

Innhold Vis
Gemma-4-31B-it-DFlash er en ny variant av Googles Gemma 4 31B-modell, utgitt av Z Lab på Hugging Face. Den skiller seg fra den offisielle modellen ved å bruke DFlash – en teknikk for spekulativ dekoding som ifølge tidlige målinger kan gi opptil 8x raskere inferens på tett-oppmerksomhetsmodeller som Gemma.
Bakgrunnen er interessant: Google slapp Gemma 4 i april 2026 med Apache 2.0-lisens, men holdt Multi-Token Prediction (MTP) låst bak sitt eget LiteRT-format. Det åpne miljøet, representert ved Z Lab og ggml-fellesskapet, svarte kjapt med å bygge sin egen løsning. DFlash er den løsningen.
Pr. nå er modellen tilgjengelig som safetensors på Hugging Face, men for å kjøre den lokalt via llama.cpp og Ollama må man vente på at PR #22105 i llama.cpp blir merget. Den er foreløpig i draft-status med 22 commits og venter på godkjenning fra maintainers.
Hva er DFlash og hvorfor er det spennende?
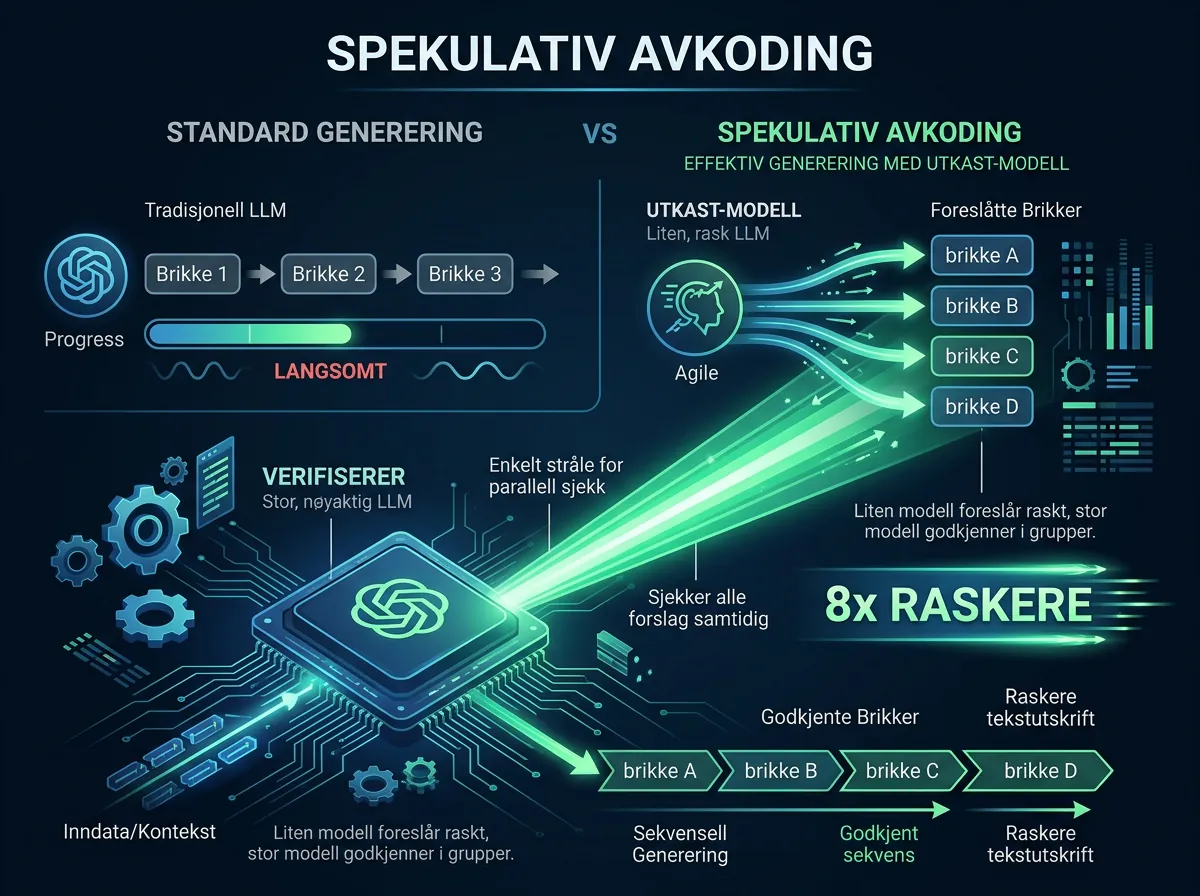
DFlash er en variant av spekulativ dekoding. I stedet for at modellen genererer ett token om gangen, genererer en «draft model» et helt blokk med kandidattokens i én forward pass – og en større «verifier model» godkjenner eller forkaster dem i bulk.
Resultatet er langt færre roundtrips gjennom de tunge matrisemultiplikasjonene som dominerer inferenstiden. På NVIDIA L40S har det blitt målt opptil 8x raskere generering sammenlignet med standard autoregressiv dekoding – men det gjelder primært tett oppmerksomhetsmodeller. MoE-modeller (Mixture of Experts) som DeepSeek gir ikke like dramatiske gevinster.
