

Innhold Vis
DeepSeek lanserte 24. april 2026 en forhåndsvisning av V4 – sin nye flaggskipmodell som ifølge selskapet konkurrerer med de beste lukkede systemene fra OpenAI, Anthropic og Google. Et år etter at DeepSeek rystet hele bransjen med V3, er historien nesten identisk: kinesisk open source-modell hevder å matche det dyreste fra Silicon Valley.
Skal du sammenligne med Claude og lurer på hva det egentlig er? Guiden min til Claude AI tar deg gjennom det.
To varianter er sluppet: DeepSeek-V4-Pro med 1,6 billioner totale parametere og DeepSeek-V4-Flash med 284 milliarder. Begge støtter et kontekstvindu på én million tokens og er tilgjengelige som åpen kildekode på Hugging Face fra dag én.
Hva er egentlig nytt denne gangen – og holder påstandene vann? Jeg har gått gjennom benchmarkene.
Hva er DeepSeek V4?
DeepSeek V4 er en Mixture-of-Experts-modell – det betyr at ikke alle parametere aktiveres for hvert spørsmål. V4-Pro har 1,6 billioner totale parametere, men bare 49 milliarder aktiveres per token. V4-Flash bruker 284 milliarder totalt og 13 milliarder aktivt. Dette er arkitekturen som gjør kinesiske modeller uforholdsmessig effektive å kjøre.
Kontekstvinduet på én million tokens er den store nyheten for utviklere. Det betyr at du kan sende inn en hel kodebase som ett enkelt prompt. DeepSeek R1 hadde allerede imponert på resonnering – V4 er det neste steget, med fokus på agentic coding og langt innhold.
Arkitektonisk har DeepSeek introdusert noe de kaller Hybrid Attention Architecture, som kombinerer Compressed Sparse Attention og Heavily Compressed Attention for å håndtere lange kontekster mer effektivt. I praksis bruker V4-Pro bare 27 % av de beregningsmessige ressursene til V3.2 ved behandling av én million tokens. Det er en dramatisk forbedring.
Hva sier benchmarkene?
Her er tallene som faktisk betyr noe. På SWE-bench Verified – den mest respekterte benchmarken for reell koding – scorer DeepSeek V4-Pro 80,6 %. Claude Opus 4.6 ligger på 80,8 %. Den forskjellen er ikke statistisk signifikant.
På LiveCodeBench, som tester algoritmisk koding, scorer V4-Pro 93,5 % mot Claude Opus 4.6 sine 88,8 %. Det er en tydelig ledelse. På Terminal-Bench 2.0, som simulerer reelt terminalarbeid, scorer V4-Pro 67,9 % mot Claude Opus 4.6 sine 65,4 %.

Matematikk er et annet område der V4 imponerer. V4-Pro-Max oppnår 120/120 på Putnam-2025 og en Codeforces-rating på 3 206 – det plasserer modellen som nummer 23 blant menneskelige konkurrenter. Det er første gang en open source-modell matcher lukkede frontlinje-systemer på konkurranseprogrammering.
Der Claude Opus 4.6 holder ledelsen er i bredere resonnering og faktabaserte spørsmål. På HLE (Hard Logical Evaluation) scorer Claude 40,0 % mot V4-Pro sine 37,7 %, og på HMMT 2026 matematikk 96,2 % mot 95,2 %. Ikke dramatiske forskjeller, men tydelige nok.
Internt hos DeepSeek er tilbakemeldingen at V4-Pro overgår Claude Sonnet 4.5 i koding, med kvalitet som nærmer seg Claude Opus 4.6 i normal modus. Det er ikke verifiserbare tall utenfra, men det er konsistent med benchmarkene.
Hva koster DeepSeek V4 å bruke?
