

Innhold Vis
Qwen-teamet hos Alibaba lanserte 28. april 2026 FlashQLA – et nytt bibliotek med høyytelseskjerner for lineær oppmerksomhet (linear attention), bygget på TileLang-rammeverket. Konkrete tall: 2-3 ganger raskere forward-pass og 2 ganger raskere backward-pass sammenlignet med eksisterende FLA Triton-kjerner på NVIDIA Hopper-GPU-er.
Bakgrunnen er enkel. Qwen3.5 og Qwen3.6 bruker begge Gated DeltaNet – en lineær oppmerksomhetsarkitektur som veksler mellom lineære lag og fullstendige attention-lag i omtrent 3:1-ratio. Det er en smart arkitektur, men den trenger rask infrastruktur for å utnytte potensialet. FlashQLA er den infrastrukturen.
Formålet er tydelig: agentic AI på personlige enheter. Ikke sky. Ikke et datasenter i nærheten. Maskinen din.
Hva er lineær oppmerksomhet – og hvorfor trenger vi raskere kjerner?
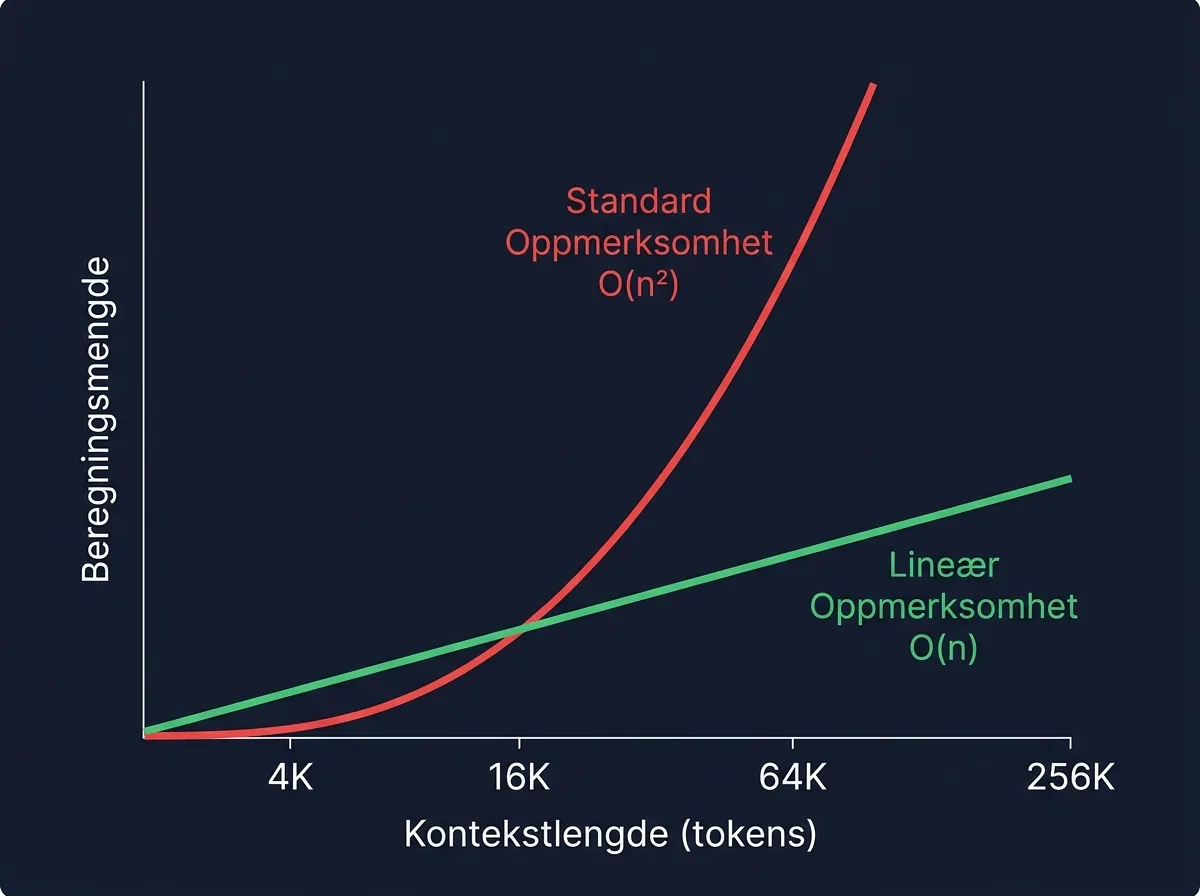
Standard transformer-oppmerksomhet (som i GPT-4, Claude, Gemini) skalerer kvadratisk med kontekstlengden. Dobler du kontekstvinduet, firedobler du beregningsmengden. Det er flaskehalsen som gjør lange sekvenser kostbare.
