

Innhold Vis
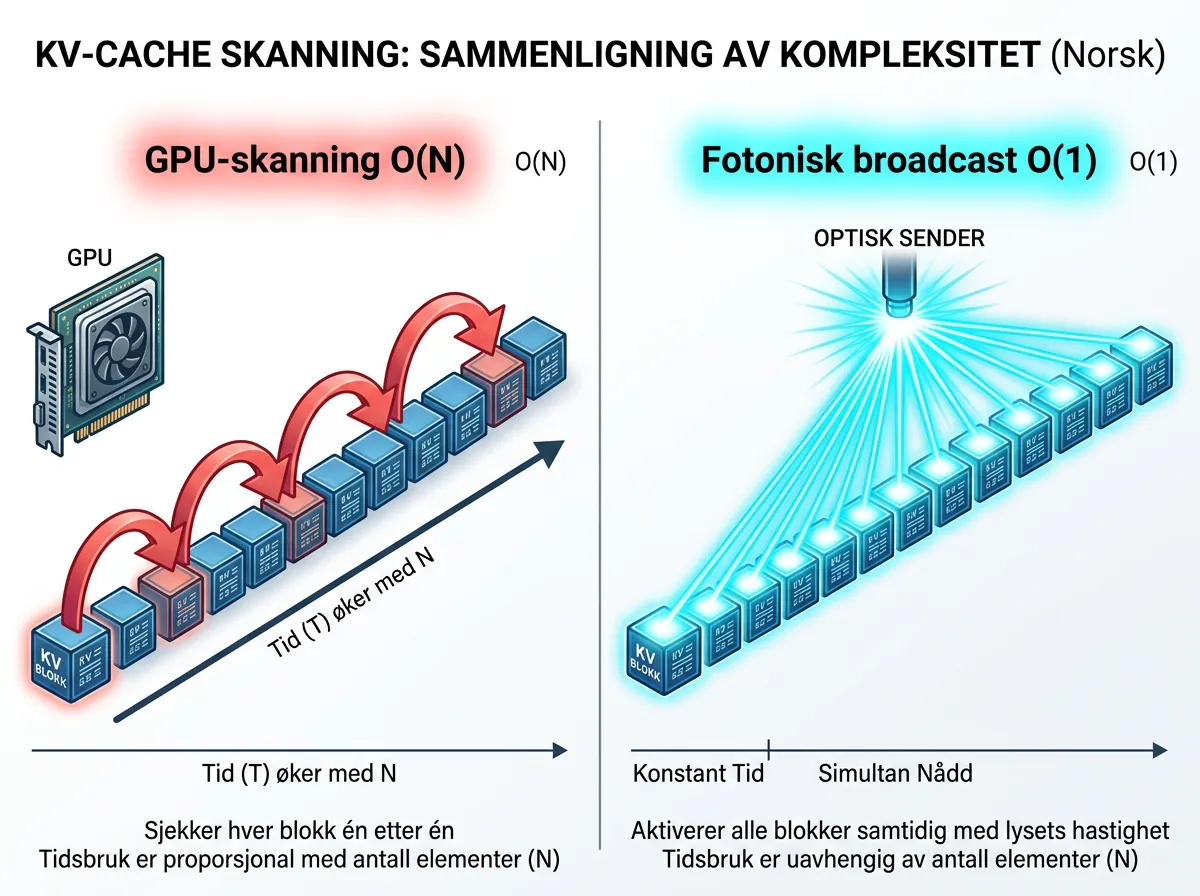
En nanofotonikk-doktorgradsstudent har designet en fotonisk chip kalt PRISM som erstatter det dyreste steget i lang-kontekst-inferens med lys. Tanken er enkel: i stedet for at GPUen din skanner gjennom millioner av KV-cache-blokker lineært for å finne de relevante – bruker PRISM optisk broadcast der lyset treffer alle blokker samtidig. Resultatet ifølge designeren: 944 ganger raskere enn GPU-skanningen, og 18 000 ganger lavere energiforbruk per spørring.
