
Innhold Vis
Qwen3.5 122B er fortsatt den sterkeste lokale språkmodellen du kan kjøre på en enkeltmaskin i 2026. Det bekrefter ferske benchmarks fra brukere av MacBook Pro M5 Max med 128GB unified memory, der Alibabas flaggskip-modell ble testet mot 16 andre modeller på tvers av 23 forskjellige prompts.
Modellen ble lansert av Alibabas Qwen-team 24. februar 2026 og tilhører den tredje generasjonen av Qwen-familien. MoE-arkitekturen (Mixture of Experts) er nøkkelen: 122 milliarder totale parametere, men bare 10 milliarder er aktive per token. Det betyr at du får responsivitet på linje med en 10B-modell, men med tankekraft på linje med 122B.
Jeg er skeptisk til kinesiske modeller generelt – og det er greit å ha med seg som bakgrunnskontekst når man leser disse tallene. Men resultatene snakker for seg selv, og å ignorere dem vil ikke gjøre dem mindre imponerende.
Hva er Qwen3.5 122B egentlig?
Qwen3.5 122B-A10B er en hybrid MoE-modell med 256 eksperter i det sparse laget. Arkitekturen kombinerer Gated Delta Networks med sparse Mixture-of-Experts over 48 lag. Det høres teknisk ut, men praktisk betyr det én ting: modellen er rask og presis på samme tid.
Kontekstvinduet på 262 000 tokens (utvidbart til 1 million via YaRN) er blant de største i klassen. Apache 2.0-lisens betyr at du kan bruke den kommersielt uten ekstra kostnader. Du laster ned, kjører, gjør hva du vil.
Benchmarks som GPQA Diamond (86,6 poeng) slår GPT-5-mini (82,8) med nesten 4 poeng. På HLE (Humanity’s Last Exam) scorer den 25,3 mot GPT-5-mini sine 19,4. Det er ikke små marginer.
Hva viser M5 Max-benchmarkene?
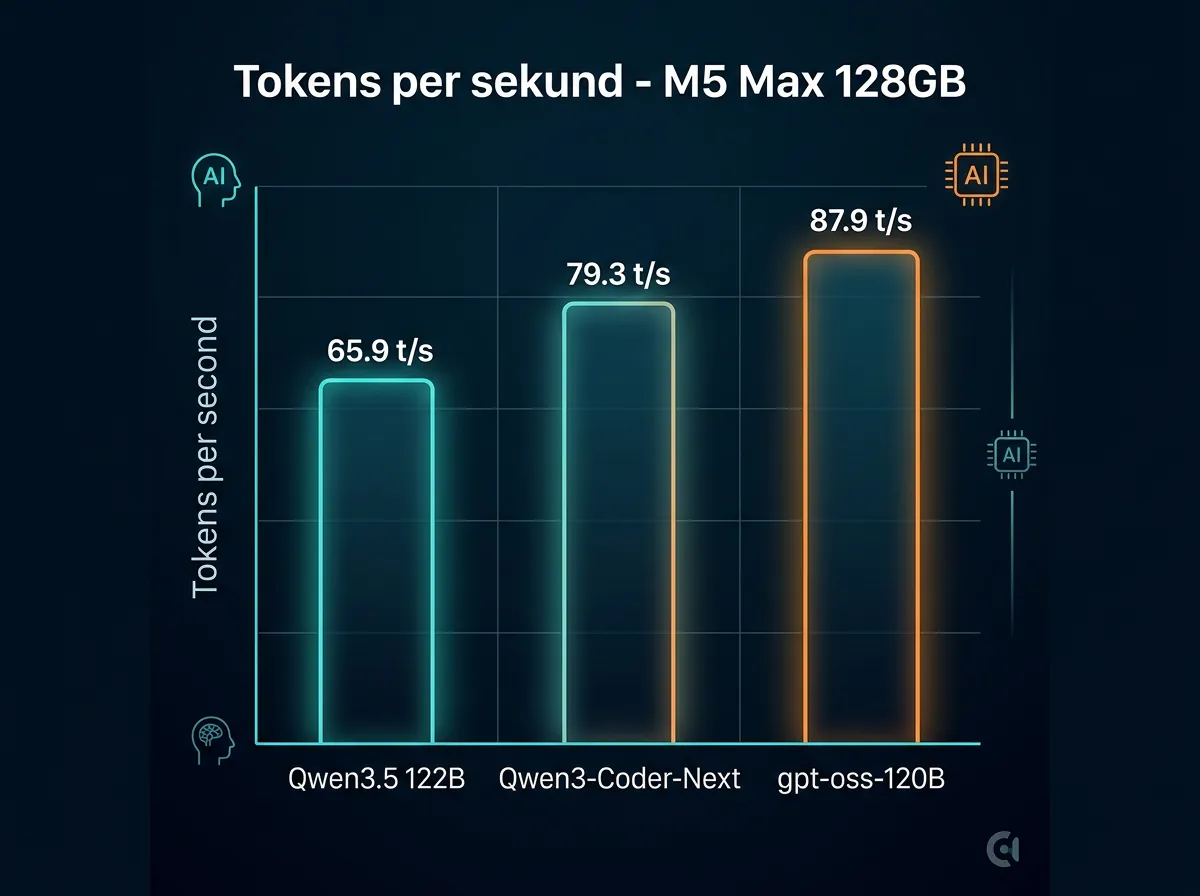
M5 Max med 128GB unified memory og 614 GB/s minnebåndbredde er på mange måter skreddersydd for store MoE-modeller lokalt. Ferske benchmarks fra hardware-corner.net viser disse tallene for Qwen3.5-122B-A10B ved Q4-kvantisering (69,6 GB modellstørrelse):
- 4K kontekst: 65,9 tokens per sekund
- 16K kontekst: 60,6 tokens per sekund
- 32K kontekst: 54,9 tokens per sekund
Til sammenligning: Qwen3-Coder-Next (8-bit, 84,7 GB) leverer 79,3 t/s ved 4K kontekst, og gpt-oss-120B (8-bit, 64 GB) gir 87,9 t/s. Qwen3.5 122B er altså ikke raskest i rå tokens per sekund – men benchmark-testen på tvers av 23 prompts viste at den fortsatt topper kvalitetsvurderingene.
