

Innhold Vis
FastDMS er en åpen referanseimplementasjon av Dynamic Memory Sparsification (DMS) – en KV-cache-komprimeringsteknologi som opprinnelig ble publisert av forskere fra NVIDIA, University of Warsaw og University of Edinburgh. Den som nå har bygget FastDMS rapporterer 6,4x KV-cache-komprimering med lavere perplexity-tap enn forventet, og hastigheten overgår vLLM BF16 og FP8 kjøringer. Det er ikke en liten påstand.
KV-cachen er en av de aller største flaskehalsene i moderne LLM-inferens. Problemet er enkelt: Transformermodeller må lagre nøkkel- og verdivektorer for hvert token i konteksten. Jo lengre kontekst, desto mer minne. Vil du kjøre Llama 3 med 128K kontekst? Da er KV-cachen gjerne mer krevende enn selve modellvekterne. Det er noe Google slet med i TurboQuant-arbeidet sitt, og det er kjernen av hva DMS og FastDMS prøver å løse.
Det interessante med FastDMS er at dette ikke er et kommersielt produkt eller et stor-lab-paper. Det er en enkeltperson som fant forskningsresultatene overbevisende nok til å verifisere dem selv – og endte opp med noe som faktisk fungerer i produksjon.
Hva er Dynamic Memory Sparsification (DMS)?
DMS er en KV-cache-sparsifiseringsteknikk som ble publisert i 2024. Kjerneideen er learned per-head token eviction – modellen lærer seg, per attention-head, hvilke tokens som er viktige å beholde og hvilke som kan forkastes.
Det originale papiret fra NVIDIA, University of Warsaw og University of Edinburgh rapporterte opptil 8x KV-cache-komprimering. Det høres imponerende ut. Men «opptil 8x» er den slags tall som kan skjule mye variasjon – noen konfigurasjoner gir 8x, andre kanskje 2x. Spørsmålet er hva som skjer med modellkvaliteten underveis.
DMS sin styrke er at den faktisk trener inn en liten eviction-policy per attention-head. Modellen bestemmer selv hva den vil huske. Det er i motsetning til treningsfrie metoder som brute-force velger hvilke tokens å forkaste basert på oppmerksomhetsvekter alene. Trente metoder er generelt mer presise – prisen er at du trenger noen tusen treningssteg for å kalibrere modellen.
Hva gjør FastDMS konkret?
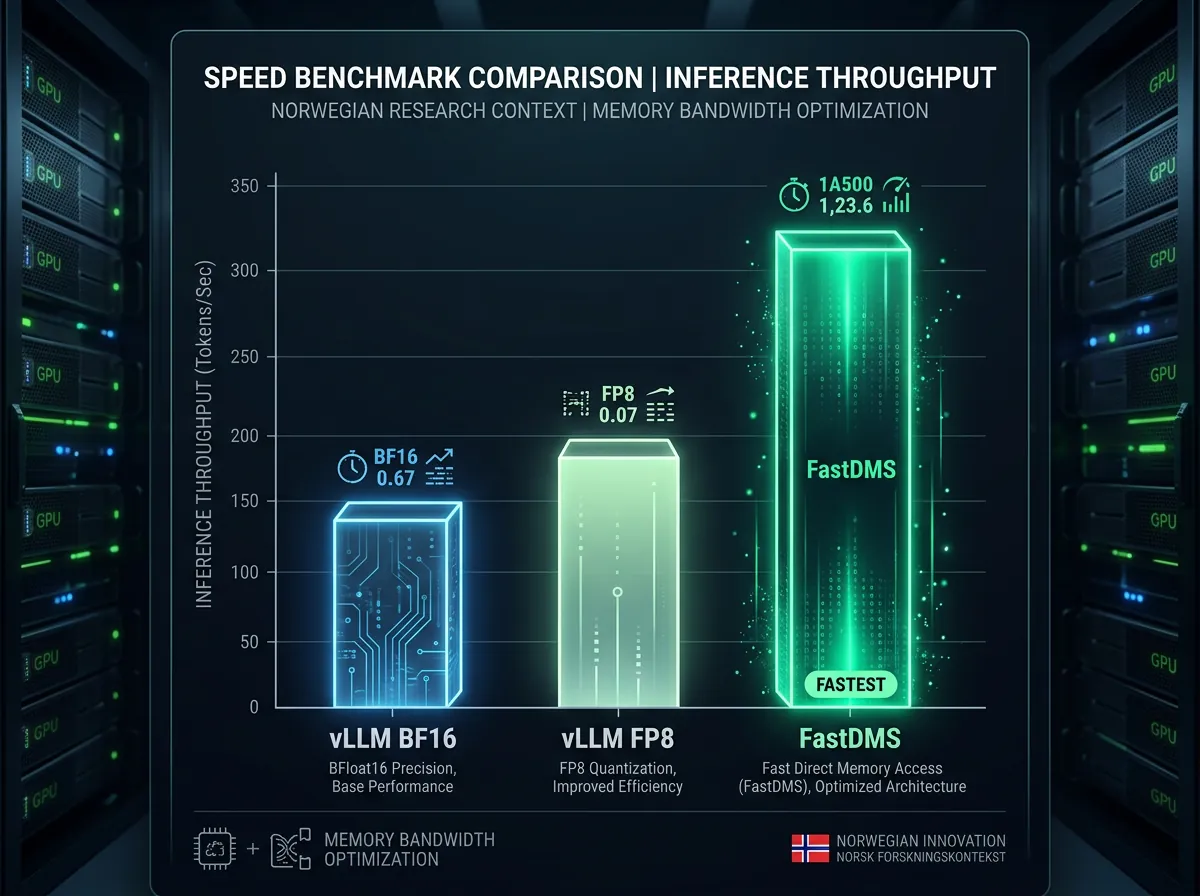
FastDMS er en referanseimplementasjon og trainer bygget for å verifisere DMS-resultatene. Kjørt på WikiText-2 med Llama 3.2 1B viser implementasjonen at det er mulig å oppnå 6,4x KV-cache-komprimering med overraskende lite kvalitetstap.
