifølge kommentarer på Hacker News. Det er logisk – åpne modeller trener mye mer på Python og JavaScript enn på systemprogrammeringsspråk. Skal du jobbe med lavnivå-kode er ytelsesforspranget sannsynligvis lavere enn de oppgitte tallene.
Lokal AI for koding – er vi der ennå?
Delvis. ATLAS er imponerende engineering. Ideen om å pakke en frossen modell i et intelligent rammeverk som gjør systematisk verifikasjon og reparasjon er smart. Det er ikke «bare kjør Ollama og be om kode» – det er strukturert problemløsning på toppen av en åpen modell.
Men Claude Code er fortsatt bedre for det meste av det jeg gjør daglig – ikke nødvendigvis fordi modellen er bedre på isolerte benchmarks, men fordi hele opplevelsen er mer integrert. Du jobber med den mens du tenker, ikke etter. Den forstår konteksten i prosjektet ditt, ikke bare én oppgave av gangen. Og 59% på LiveCodeBench betyr ingenting for om den hjelper deg med å debugge et vanskelig edge-case i din spesifikke kodebase.
ATLAS er likevel et godt argument for at 5000 krs GPU-er kan gjøre mer enn de fleste tror. Lokale AI-løsninger modner raskt. Jeg ville holdt øye med dette prosjektet, og spesielt hva som skjer når noen tar metodikken og parer den med en modell trent spesifikt på koding.
Kildekoden er tilgjengelig på GitHub. Minimum krav: 16GB GPU VRAM og 14GB RAM. RHEL 9 er testet, men llama.cpp er bredt støttet på de fleste Linux-distroer.








1 kommentar