

Innhold Vis
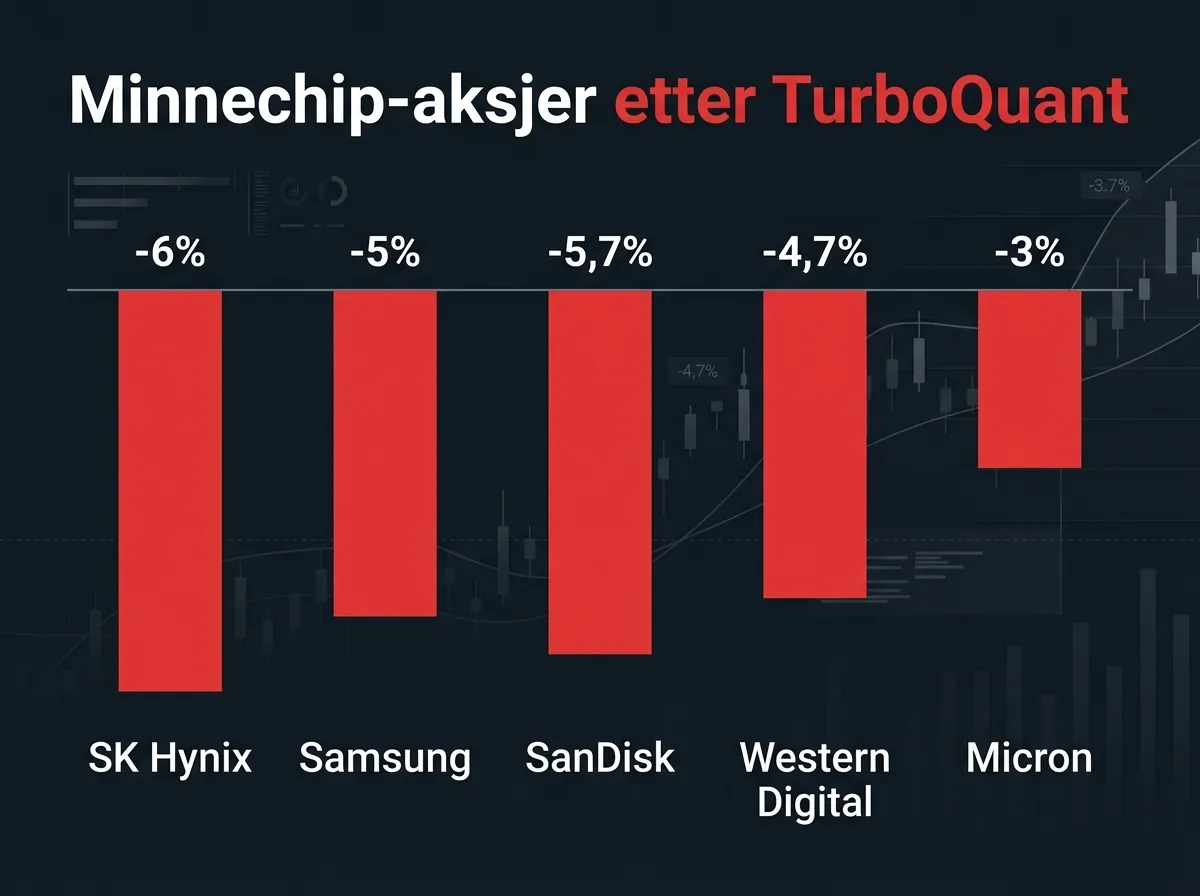
Da Google publiserte TurboQuant-forskningen i slutten av mars 2026, krasjet minnechip-aksjene. SK Hynix ned 6%, Samsung ned 5%, SanDisk ned 5,7%, Western Digital ned 4,7%, Micron ned 3%. Logikken var enkel og umiddelbar: TurboQuant gir 6x lavere minnebehov. Lavere minnebehov = færre minnechips. Færre minnechips = svakere etterspørsel. Aksjekursene følger logikken ned.
Problemet? Logikken er feil. Eller mer presist: den ser bare ett skritt fremover i stedet for tre.
Dette er den klassiske misforståelsen av teknologiske gjennombrudd. Markedet priset inn en fremtid der AI bruker det samme antallet modeller som i dag, bare med halvparten av minnet. Men det er ikke slik teknologi fungerer. Det er ikke slik noe fungerer.
Hva skjedde egentlig i aksjemarkedet?
