

Innhold Vis
Google lanserte Gemma 4 med mye skryt om åpenhet og Apache 2.0-lisens – men stilte om en detalj som betyr ganske mye for ytelsen. Multi-Token Prediction (MTP), en teknikk som kan gi to til tre ganger raskere inferens, er fjernet fra de offentlige modellene. Den finnes bare i en variant de færreste bruker.
Dette kom frem da en Google-ansatt svarte på en diskusjon på Hugging Face. Begrunnelsen: MTP lot seg ikke integrere skikkelig med llama.cpp og transformers-biblioteket. Problemet med den forklaringen er at DeepSeek V3 og Qwen-variantene har MTP i sine offentlige modeller – og de fungerer fint i llama.cpp. Verktøyet ignorerer bare MTP-delen hvis det ikke støttes, og bruker modellen uten speed-boost. Verden går ikke under.
Så hva skjedde egentlig? Og betyr det noe i praksis? La oss ta en titt på tallene.
Hva er Multi-Token Prediction – og hvorfor er det verdt noe?
Kort forklart: MTP er en teknikk der modellen er trent til å forutse flere tokens fremover samtidig, ikke bare én av gangen. Den er en videreutvikling av noe som kalles speculative decoding – en idé Google selv var tidlig ute med. Jeg har skrevet en komplett gjennomgang av MTP og speculative decoding for deg som vil grave dypere i mekanismene.
Poenget i denne sammenhengen er at MTP ikke er en liten optimalisering. Under gode betingelser kan det gi to til tre ganger høyere tokens per sekund. For deg som kjører modeller lokalt er det forskjellen på en modell som føles treig og en som faktisk flyter.
DeepSeek V3 har MTP. Qwen 3.5-variantene har MTP. Begge to er kinesiske open source-modeller som ikke akkurat er kjent for å holde tilbake funksjonalitet fra brukerne. Googles Gemma 4, som er laget av ett av verdens største AI-laboratorier, har det ikke – i de versjonene folk faktisk laster ned.
Hvor er den fulle modellen?
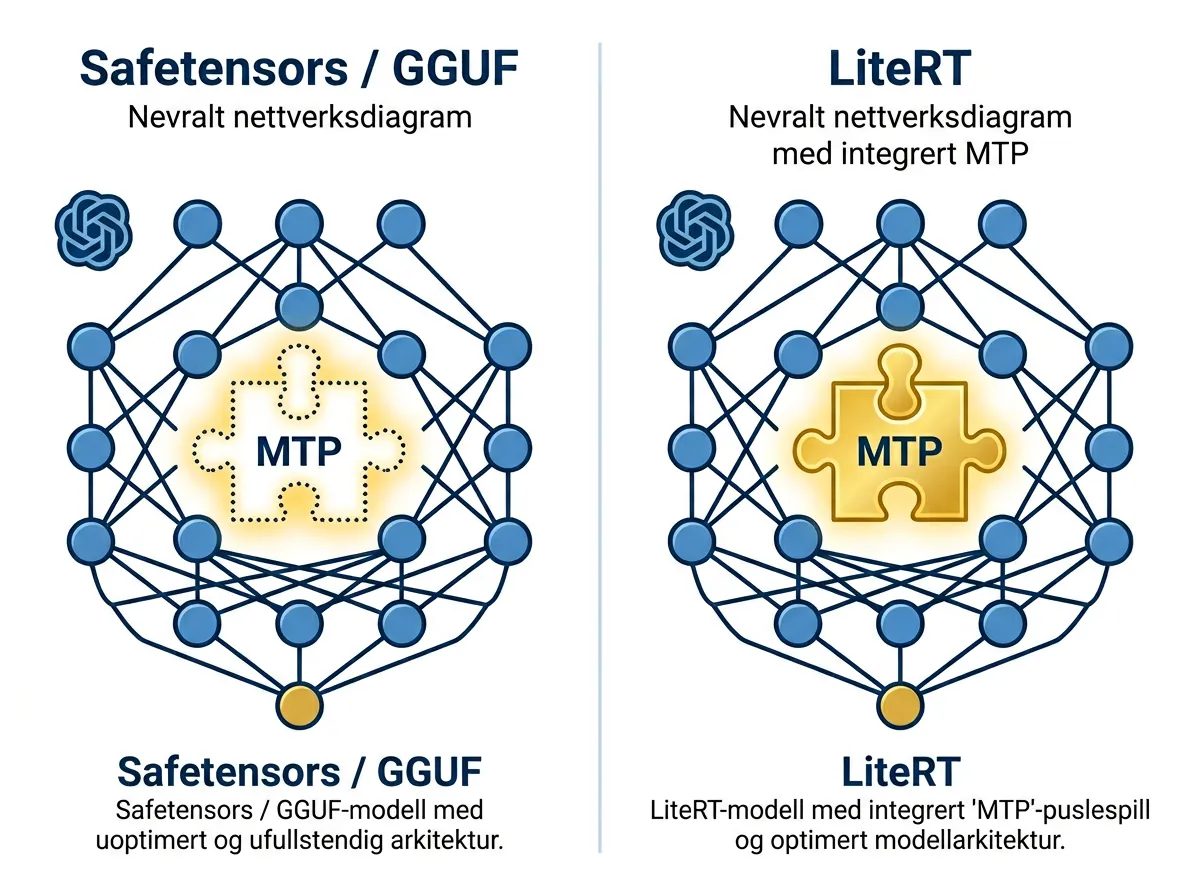
MTP finnes i Gemma 4 – bare ikke i safetensors- eller GGUF-versjonene. Den fulle versjonen er tilgjengelig via Googles LiteRT-format, et rammeverk beregnet på edge-enheter som telefoner og andre kompakte plattformer.
