

Innhold Vis
TurboQuant er Googles nye komprimeringsalgoritme for store språkmodeller, lansert 25. mars 2026 og presentert på ICLR 2026. Algoritmen komprimerer KV-cachen (key-value cache) ned til kun 3 bits – uten noen form for nøyakhetstap og uten at modellen trenger ny trening. På NVIDIA H100-akseleratorer gir 4-bits komprimering opptil 8 ganger raskere ytelse sammenlignet med ukomprimert 32-bits presisjon.
Dette er den typen forskning som ikke får store AI-overskrifter, men som faktisk betyr noe for alle som jobber med LLM-er i praksis. KV-cache er en av de mest kjente flaskehalsene når du kjører store modeller – den vokser lineært med kontekstlengden og spiser opp GPU-minne i rasende tempo. TurboQuant angriper akkurat dette problemet, og gjør det med et matematisk fundament som er imponerende.
Her er hva du trenger å vite.
Hva er KV-cache, og hvorfor er det et problem?
Når en LLM prosesserer tekst, lagrer den mellomliggende beregninger i en KV-cache (key-value cache) – et slags «arbeidsminne» som inneholder historikken over hva modellen har sett i kontekstvinduet. Jo lengre konteksten er, jo mer plass krever denne cachen.
Med modeller som nå tilbyr kontekstvinduer på hundretusenvis av tokens (Claude 3.7 med 200 000 tokens, Gemini 1.5 Pro med 1 million tokens), kan KV-cachen alene ta opp store mengder GPU-minne. Det begrenser hvor mange samtidige brukere du kan serve, og det setter tak på kontekstlengden du kan tilby i praksis. For de som driver produksjonssystemer med LLM-er, er dette en real hodepine.
Her er TurboQuant inne i bildet.