La oss se på tallene. SK Hynix, som lager mesteparten av HBM-minnet (High Bandwidth Memory) som brukes i Nvidias H100 og H200-brikker, falt 6% på én dag. Det er ikke et lite pip – det tilsvarer milliardverdier fordamper på timer. Samsung, Western Digital, Micron: alle ned mellom 3 og 6%.
Investorene leste TurboQuant-rapporten og trakk en konsekvens: Googles nye KV-cache-algoritme komprimerer minnebehovet med faktor 6. En modell som tidligere krevde 600 GB minne, klarer seg nå med 100 GB. Det betyr at hyperscalers som Google og Microsoft kan kjøre samme workload med dramatisk færre minnemoduler.
Regnestykket virker åpenbart. Og det er akkurat der feilen oppstår.
Hva er Jevons paradoks – og hvorfor er det relevant nå?
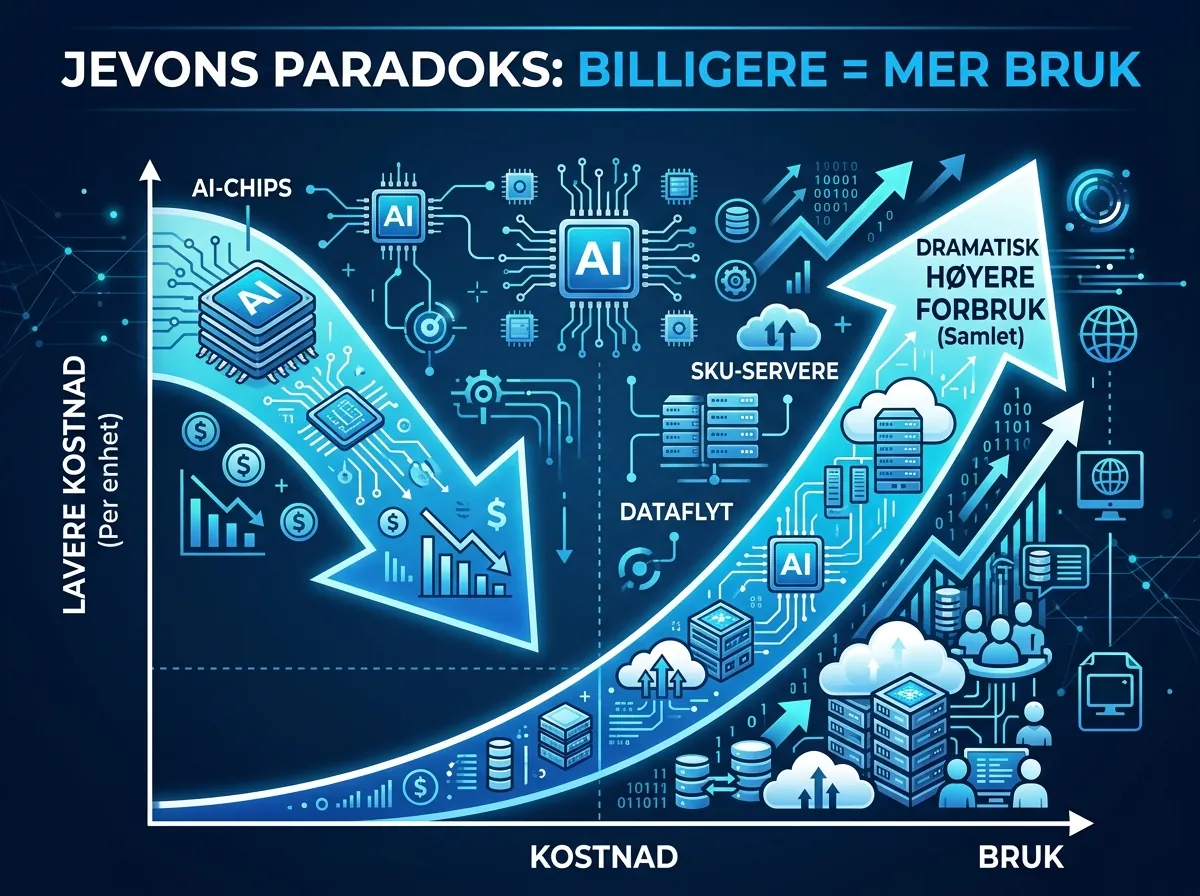
I 1865 observerte den britiske økonomen William Stanley Jevons noe merkelig med kullforbruket i England. James Watt hadde nettopp forbedret dampmaskinens effektivitet dramatisk – den brukte langt mindre kull per arbeidsenhet. Logisk konsekvens: det totale kullforbruket burde falle. Det skjedde nøyaktig det motsatte. Mer effektive maskiner = billigere produksjon = mer aktivitet = eksplosiv vekst i kullforbruk.