LiteRT er åpen kildekode. Det er ikke en svart boks. Men modellene som distribueres der er forhåndskompilert, og du kan ikke ta dem tilbake til vanlig safetensors-format etterpå. Vil du ha MTP, må du bruke LiteRT.
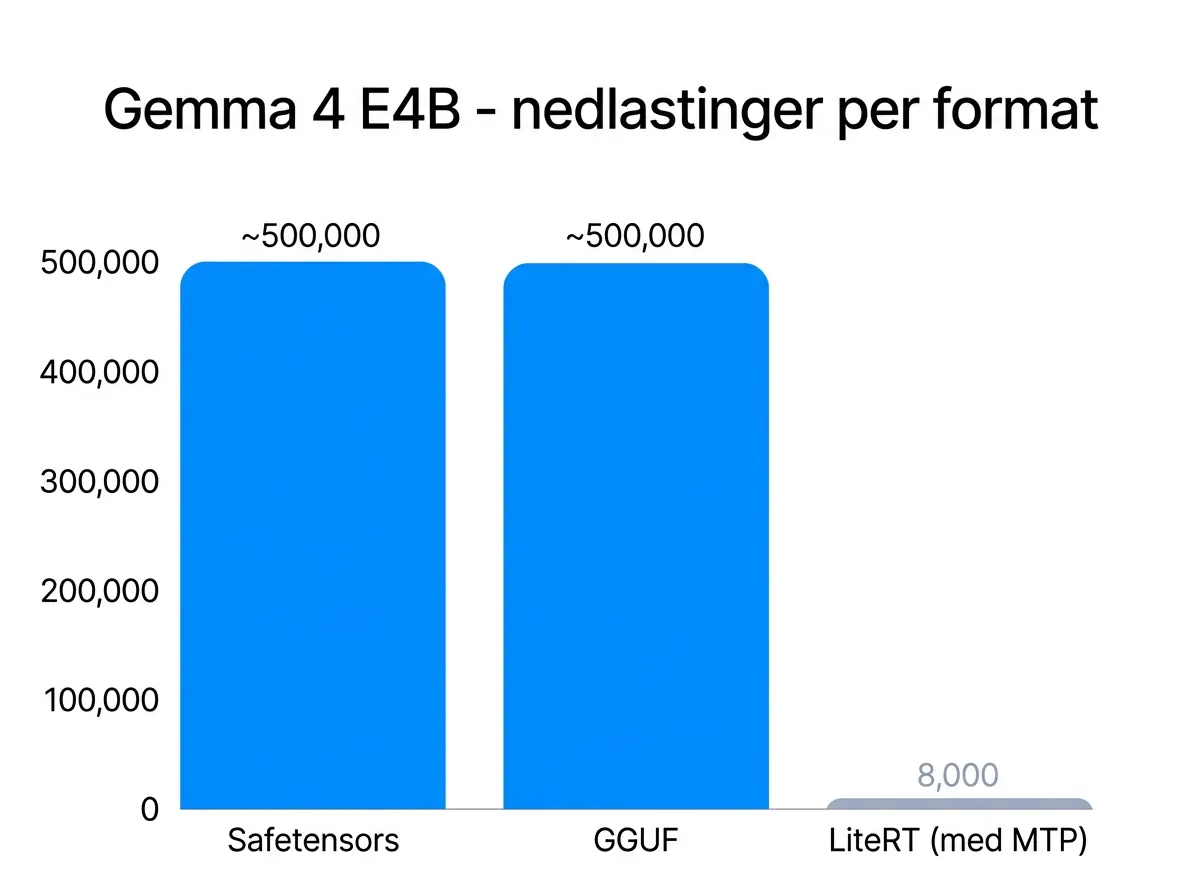
Problemet er at nesten ingen gjør det. Se på nedlastningstallene for Gemma 4 E4B – modellen i E4B-klassen:
- Safetensors-versjon: rundt 500 000 nedlastninger
- GGUF-versjon (for LM Studio, Ollama, llama.cpp): rundt 500 000 nedlastninger
- LiteRT-versjon med MTP: 8 000 nedlastninger
Over én million nedlastninger for de to vanlige formatene. Åtte tusen for den med full ytelse. Det er ikke akkurat et tegn på at LiteRT er det folk ønsker å bruke.