Dette er ikke et ferdig produkt. Det er ikke engang en prototype som kjøres i produksjon. Det er et konseptdesign fra en doktorgradsstudent – men ideen er interessant nok til å ta på alvor, fordi den treffer et problem som faktisk henger igjen i moderne LLM-inferens: jo lengre kontekst, jo tregere og dyrere blir hvert enkelt genereringstrinn.
La meg forklare hva problemet faktisk er, og hvorfor et fotonisk chip potensielt kan gjøre noe her som en GPU ikke kan.
Hva er KV-cache-problemet med lang kontekst?
Når en LLM genererer et nytt token, må den beregne hvor mye oppmerksomhet det nye tokenet skal gi til hvert tidligere token i konteksten. Det er dette attention-mekanismen gjør. For å spare tid lagres nøkkel- og verdi-vektorer fra alle tidligere token i en cache – KV-cachen. I stedet for å beregne dem på nytt, hentes de fra minnet.
Det høres greit ut – inntil kontekstvinduet ditt er på 1 million tokens. Da er KV-cachen enorm. Og her er problemet: metoder som Quest og RocketKV reduserer antallet blokker modellen faktisk henter, men de må fortsatt skanne gjennom alle N blokk-signaturer fra HBM (høybåndbredde-minne) for å finne ut hvilke blokker som er relevante. Det er en O(N) operasjon – lineær kompleksitet med kontekstlengden.
På en H100 med 1 million tokens i kontekst tar denne skanningen rundt 8,5 mikrosekunder per spørring. I batch-serving der du kjører mange samtidige forespørsler, akkumulerer dette seg raskt til å bli den dominerende kostnaden ved inferens. Du har en flaskehals som vokser proporsjonalt med kontekstlengden – og kontekstvinduene bare fortsetter å vokse.
Hva gjør PRISM annerledes?
PRISM-designet erstatter CPU/GPU-skanningen med optisk broadcast. Spørringen (query-vektoren) kodes om til lys. Det lyset sendes gjennom en passiv optisk splitter som kopierer signalet til alle N blokker på én gang. Hver blokk utfører en analog indreprodukt-beregning i det optiske domenet – det vil si at likheten mellom spørringen og blokk-signaturen beregnes fysisk av lysets interaksjon med chipens struktur, ikke av transistorer som gjør regnestykker ett av gangen.
Fordi lyset reiser gjennom alle blokker parallelt og indreproduktene beregnes analogt, er den effektive kompleksiteten O(1) – uavhengig av kontekstlengden. Det er det fundamentale skiftet.
Tallene designeren oppgir: 944 ganger raskere enn GPU-skanning på 1 million tokens kontekst, og 18 000 ganger lavere energiforbruk. Det siste er kanskje det mest slående – analog fotonikk bruker latterlig lite energi sammenlignet med digitale beregninger på en GPU.
Er dette troverdig, eller er det enda en fotonikk-hype?
Her må man være nøktern. Fotonikk-feltet har en lang tradisjon for lovende resultater i lab-setting som aldri materialiserer seg som produkter. Det er mange grunner til det.
For det første er analog fotonikk analog. Det betyr støy, drift over tid, og presisjonsproblemer. Digital elektronikk kan korrigere feil via redundans og korreksjonskoder – analog optikk er langt mer sårbar. For det andre er integrering mellom det fotoniske og det elektroniske alltid kostbart. Du trenger fortsatt digitale komponenter rundt chippet – A/D-konvertering, driver-elektronikk, kontrolllogikk.
For det tredje er dette et design laget av én person på doktorgradsnivå, ikke en ferdig fabrikasjonsplan med yield-tall og temperaturspesifikasjoner. Tallene på 944x og 18 000x er teoretiske estimater basert på komponentspesifikasjoner – ikke målte resultater fra et fysisk chip.
