
Innhold Vis
Poolside AI lanserte 28. april 2026 sine to første offentlige modeller: Laguna M.1 og Laguna XS.2. Begge er bygget spesielt for agentic coding – altså AI som koder autonomt over lange sesjoner med mange verktøykall. XS.2 er open-weight med Apache 2.0-lisens og kjører lokalt på én GPU. M.1 er den tyngre varianten, beregnet på krevende kodeoppdrag. Begge er gratis å bruke via API og OpenRouter i en begrenset periode.
Poolside er et AI-laboratorium med rundt 60 ansatte som har brukt de siste to årene på å bygge alt selv – treningsdata, reinforcement learning-systemer og inferensinfrastruktur. Nå er første modell ute av ovnen. Det er første gangen de slipper noe til offentligheten, og de gjør det med to modeller på én gang.
Hva gjør disse modellene interessante? Ganske enkelt: de er skreddersydd for akkurat det som er vanskelig med AI-koding i dag – lange, komplekse oppgaver der modellen må holde tungen rett i munnen gjennom hundrevis av verktøykall. Det er ikke lett å bygge, og de fleste generalistmodeller sliter der. Poolside har valgt å spesialisere seg heller enn å prøve å vinne alt.
Hva er Laguna M.1 og Laguna XS.2?
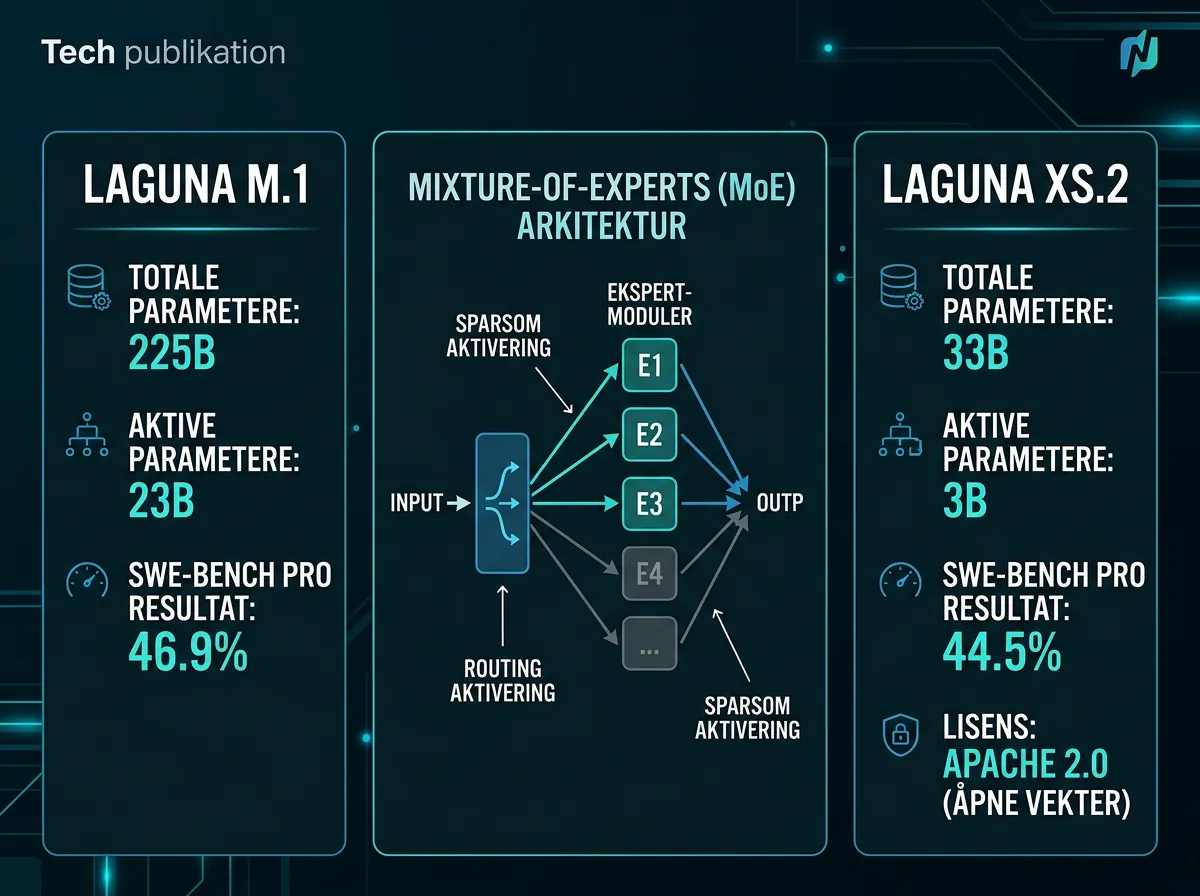
Begge modellene bruker Mixture-of-Experts (MoE) arkitektur, som betyr at bare en del av parameterne aktiveres per inferens. Det gir lavere beregningskost enn en tett modell av samme størrelse.