Hvorfor holder Google tilbake ytelse?
Det er ikke nødvendigvis en konspirasjon her. Det kan rett og slett ha vært et pragmatisk valg: MTP-støtte i llama.cpp er teknisk krevende, og integrering er fortsatt under utvikling for mange modeller selv i verktøy som normalt beveger seg raskt. VLLM, Python-rammeverket mange bruker for produksjonssetting, har edge cases der MTP ikke fungerer selv for populære modeller.
Men argumentet holder ikke helt. Konkurrentene – DeepSeek og Qwen – tok den avgjørelsen for deg og lot brukerne ha modellen med MTP uansett. llama.cpp ignorerer MTP hvis det ikke støttes – og du bruker modellen normalt, bare uten speed-boost. Ingen kræsjer. Ingen problemer. Det er nettopp slik open source er ment å fungere: du slipper det ut, community-et fikser det.
Det er litt ironisk at Google, som opprinnelig var med å utvikle ideen bak speculative decoding, og som allerede har gått videre til MTP i sin egen forskning, velger å holde det utenfor den offentlige modellversjonen. Det er som å komme tilbake til egne notater – og legge dem i en skuff.
Ingen nevnte det i lanseringsbloggene
Her er en detalj som sier litt: verken Googles offisielle Gemma 4-lansering eller Hugging Face-bloggposten som ble publisert i samarbeid med Google nevner MTP med ett ord. Ikke under «nyheter i Gemma 4», ikke under tekniske spesifikasjoner, ingenting.
Det kan være fordi de visste at MTP ikke ville være i de offentlige versjonene, og derfor ikke ville markedsføre det som en feature. Eller de regnet det ikke som viktig nok. Uansett: brukere som leste lanseringsbloggene fikk ikke vite at modellen de lastet ned manglet noe.
Jeg har skrevet tidligere om hva Gemma 4 bringer til bordet – og det er faktisk ganske mye. Apache 2.0-lisens, multimodal støtte, bra ytelse for størrelsen. Modellen er ikke dårlig. Men å stille om MTP i lanseringen er ikke akkurat slik du vinner tillit.
Betyr dette at Gemma 4 er ubrukelig?
Nei. Gemma 4 er en brukbar modell selv uten MTP – akkurat som DeepSeek V3 og Qwen er brukbare uten at llama.cpp faktisk utnytter MTP-en deres. Du får en god modell. Du får bare ikke den raskeste versjonen av den.
Problemet er mer prinsipielt enn praktisk. MTP er ikke en triviell forbedring – det er en arkitekturell kapabilitet som er trent inn i modellen under mange GPU-timer. Den finnes der. Den er bare gjort utilgjengelig for de aller fleste brukerne ved å låse den til et format nesten ingen bruker.
For de som kjører modeller lokalt med Ollama eller llama.cpp, betyr det at du uansett ikke får speed-boost. LiteRT er ikke integrert i disse verktøyene. Så selv om du ville bruke den «fulle» Gemma 4, er veien dit ganske smal akkurat nå.
Hva nå?
Forhåpentligvis ser vi MTP i de offentlige Gemma 4-modellene etterhvert – enten fordi Google legger det inn, eller fordi noen i community-et finner en vei rundt det. Open source-prosjektet rundt llama.cpp har allerede pull requests for MTP-støtte for flere modellarkitekturer. Det er ikke enkelt, men folk jobber med det.
Inntil da er det verdt å vite at Gemma 4-modellen du laster ned fra Hugging Face ikke er den komplette versjonen. Ikke fordi noen er onde. Men fordi Google tok en avgjørelse de konkurrentene ikke tok – og la den best ytende varianten i et hjørne der nedlastningstallene sier at ingen finner den.
Er dette bare Gemma 4, eller et mønster?
Det er et spørsmål verdt å stille. Google har mange modeller – og mange interesser. Gemma-serien er åpen, men Google tjener penger på at folk bruker Gemini API og Google Cloud. En Gemma-modell som yter ekstremt godt lokalt er ikke nødvendigvis i Googles kommersielle interesse.
Jeg spekulerer selvsagt. Men nedlastningstallene forteller sin egen historie: over én million nedlastninger av de «vanlige» versjonene, åtte tusen av den fulle. Markedet har stemt. Folk bruker ikke LiteRT. Og dermed forblir MTP en kapabilitet de færreste får glede av – til tross for at Google har den, og til tross for at konkurrentene deler den fritt.
Open source betyr ikke alltid at du får alt. Noen ganger betyr det at du får det meste – og at resten ligger i et format ingen bruker.








1 kommentar