Hvordan fungerer TurboQuant?
TurboQuant kombinerer to algoritmer som Google Research har utviklet: PolarQuant og QJL (Quantized Johnson-Lindenstrauss). Begge presenteres på AISTATS 2026 som separate bidrag, men TurboQuant er kombinasjonen som gjør dem kraftfulle sammen.
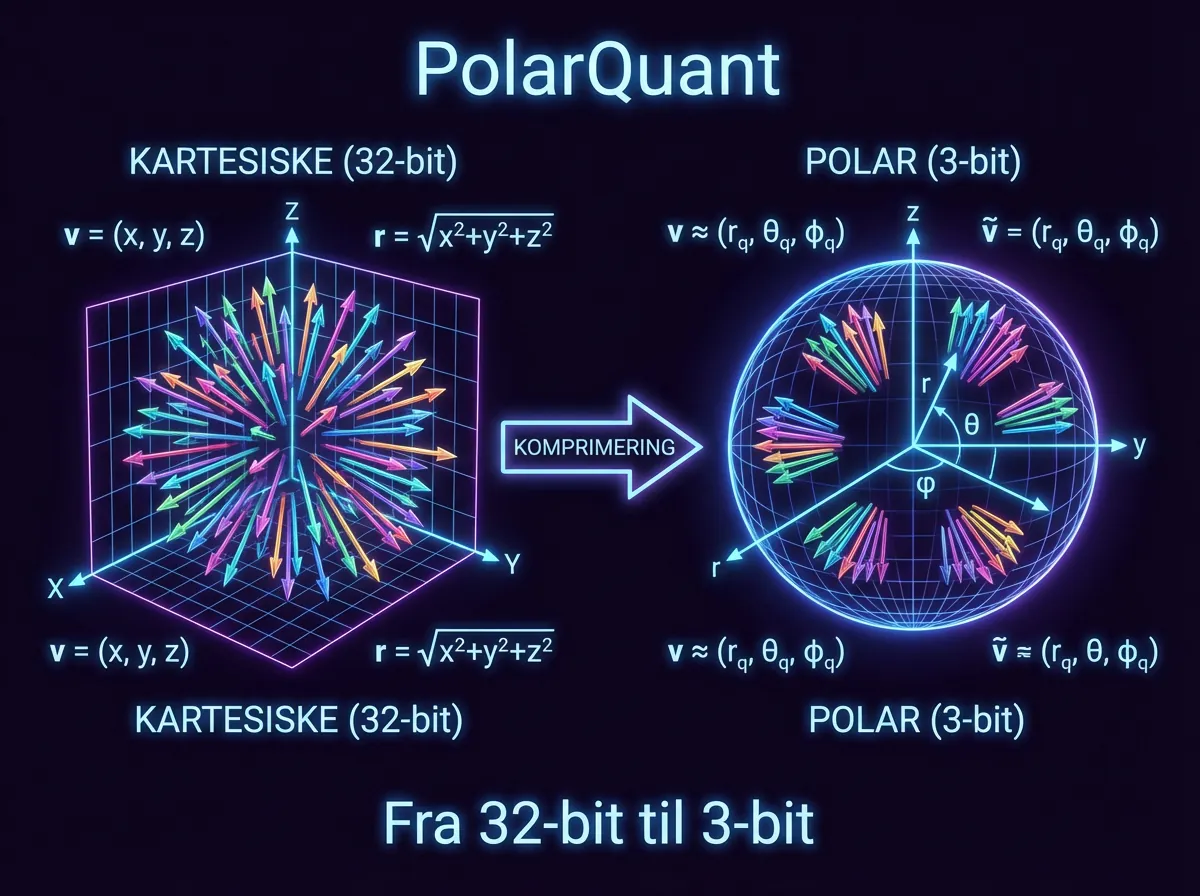
PolarQuant håndterer hoveddelen av komprimeringsarbeidet. I stedet for å jobbe med vektorene i kartesiske koordinater (X, Y, Z), roterer algoritmen dataene tilfeldig og konverterer dem til polarkoordinater (radius og vinkel). Det høres kanskje akademisk ut, men poenget er praktisk: mønsteret av vinkler er sterkt konsentrert og forutsigbart, noe som gjør at en standard høykvalitetskompressor kan anvendes per del av vektoren individuelt – uten den kostbare normaliseringsprosessen som ellers kreves. Minneoverheadet forsvinner.
QJL-algoritmen tar seg av den siste biten. Den bruker Johnson-Lindenstrauss-transformasjonen til å bevare avstandene mellom datapunkter mens den reduserer hver vektorverdi til en enkelt tegnbit (+1 eller -1). Null minneoverhead. En spesiell estimator sørger for at nøyaktigheten i oppmerksomhetsberegningene opprettholdes.
Resultatet er en KV-cache komprimert til 3 bits – langt ned fra de 16 eller 32 bitene som er standard – med det Google kaller «perfect downstream results across all benchmarks».
Hva sier resultatene?
Testene er kjørt på Llama-3.1-8B-Instruct, Gemma og Mistral. Benchmarkene inkluderer LongBench, Needle In A Haystack, ZeroSCROLLS, RULER og L-Eval – en ganske bred dekning av både spørsmål-svar, kodegenerering og oppsummeringsoppgaver.
Tallene fra Google Research:
- Minst 6 ganger reduksjon i KV-cache-minnebruk uten nøyakhetstap
- Opptil 8 ganger raskere ytelse med 4-bits komprimering på H100 GPU-er sammenlignet med ukomprimert 32-bits
- Ingen behov for ytterligere trening eller finjustering av modellen
- Negligibel runtime overhead
På vektorsøk (en annen kjernefunksjon i semantisk søk og RAG-systemer) overgår TurboQuant etablerte metoder som PQ og RabbitQ på GloVe-datasett med d=200. Optimal 1@k recall-ratio med bedre nøyaktighet enn baseline.
Jeg er generelt skeptisk til benchmarks som eneste argument – det er lett å velge tester som viser det du vil vise. Men her er det kombinasjonen av matematisk bevis og praktiske tall på kjente benchmarks som gjør det interessant. Algoritmen opererer nær teoretiske nedre grenser for hva som er mulig å oppnå, ifølge Google Research selv. Det er ikke markedsføring, det er matematikk.
Hva betyr dette i praksis?
For deg som kjører LLM-er lokalt på en RTX 4090 (24 GB VRAM), eller bruker skybaserte API-er der kostnad avhenger av beregningsbruk – dette er relevant. Seks ganger lavere minnebruk betyr at du kan:
- Kjøre mye lengre kontekstvinduer på samme hardware
- Serve langt flere samtidige brukere med samme GPU-resurser
- Redusere kostnaden per inferens betydelig i produksjon
Og det uten å ofre nøyaktighet. Det er ganske sjeldent at du kan få alt tre på én gang.
For de som driver RAG-systemer (Retrieval-Augmented Generation) er vektorsøk-delen også interessant. Semantisk søk i milliarder av vektorer er ressurskrevende – TurboQuant adresserer nøyaktig den flaskehalsen og gjør indeksbygging og spørringsprosessering mer effektivt.
Er TurboQuant tilgjengelig nå?
Per lansering er TurboQuant et forskningsbidrag presentert på ICLR 2026. Google har publisert blogginnlegget og forskningsartiklene, men det er ikke en klar «last ned og installer»-pakke ennå. Det kommer gjerne i form av integrasjon i eksisterende rammeverk over tid – enten direkte fra Google eller fra open source-samfunnet som plukker opp teknikken.
Litt av det samme skjedde med andre kvantiseringsteknikker – GPTQ og AWQ kom som forskningsresultater, og kort tid etter var de tilgjengelige gjennom Hugging Face og llama.cpp. Det er rimelig å forvente noe lignende her, spesielt siden metodene er matematisk velbegrunnet og resultatorientert.
Jeg har tidligere skrevet om Claw Compactor som komprimerer LLM-tokens med 54 prosent uten ML-avhengigheter. TurboQuant angriper en annen del av problemet – der Claw Compactor komprimerer inndata-tokens, tar TurboQuant seg av KV-cachen under selve inferensen. Komplementære teknikker som godt kan brukes sammen.
Hvorfor kaller folk dette «Pied Piper»?
TechCrunch og andre har pekt på likheten med «Pied Piper» fra TV-serien Silicon Valley – den fiktive komprimeringsalgoritmen som skulle revolusjonere internet-infrastrukturen. Det er et morsomt sammenfall, og litt ironisk at Googles faktiske gjennombrudd ligner så mye på en fiksjon fra 2014.
Men i motsetning til Pied Piper, leverer TurboQuant faktiske tall på faktiske modeller på faktisk hardware. H100-en er ikke fiktiv.
Nå gjenstår det å se om og når dette finner veien inn i produksjonsrammeverk. Det er der det virkelig teller.
Les komplett oversikt: TurboQuant – Alt du trenger å vite om Googles AI-gjennombrudd.








4 kommentarer