Resultatene fra implementasjonen er presentert som sammenligningstabell med PPL delta (perplexity-endring) og KLD (Kullback-Leibler divergence i nats/token) som kvalitetsmål. Lavere PPL delta og lavere KLD betyr at modellen oppfører seg mer likt originalen. 6,4x kompresjon med lav KLD er et sterkt resultat.
Men tallene er én ting. Det virkelig interessante er at FastDMS overgår vLLM – standardverktøyet for høyytelses LLM-inferens – i ren hastighet. BF16 er full presisjon, FP8 er allerede kvantisert inferens. At en KV-cache-komprimeringsmetode slår begge på gjennomstrømning antyder at minnebåndbredde er den reelle begrensningen, ikke beregning.

Hvorfor er KV-cache-komprimering viktig akkurat nå?
Kontekstvinduer har eksplodert i størrelse de siste to årene. Claude 3.7 og Gemini 2.5 Pro håndterer millioner av tokens. Llama 4 Scout kjører 10 millioner tokens. Det er revolusjonerende for hva modellene kan gjøre – men KV-cachen vokser lineært med kontekstlengden.
For en modell med 128K kontekst kan KV-cachen lett bruke 20-40 GB GPU-minne alene. Det er ikke bærekraftig for lokale kjøringer eller for tjenester som vil betjene mange samtidige brukere. PRISM-prosjektet utforsker fotonisk chip-arkitektur som alternativ – men det er langsiktig forskning. DMS og FastDMS løser problemet med programvare, i dag, på eksisterende hardware.
6,4x komprimering betyr i praksis at du kan kjøre tilsvarende lange kontekster på en brøkdel av GPU-minnet. Eller du kan kjøre mange flere parallelle forespørsler på samme maskin. Begge deler er verdifullt – enten du kjører lokalt eller bygger tjenester.
Hva skiller DMS fra kvantiseringsbaserte metoder som TurboQuant?
Det finnes flere tilnærminger til KV-cache-komprimering, og det er verdt å sette FastDMS i kontekst. TurboQuant fra Google bruker kvantisering – 3 bits per verdi – og rapporterer 6x minnereduksjon med imponerende benchmark-tall. Men kvantisering og sparsifisering er fundamentalt ulike metoder.
Kvantisering (TurboQuant, PolarQuant, QJL) beholder alle tokens men representerer dem med lavere presisjon. Sparsifisering (DMS, FastDMS) beholder full presisjon men kaster tokens som er vurdert som uviktige. Begge har styrker og svakheter: kvantisering kan påvirke numerisk stabilitet ved veldig lav bit-bredde, sparsifisering kan feile hvis eviction-policy ikke fanger opp alle viktige tokens.
I praksis er de komplementære – og en kombinasjon av kvantisering og sparsifisering er et naturlig neste steg. Det er faktisk hva det oppdaterte DMS-papiret «Inference-Time Hyper-Scaling with KV Cache Compression» (akseptert til NeurIPS 2025) utforsker videre, med eksperimenter på Qwen-R1 32B som viser tydelige forbedringer på AIME, GPQA og LiveCodeBench.
Er FastDMS produksjonsklart?
FastDMS er en referanseimplementasjon – det er ikke et ferdig bibliotek med PyPI-pakke og dokumentasjon klar for drop-in i eksisterende pipelines. Men det er mer enn et proof-of-concept. Den som har bygget dette har vist at resultatene lar seg replisere, at hastigheten er reell, og at tap i modellkvalitet er akseptabel.
Det er faktisk slik mange gode open source-prosjekter starter. Noen finner et paper interessant, verifiserer det, deler koden. Deretter bygger fellesskapet videre. LocalLLaMA-tråden som presenterte FastDMS er allerede full av folk som vil teste, integrere og forbedre.
For deg som kjører Llama eller lignende modeller lokalt, er FastDMS noe å følge med på. Særlig hvis du sliter med GPU-minne på lange kontekster – og det gjør de fleste som ikke har tilgang til H100-klynger. Å kombinere FastDMS med eksisterende kvantisering (AWQ, GPTQ) kan potensielt gjøre det mulig å kjøre vesentlig lengre kontekster på forbruker-GPU.
Hva tenker du? Er KV-cache-komprimering noe du har savnet gode verktøy for, eller er det andre flaskehalser i lokal LLM-kjøring som plager deg mer?