Det betyr ikke at ideen er dårlig. Det betyr at veien fra interessant PhD-konsept til produksjonsklar chip er lang og kostbar. Se for eksempel på Lightmatter, Luminous Computing, og andre fotonikk-startups som har brukt ti år og hundrevis av millioner dollar på å nærme seg det som er mulig i lab-miljø.
Hvorfor er den underliggende ideen likevel interessant?
Uavhengig av om akkurat denne implementasjonen noen gang blir til silisium, peker PRISM-designet mot et strukturelt problem i nåværende LLM-infrastruktur.
KV-cache-skanningen er et søkeproblem – og søkeproblemer er noe analog maskinvare historisk har hatt fordeler på. Noe av den tidlige forskningen på optisk computing handlet nettopp om assosiativt minne: strukturer som «gjenkjenner» mønstre uten å skanne lineært. Det PRISM gjør konseptuelt er å bringe den ideen inn i en svært spesifikk og veldefinert flaskehals i moderne transformerarkitektur.
Parallelt jobber andre aktører på lignende problemer med ulike metoder. FarmGPU, Lightbits og ScaleFlux demonstrerte nylig en samarbeidsarkitektur som gir 100-280 ganger raskere KV-cache for lang-kontekst-inferens via distribuert lagringshierarki – uten fotoniske komponenter. Nvidia har sitt eget system kalt Inference Context Memory Storage Platform med 5x inferensytelsesforbedring. Tilnærmingene er forskjellige, men retningen er den samme: alle ser at KV-cache-håndtering er neste store optimaliseringsfelt.

Hva betyr dette for lokal LLM-kjøring?
For de av oss som kjører modeller lokalt er dette foreløpig mest akademisk interessant. KV-cache-skanningsbotlenhalsen er primært et problem i batch-serving på store GPU-klynger – ikke på en enkelt RTX 4090 med én bruker. Men prinsippet er det samme.
Når kontekstvinduene vokser – og de gjør det, Claude har 200 000 tokens, mange modeller nærmer seg million-token-grensen – vil skalering av lokal inferens til lange kontekster kreve smartere løsninger enn å bare kaste mer GPU-minne på problemet. Metoder som RocketKV fra NVIDIA (ICML 2025) og Quest fra MIT adresserer allerede deler av dette i programvare – men det er grenser for hvor mye du kan kutte uten å gå etter fundamentale maskinvareegenskaper.
Jeg har skrevet om relaterte problemer tidligere – blant annet om Groqs LPU-arkitektur som er bygget fra grunnen av for effektiv inferens, og om Nvidias NemoClaw som prøver å optimalisere på programvaresiden. Felles for alle disse er at GPU-arkitekturen ikke er optimal for LLM-inferens – den er bare det vi har tilgjengelig i stor skala nå.
Hva skjer videre med fotoniske AI-akseleratorer?
Feltet er i bevegelse. Nature publiserte en studie tidlig i 2025 om integrerte fotoniske akseleratorer med ultralav latens. Optica rapporterte i 2026 om fotoniske chip som fremskynder sanntidslæring. IEEE-forskning fra 2025 viser 142,9 TOPS per joule for fotoniske systemer mot 0,63 TOPS per joule for tilsvarende elektroniske systemer – en faktor på rundt 230x i energieffektivitet for matrisemultiplikasjon.
Det er disse energitallene som gjør at folk ikke gir opp fotonikk til tross for mange skuffede løfter. Datasentre er energislukende maskiner, og LLM-inferens er en stor og voksende del av forbruket. Hvis fotoniske løsninger kan levere selv en brøkdel av de lovede energiforbedringene i produksjon, er det enorm kommersiell interesse å hente.
PRISM er et smart konsept som bruker fotonisk fysikk til å løse et konkret, identifisert flaskehalsproblem. Om det noen gang blir til et ekte chip er et annet spørsmål – men som demonstrasjon av hvorfor fotoniske løsninger er interessante for LLM-infrastruktur er det et godt eksempel på hva denne forskningsretningen faktisk sikter mot.








1 kommentar