Lineær oppmerksomhet er svaret på dette. Den skalerer lineært – O(n) i stedet for O(n²). I praksis betyr det at modeller med lineær oppmerksomhet kan håndtere lange kontekster med drastisk lavere minnebruk og raskere hastighet. Som jeg dekket da Kimi lanserte Attention Residuals, er dette et av de mest aktive feltene i AI-arkitektur akkurat nå – alle leter etter måter å bryte den kvadratiske skalerings-veggen.
Qwen3.5 er et godt eksempel på gevinsten: bare 10 av 40 lag bruker KV-cache. Å gå fra 4096 til 65 536 tokens kontekst legger bare til 800 MB VRAM. Det er kvantitativt annerledes enn standard transformere der KV-cachen spiser minne eksponentielt.
Problemet er at lineær oppmerksomhet historisk har hatt dårligere GPU-utnyttelse enn standard attention fordi kjernene ikke var optimert godt nok. FlashQLA er Qwens forsøk på å løse akkurat dette.
Hva gjør FlashQLA teknisk?
Tre nøkkelinnovasjoner skiller FlashQLA fra tidligere implementasjoner:
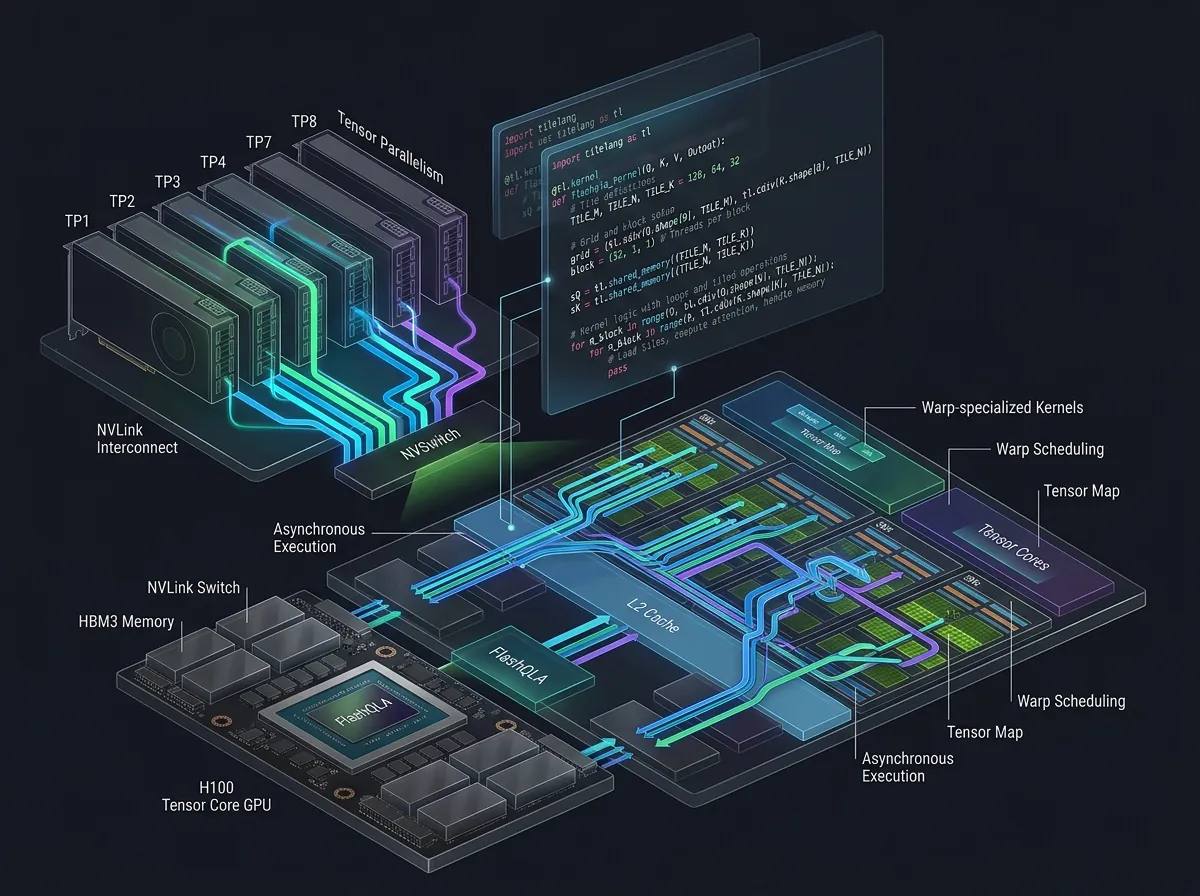
Gate-drevet automatisk intra-kort kontekstparallelisering (CP). Gated DeltaNet-arkitekturen bruker eksponentiell demping i gate-mekanismen. FlashQLA utnytter denne egenskapen til å automatisk parallellisere beregninger innenfor én GPU – uten at brukeren trenger å konfigurere noe. Dette er spesielt nyttig i tensor-parallelle oppsett (TP) og ved lange sekvenser, der SM-utnyttelsen (Streaming Multiprocessors) ellers ville vært lav.