Gemma 4 31B er en tett modell, så forutsetningene for gevinst er gode. Det passer at akkurat denne modellarkitekturen er den første som får DFlash-behandlingen fra Z Lab.
Jeg har skrevet mer om teknologien bak i guiden min til spekulativ dekoding og MTP – anbefaler å lese den hvis begrepene er nye.
Hvordan skiller DFlash seg fra MTP?
MTP (Multi-Token Prediction) og DFlash løser det samme grunnproblemet – langsom token-for-token generering – men på litt forskjellige måter.
MTP er innebygd i selve modellarkitekturen under trening. Modellen læres opp til å forutsi flere tokens fremover, og inferensmotoren kan utnytte dette direkte. Det krever at modellen eksporteres med de riktige hodene intakt, noe Google unnlot å gjøre for de vanlige Gemma 4-formatene ifølge min tidligere artikkel om MTP som Google fjernet fra Gemma 4.
DFlash er en ekstern tilnærming. Den trenger ikke at modellen er trent med spesielle MTP-hoder. I stedet brukes en separat draft-modell som raskt foreslår kandidater, mens Gemma 4 31B fungerer som verifiserer. Arkitekturen er løsere koblet og kan i prinsippet kombineres med nesten hvilken som helst grunnmodell.
Det betyr at DFlash-tilnærmingen er mer fleksibel – og kanskje mer realistisk for folk som vil bruke Gemma 4 lokalt i dag, uten å vente på at Google eventuelt åpner MTP.
Hva er status for llama.cpp-støtten?
Her er den viktigste praksisen for deg som vil teste dette: du kan ikke bruke gemma-4-31B-it-DFlash med llama.cpp ennå.
PR #22105 som legger til DFlash-støtte i llama.cpp er under aktiv utvikling med 22 commits, men venter fortsatt på review og merge fra maintainers i ggml-org. Arbeidet bygger på EAGLE3-støtte fra en tidligere PR (#18039), og det er rapportert noen utfordringer knyttet til Gemma 4s bruk av ikke-kausal oppmerksomhet.
Frem til PRen er merget er alternativene begrenset. Du kan laste ned safetensors-filene fra z-lab/gemma-4-31B-it-DFlash på Hugging Face og kjøre dem med transformers-biblioteket, men da uten DFlash-akselerasjonen. For dem som bruker Ollama til lokal kjøring er situasjonen den samme – Ollama er avhengig av llama.cpp under panseret.
Verdt å følge med på: både llama.cpp og Ollama beveger seg raskt. Basert på aktivitetsnivået i PR-en ser dette ut til å komme i løpet av de neste dagene eller ukene.
Hvem er Z Lab og hva er bakgrunnen deres?
Z Lab er et forskningsmiljø som jobber med effektive inferensteknikker for åpne modeller. DFlash-arbeidet deres er publisert offentlig og koden er tilgjengelig, noe som er i god ånd med det åpne AI-fellesskapet som Gemma 4 selv tilhører.
Det er litt av et mønster i open source AI-fellesskapet: der en stor aktør som Google begrenser en funksjon (MTP i LiteRT), dukker det opp en tredjepartsløsning fra fellesskapet som omgår begrensningen på en annen måte. Vi så det med DeepSeek vs OpenAI, og nå ser vi det her med Z Lab og DFlash.
Den første Gemma 4-modellen med Apache 2.0 ble et startpunkt for mange eksperimenter. Jeg dekket lanseringen i artikkelen om Gemma 4 og Apache 2.0. Det er noe befriende med en lisens som faktisk tillater folk å bygge videre uten juridisk hodepine.

Hva betyr dette i praksis for deg som bruker lokale modeller?
Hvis du allerede kjører tunge lokale modeller og leter etter måter å presse mer ytelse ut av eksisterende hardware, er DFlash definitivt noe å følge med på.
En 8x hastighetsøkning er ikke en liten ting. Gemma 4 31B er en kompetent modell – 85,2% på MMLU Pro og et kontekstvindu på 256 000 tokens. Kombinert med DFlash-akselerasjon kan den bli langt mer praktisk på hardware som ikke er toppspesifisert.
For de fleste vil det praktiske steget være å vente til llama.cpp-PRen er merget, og deretter hente en GGUF-quantisert versjon via Ollama. Det er sannsynligvis en uke eller to unna, kanskje kortere.
Om du er nysgjerrig på Gemma 4-familien generelt kan du se mer om de ulike variantene – inkludert 2B, 9B og MoE-utgavene – i guiden til Gemma 4. Og hvis spekulativ dekoding som konsept er nytt: les forklaringen av MTP og speculative decoding – det gir god kontekst for hva DFlash prøver å gjøre.
Gemma-4-31B-it-DFlash er ikke ferdig ennå, men det er riktig vei. Åpne modeller, åpne teknikker, og et fellesskap som ikke venter på at Google skal fikse det de holdt tilbake.