55-65 tokens per sekund på en 122B-modell på en laptop. Det er bemerkelsesverdig. Ikke fordi det er et abstrakt tall, men fordi det betyr at en modell som tidligere krevde et lite datasenter nå kjører interaktivt på en maskin du kan putte i en bag.
Hvilken inferensramme er raskest på Apple Silicon?
MLX er det klare svaret. Ollama 0.19 lanserte nylig MLX-backend som forhåndsvisning og rapporterer om nesten dobbelt dekodehastighet på Apple Silicon sammenlignet med den tidligere llama.cpp-motoren. I praksis betyr dette 40-80% høyere gjennomstrøming enn Ollama alene.
For Qwen3.5 122B spesifikt viser sammenligninger at:
- MLX nativt: 65 tokens per sekund (Q4)
- Ollama med MLX-backend: nær tilsvarende, med enklere oppsett
- Ollama med llama.cpp: 12-18 tokens per sekund (MoE-modeller)
Forskjellen mellom llama.cpp og MLX for en MoE-modell er altså 3-5x. Det er ikke en liten justering – det er et fundamentalt annerledes kjøremiljø. Vil du ha Qwen3.5 122B lokalt, bør du bruke MLX.

Hva med Windows og Linux – trenger du Mac?
Nei. Men M5 Max med 128GB unified memory er en av de enkleste måtene å komme dit på i én pakke. For de som heller vil kjøre på NVIDIA, krever Qwen3.5 122B-A10B ca. 60-70 GB VRAM ved 4-bit kvantisering – det vil si to A100 80GB, eller én H100. En RTX 4090 med 24GB klarer det ikke alene.
Jeg har skrevet om lokal kjøring med RTX 4090 tidligere – den er fortsatt excellent for modeller opp til 70B, men 122B er utenfor rekkevidde uten kvantisering til et punkt der kvaliteten begynner å lide. M5 Max-tilnærmingen er rett og slett mer elegant for denne størrelsesbrikken.
Hva er Qwen3.5 122B best til?
Basert på benchmarks og praktiske tester peker tre bruksområder seg ut:
- Agentic oppgaver: BFCL-V4 funksjonskalling på 72,2 (vs GPT-5-mini sine 55,5) gjør den særlig sterk for verktøybruk og AI-agenter
- Skriving og kreative oppgaver: 122B MoE gir merkbart mer nyansert og stilmessig kontrollert output enn 70B-modeller
- Langvarige dokumentanalyser: 262K kontekstvindu gjør det mulig å sende inn hele rapporter, kodebaser eller bøker
Kodegenerering er der Qwen3-Coder-Next tar over – den er laget spesifikt for det. SWE-bench Verified på 72,4 for 122B er imidlertid sterkt for en generalistmodell. Jeg har skrevet om hvilke lokale modeller som egner seg til hva, og Qwen3.5 122B er per nå den beste generalistmodellen i sin klasse lokalt.
Er kinesiske modeller trygge å kjøre lokalt?
Kortversjonen: lokalt er risikoen fundamentalt annerledes enn i skyen. Når du kjører Qwen3.5 122B på din egen maskin via Ollama eller MLX, sendes ingenting til Alibabas servere. Modellvektene er åpne, kan inspiseres, og kjøres offline.
Det er et annet bilde enn å bruke Alibabas API (Qwen via OpenRouter eller Alibaba Cloud). Der gjelder vanlige forbehold om kinesisk datalovgivning. Men den lokale brukssaken – der du laster ned modellen og kjører den selv – er etter mitt syn teknisk uproblematisk.
Apache 2.0-lisensen bekrefter at Qwen-teamet deler modellvekter åpent. Du eier det du laster ned.
Hvordan kommer du i gang med Qwen3.5 122B lokalt?
Tre steg for å kjøre Qwen3.5 122B lokalt (krever 64GB+ unified memory eller tilsvarende VRAM):
- Mac med MLX: Unsloth-dokumentasjonen har komplett oppsett for Q4-kjøring via MLX
- Ollama:
ollama run qwen3.5:122b– enklest, men litt tregere uten MLX-backend - Linux/NVIDIA: To A100 80GB, vLLM eller llama.cpp med GGUF-format
Jeg har tidligere skrevet om andre Qwen-modeller fra Alibaba – de har konsekvent levert imponerende resultater for åpen-kilde-fellesskapet.
Benchmarken med 17 modeller og 23 prompts er en god påminnelse om at «best» alltid er relativt. Men for generalistoppgaver på 122B-nivå lokalt er Qwen3.5 122B fortsatt toppen av bunken i april 2026. Det er ikke en kinesisk seier over amerikanske modeller – det er åpen-kilde-fellesskapet som vinner.








2 kommentarer