Det er Jevons paradoks. Og det gjentar seg med monoton regelmessighet gjennom industrihistorien.
Bilmotorer ble mer drivstoffeffektive på 1980- og 90-tallet. Bilene forbruker likevel mer drivstoff totalt i dag enn noen gang – fordi folk kjører lenger, kjøper større biler, og det er flere biler. LED-belysning bruker 80% mindre strøm enn glødepærer. Globalt strømforbruk til belysning er ikke 80% lavere. LED-revolusjonen åpnet for bruk av lys i kontekster som aldri var mulig med glødepærer – billboards, LED-skjermer, natlys i hele byer.
Og AI-compute? Samme mønster, alltid. AWS EC2-priser har falt med 90% siden 2006. Skyforbruket har ikke falt med 90%. Det har eksplodert.
Vil billigere AI-inference faktisk redusere minneetterspørselen?
Nei. Det vil øke den.
Når inference-kostnaden halveres, skjer to ting samtidig. For det første: use cases som var for dyre blir plutselig lønnsomme. Tenk på alle AI-applikasjoner som i dag er skrinlagt fordi kostnaden per API-kall er for høy for business-caset. En AI-assistent som leser og analyserer alle innkommende e-poster i en bedrift: i dag for dyrt. Med halverte inference-kostnader: muligens interessant. Med TurboQuant: kanskje åpenbart lønnsomt.
For det andre: eksisterende bruk skalerer opp. Selskaper som i dag begrenser bruk av AI-agenter på grunn av kostnad, vil slippe opp på den begrensningen. En automatiseringsworkflow som kjøres én gang om dagen fordi det er dyrt, kan plutselig kjøres hvert 10. minutt. Volum multipliseres.
Historien er klar. DeepSeek R1 kom i januar 2025 og reduserte prisen på AI-inference med anslagsvis 80-90% sammenlignet med GPT-4-klassen. Resultatet? Nvidias aksje falt dramatisk den dagen. Deretter klatret den tilbake og satt nye rekorder. Fordi billigere inference skapte mer etterspørsel, ikke mindre.
Hva er TurboQuant egentlig – software eller hardware?
Her er poenget markedet ser ut til å ha gått glipp av: TurboQuant krever ikke nye chips. Ingen retraining. Ingen fine-tuning. Ingen endring i modellvektene.
Du bytter ut KV-cache-algoritmen. Det er det. Modellen er identisk. Hardwaren er identisk. Infrastrukturen er identisk. Det er ren software-optimalisering på toppen av eksisterende stack.
Sett det opp mot hva som faktisk ville skadet minnechip-etterspørselen: en ny bølge av modeller trent med dramatisk lavere minnearkitektur. Det skjer ikke med TurboQuant. TurboQuant gjør eksisterende modeller billigere å kjøre – og sender dermed mer etterspørsel etter de samme modellene.
Det er faktisk det beste caset for minnechip-produsentene. Ikke en teknologi som gjør hardwaren deres overflødig, men en teknologi som gjør hardwaren billigere å utnytte – og dermed driver etterspørselen opp.
Hvem vinner egentlig på TurboQuant?
La oss gå gjennom listen av vinnere – den er lengre enn markedet ser ut til å ha regnet med.
Google selv. De drifter serverfarmer i en skala det er vanskelig å ta innover seg. Hvert prosentpoeng reduksjon i inference-kostnad = hundrevis av millioner dollar i sparte driftskostnader. TurboQuant kan potensielt halvere kostnadene på Googles egne systemer. Det frigjør kapital til å skalere enda mer.
API-brukere. Når Google (og andre som adopterer algoritmen) kan kjøre modeller for halvparten, faller API-prisene. Det betyr billigere kall for alle som bygger på toppen av AI-APIer. Konkurransen i API-markedet er brutal nok til at effektiviseringsgevinster sendes videre til kundene.
Agentic AI. Dette er kanskje det mest undervurderte punktet. AI-agenter som kjører autonomt – planlegger, utfører, evaluerer – er extraordinært resource-intensive. En langkjørende agent kan generere tusenvis av tokens i KV-cache per sesjon. Med TurboQuant blir disse agentene 6x billigere å kjøre. Use cases som var teoretisk interessante men praktisk umulige på grunn av kostnader, blir realiserbare.