Maskinvarevennlig algebraisk reformulering. Forward- og backward-flyten er redesignet fra bunnen for å redusere overhead på Tensor Cores, CUDA Cores og SFU-enheter – uten å ofre numerisk presisjon. Det høres abstrakt ut, men resultatet er det Qwen kaller «2-3x speedup» i praksis.
TileLang-fusjonerte warp-spesialiserte kjerner. I stedet for enten trinnvis dekomposisjon eller fullstendig fusjon, implementerer FlashQLA spesialiserte warp-kjerner som overlapper datamobilitet, tensorberegninger og CUDA-beregninger. TileLang-rammeverket gjør dette relativt rent å uttrykke i Python mens optimaliseringsdetaljer (pipelining, async copy, TMA på Hopper) håndteres automatisk.
Hvem er dette for – og hva kreves?
Kravene er ganske spesifikke. Du trenger:
- NVIDIA SM90 eller nyere (H100, H200)
- CUDA 12.8+
- PyTorch 2.8+
Det betyr at dette i dag er mest relevant for utviklere og forskere med tilgang til moderne GPU-er. Lignende mønster som Holotron-12B – ny infrastruktur som forutsetter siste generasjon hardware.
Navnet FlashQLA spiller tydelig på FlashAttention (Dao et al.) som revolusjonerte standard attention-ytelse for noen år siden. Samme logikk: ta en beregning alle bruker, implementer den radikalt mer effektivt på GPU-hardware, og slip den ut som open source.
Benchmarks fra biblioteket sammenligner mot Flash Linear Attention 0.5.0 og FlashInfer 0.6.9 på konfigurasjoner fra Qwen3.5/3.6 (ulike hoedimensjoner fra 8 til 64), over TP1 til TP8 (tensor-parallelisme). Gevinstene er spesielt store i TP-oppsett – akkurat den situasjonen der du kjører en modell fordelt over flere GPU-er.
Sammenhengen med Qwen3.6 og agentic AI
FlashQLA er ikke et isolert prosjekt. Det henger direkte sammen med Qwens modell-ambisjoner for 2026. Qwen3.6 – som nå er tilgjengelig på OpenRouter med opptil 1 million tokens kontekst – bruker Gated DeltaNet-arkitekturen som FlashQLA er optimalisert for.
Qwen3.6-35B-A3B er et godt eksempel: 35 milliarder parametere totalt, men bare 3 milliarder aktive ved inferens (sparse MoE). På SWE-bench Verified scorer den 73,4 – sterkest i klassen for agentic koding. Terminal-Bench 2.0, som tester en AI-agent som gjennomfører oppgaver i et ekte terminalmiljø med tre timers tidsfrist, gir Qwen3.6-35B-A3B 51,5 – høyest blant alle testede modeller.
Kombinasjonen er elegant: lav minnebruk (lineær oppmerksomhet), høy agentic ytelse (Qwen3.6-arkitektur), og nå raskere kjerner (FlashQLA). Puslespillebrikkene passer sammen.
Hva betyr dette for lokale AI-modeller?
Qwen beskriver målgruppen som «agentic AI på personlige enheter.» Det er ambisiøst. H100-kravet i dag er ikke akkurat «personlig enhet» – men veien peker tydelig i retning av at disse optimeringene siler nedover til mer tilgjengelig hardware over tid. Slik har det alltid vært i GPU-programmeringshistorikken.
Den praktiske konsekvensen nå er treningshastighet og inferenshastighet for de som jobber med Qwen3.5/3.6-arkitekturer på Hopper-hardware. 2-3 ganger raskere forward-pass i trening er ikke trivielt – det betyr kortere eksperimentsykluser og lavere kostnader per treningsrunde.
For inferens er gevinsten spesielt uttalt ved lange kontekster og i TP-oppsett. Akkurat det som trengs for agentic workflows der modellen må prosessere lange verktøyhistorikker, kode-repos eller dokumenter i ett strekk.
Jeg er skeptisk til kinesiske modeller generelt – og Qwen er ikke unntaket der. Men selve det tekniske arbeidet her er solid. Vi ser det samme mønsteret som med MTP og speculative decoding: ny infrastruktur som gjør modeller raskere uten å endre selve modellvektene. Det er nyttig uavhengig av hvem som lager det.
FlashQLA er tilgjengelig på GitHub under MIT-lisens. Installer med git clone og pip install -v .. Benchmark-filene i repoet dokumenterer ytelsesmålingene i detalj.








1 kommentar