Laguna M.1 har 225 milliarder totale parametere, men bare 23 milliarder er aktive om gangen. Den ble trent på 30 billioner tokens ved hjelp av 6 144 NVIDIA Hopper GPU-er fra bunnen av. Benchmarkresultater: 46,9% på SWE-bench Pro og 40,7% på Terminal-Bench 2.0. Det er sterke tall for en spesialisert kodingsmodell, og sammenlignbare med de beste generalistmodellene på disse målene.
Laguna XS.2 er mye mindre – 33 milliarder totale parametere, 3 milliarder aktive. Den ble trent på 30 billioner tokens på fem uker, og er nå tilgjengelig som åpne vekter på Hugging Face under Apache 2.0-lisens. Det betyr at du kan laste ned, kjøre, fine-tune og bruke den kommersielt – uten å be om lov. XS.2 scorer 44,5% på SWE-bench Pro og 30,1% på Terminal-Bench 2.0. For en modell av denne størrelsen er det ganske imponerende.
Hvordan kjører du Laguna XS.2 lokalt?
Laguna XS.2 kan kjøres lokalt via Ollama, noe som gjør den tilgjengelig for alle med en anstendig GPU. For en 3B aktiv-parametermodell er kravene overkommelige – langt lavere enn de fleste 70B-modeller som folk kjører i dag.
Du kan også bruke den gratis via OpenRouter API akkurat nå. Poolside har partnerskaper med Hugging Face, OpenRouter, Baseten og Ollama for distribusjon. De har i tillegg lansert sitt eget agentverktøy kalt pool og et nettleserbasert utviklingsmiljø kalt Shimmer. Pool er et agent-harness som er designet rundt modellenes styrker – lange, autonome kodingssessjoner.
For de som vil bruke M.1 og trenger høyere rate limits, kan man kontakte models@poolside.ai direkte. Gratisfasen er ikke evig, men det er en god mulighet til å teste.
Vil du lese mer om open source AI-modeller generelt og hva du kan kjøre lokalt i dag? Sjekk Open source AI – komplett guide (2026).
Hva er Mixture-of-Experts og hvorfor spiller det en rolle?
MoE er ikke nytt, men Poolside har tatt det et steg videre med det de kaller «automixing» og egenutviklede syntetiske treningsdata. Laguna XS.2 har omtrent 13% syntetiske data i treningssettingen – det er en måte å fylle hull i treningsdataene og lære modellen spesifikke atferdsmønstre som ikke finnes naturlig i eksisterende kode-databaser.
De bruker også en optimisator kalt Muon i sin distribuerte implementering. De hevder den oppnår samme treningsloss som standard AdamW på 15% færre steg. Det er en meningsfull effektivitetsgevinst i skala – lavere regningstid, og dermed lavere treningskostnader.