Lange kontekstvinduer. En av de praktiske begrensningene ved 1-million-token kontekstvinduer er at de er dyrt å prosessere. KV-cachen vokser med kontekststørrelsen. Halveres minnebehovet for cache, halveres kostnaden ved å bruke lange kontekstvinduer – og dermed øker bruken.
Er TurboQuant en trussel mot Nvidia?
Kort svar: nei. Litt lengre svar: nei, og her er hvorfor.
Nvidia dominerer AI-treningsmarkedet med sine H100- og H200-brikker. TurboQuant berører ikke trening – det berører inference. Og i inference-markedet er logikken den samme som over: billigere inference driver mer volum, mer volum driver mer etterspørsel etter compute.
Det mer interessante spørsmålet er hva TurboQuant betyr for Nvidias konkurrenter – Google TPU, Amazon Trainium, til og med Groqs LPU-teknologi. En software-gjennombrudd på KV-cache-nivå er prinsipielt hardware-agnostisk. Den kan implementeres på alle prosessor-arkitekturer, ikke bare Nvidia GPUer. Det kan faktisk svekke Nvidias komparative fordel hvis effektiviseringsgevinsten er jevnere distribuert på tvers av hardware-plattformer.
Men det er et subtilt og langsiktig poeng – ikke en case for at minnechip-produsentene kollektivt skal falle 5-6% på én dag.
Hva betyr det at Google deler dette åpent?
Her er noe jeg tenker er verdt å stoppe opp ved.
Google kunne holdt TurboQuant internt. De kunne tatt alle marginalfordelene selv – billigere driftkostnader uten at konkurrentene fikk tilgang. Det ville vært rasjonelt fra et snevert perspektiv.
I stedet publiserte de forskningen åpent. Akkurat som Google i 2017 publiserte «Attention is All You Need» – transformer-arkitekturen som la grunnlaget for hele den moderne AI-industrien, inklusive OpenAI og Anthropic. Konkurrentene dro nytte av forskningen. Og Google? De opplevde eksplosiv vekst i bruken av sine tjenester, fordi de la grunnlaget for en industri som alle drar nytte av.
Det er ikke naivt altruisme. Det er en bevisst strategi om at åpen innovasjon løfter alle båter – inkludert deres egne. Infrastruktur-selskaper som Google tjener på at AI-industrien totalt sett vokser, ikke på å kontrollere en liten del av en liten kake.
Og ja – det er et klarere eksempel på at åpne standarder og delt kunnskap driver fremgang mer effektivt enn lukkede systemer og regulering. Det er ikke et tilfelle at de store gjennombruddene i AI-historien – transformere, RLHF, open-source-modellene – har kommet fra forskningsmiljøer og selskaper som valgte å dele. Ikke fra reguleringsorganer som bestemte hva som var «trygt nok» til å publiseres.
Hva bør langsiktige investorer tenke på nå?
Jeg er ikke finansrådgiver, og dette er absolutt ikke investeringsråd. Men jeg finner det vanskelig å se logikken i at minnechip-aksjer skal falle varig på bakgrunn av TurboQuant.
Kortsiktig markedsreaksjon basert på overfladisk lesing av nyheten? Forståelig. Det skjer. Men TurboQuant adresserer én ineffektivitet i én del av inference-kjeden. Den løser ikke compute-problemet generelt. Trening av neste generasjon modeller vil fremdeles kreve mer compute, ikke mindre. Og billigere inference vil – historisk sett, gang på gang – drive mer volum.
DeepSeek-sjokket i januar 2025 er den nærmeste parallellen. Markedet panikk-solgte Nvidia. Noen måneder senere hadde aksjen hentet seg inn og satt nye rekorder. Fordi billigere AI-teknologi driver mer AI-bruk, ikke mindre.
Jevons hadde rett i 1865. Han har rett i 2026 også. Teknologi som gjør en ressurs billigere å bruke, genererer mer bruk av ressursen. Det er ikke et paradoks – det er mønsteret.
Markedet overreagerte. Det er ikke første gang. Og neste gang et software-gjennombrudd treffer chip-aksjene, er det verdt å huske at teknisk forståelse av hva algoritmen faktisk gjør er mer nyttig enn refleksiv salgsbeslutning basert på én overskrift.
Les hele analysen: TurboQuant – Alt du trenger å vite om Googles AI-gjennombrudd.








3 kommentarer