For reinforcement learning etter pre-training bruker de en asynkron on-policy tilnærming bygget på CISPO-algoritmen. Tanken er at modellen skal lære å kode agentic – altså klare lange oppgaver med mange verktøykall uten å miste tråden. Det er akkurat det som er vanskelig med generalistmodeller på kodingsbenchmarks.

Hvem er Poolside AI?
Poolside ble grunnlagt med det eksplisitte målet om å bygge agentic coding-modeller ved å eie hele stacken – treningsdata, treningsprosessen, reinforcement learning og inferens. De har rundt 60 ansatte i Applied Research-organisasjonen. Selskapet er amerikanskeid og henvender seg tydelig til enterprises som vil ha kodeagenter de kan stole på.
Det er viktig kontekst: dette er ikke et selskap som har tatt en generalistmodell og fine-tunet den på kode. De har trent fra bunnen, med alt fokus på én nisje. Det ligner mer på det Mistral gjorde med hastebyggingen av småmodeller – sterk spesialisering fremfor bredde.
Jason Warner, CEO i Poolside, skriver på X at de «tror at for å bygge virkelig kapable kodingsagenter må man eie hele stacken». Det er en klar filosofi som skiller dem fra de fleste konkurrentene, der man setter en eksisterende grunnmodell inn i en agentic pipeline.
For den som vil lese mer om AMD og lokal agentic AI som alternativ, er GAIA – AMDs open-source rammeverk for lokale AI-agenter relevant lesning.
Hvordan sammenligner Laguna seg med andre kodingsmodeller?
SWE-bench Pro er den hardeste og mest manipulasjonssikre kode-benchmarken akkurat nå – den bruker nyere GitHub-PR-er som modellene ikke kan ha sett under trening. 46,9% for M.1 og 44,5% for XS.2 er begge sterke tall.
Til sammenligning ligger de beste generalistmodellene som Claude Sonnet og Qwen i tilsvarende range på SWE-bench Pro. At Laguna XS.2 – en 33B MoE-modell – kommer nær M.1 på denne benchmarken er det mest overraskende med lanseringen. Normalt er det stort gap mellom en liten og stor modell. Her er gapet langt mindre enn forventet.
Det er selvsagt én benchmark, og benchmarks er ikke hele sannheten. Men SWE-bench Pro er laget for å ikke la seg juske med, og resultatene virker konsistente med den arkitektoniske tilnærmingen Poolside beskriver. Linux-kernelprosjektet har allerede satt klare regler for AI-assistert koding – modeller som Laguna er akkurat hva disse reglene forsøker å regulere bruken av.
Vil du ha en bredere oversikt over AI-kodingsverktøy og terminalbaserte AI-løsninger? Gemini CLI Extensions er en god referanse for å forstå hva som fins i dette landskapet.
Er dette verdt å teste nå?
Ja – spesielt XS.2. Apache 2.0-lisens betyr at du kan bruke den til hva du vil, inkludert kommersielle prosjekter. Gratis via OpenRouter akkurat nå. Kjørbar lokalt via Ollama. Det er lav terskel for å prøve.
M.1 er mer for de som driver med tyngre agentisk utvikling og vil ha en modell som er bygget spesifikt for lange, komplekse kodingsoppdrag. At den er gratis i en begrenset periode via API gjør det mulig å teste uten binding.
Er XS.2 bedre enn Claude Sonnet eller GPT-4o på koding? Ikke nødvendigvis over hele linja – generalistmodeller er fortsatt veldig sterke. Men for spesifikke agentic coding-oppgaver, særlig de som krever mange autonome steg, er Poolside sin spesialisering en ekte fordel.
Det er sjelden vi ser et nytt laboratorium slippe sine første modeller og umiddelbart nå toppen av coding-benchmarks. Poolside har brukt to år på å bygge fundamentet. Nå er det klart for å se om det holder i produksjon. Du finner alt på Poolside sin offisielle blogg.








1 kommentar