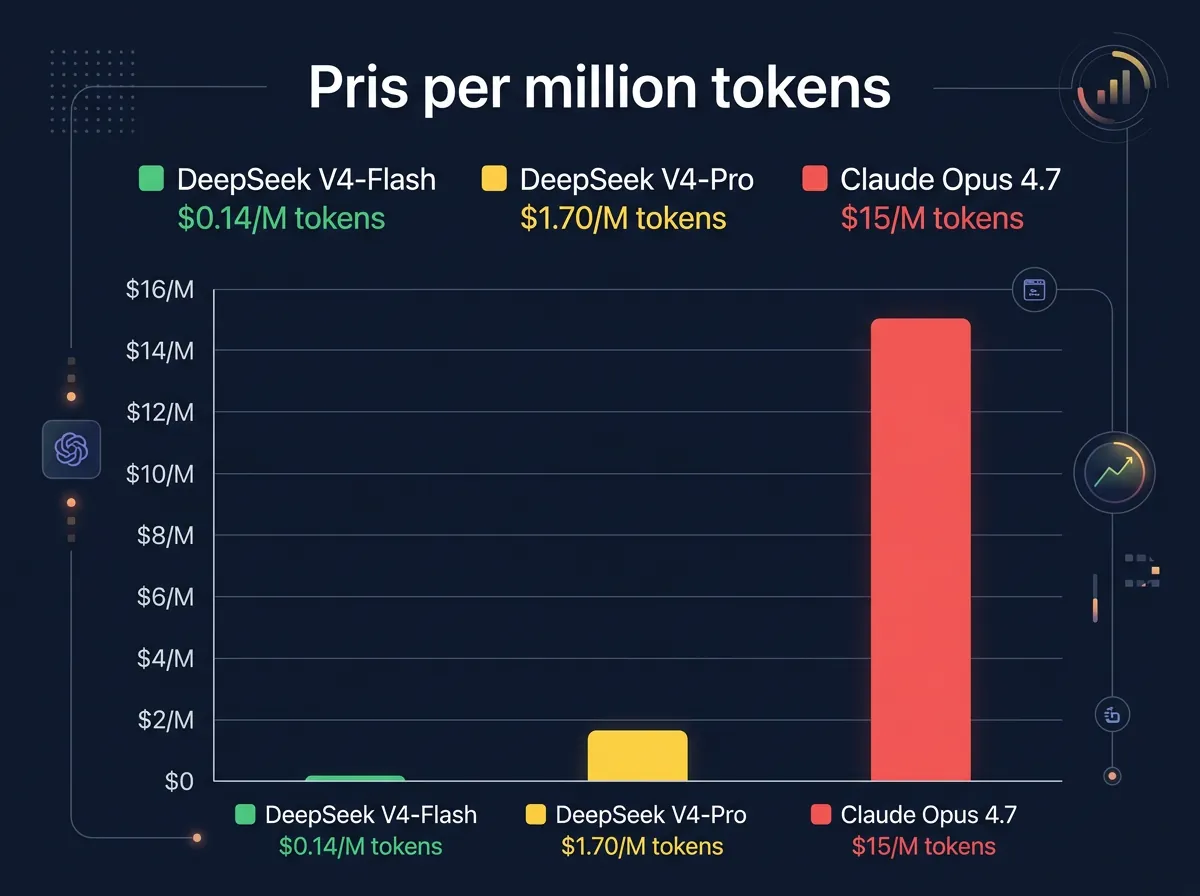
V4-Flash er priset til $0,14 per million input-tokens. V4-Pro koster $1,70 per million input-tokens. Til sammenligning er Claude Opus 4.7 priset til $15 per million input-tokens – nesten ni ganger dyrere enn V4-Pro for sammenlignbar ytelse på koding.
Det er dette som gjør de kinesiske modellene interessante uavhengig av hva man mener om opprinnelseslandet. $0,14 per million tokens for V4-Flash er nesten gratis. For de fleste automatiserings- og kodeoppgaver vil Flash levere tilstrekkelig kvalitet til en brøkdel av prisen for vestlige alternativer.
Begge modellene er tilgjengelige via DeepSeek API med støtte for både OpenAI ChatCompletions-format og Anthropic API-format. Det betyr at eksisterende kode for Claude eller GPT fungerer med minimal endring. De gamle deepseek-chat og deepseek-reasoner-endepunktene avsluttes 24. juli 2026, så hvis du kjører eldre integrasjoner bør du migrere nå.
Er V4 bedre enn V3?
Ja, og spesielt på det som teller i praksis. DeepSeek R1 var et gjennombrudd på resonnering. V4 tar det videre med fokus på agentic coding – altså modeller som ikke bare skriver kode, men utfører oppgaver over flere steg.
Effektivitetsforbedringene er imponerende. Ved én million tokens bruker V4-Pro bare 10 % av KV-cache-størrelsen til V3.2. Det er viktig for deg som vil kjøre modellen lokalt eller på begrenset maskinvare – men 1,6 billioner parametere totalt er uansett krevende. V4-Flash på 284 milliarder er mer realistisk for de fleste.
Open source-tilgangen er som vanlig: vektene er på Hugging Face, du kan laste ned og finjustere. Det er et bevisst valg fra DeepSeek som skiller dem fra OpenAI og Anthropic, der de fleste flaggskipmodeller er lukkede. Open source AI i 2026 er ikke lenger bare for hobbyister – det er en reell strategisk mulighet for alle som vil bygge på toppen av avanserte modeller uten å låse seg til én leverandør.
Hva betyr dette for AI-kappløpet?
Et år siden DeepSeek V3 dukket opp og sendte sjokkbølger gjennom Silicon Valley. Nvidia-aksjen falt, alle snakket om kinesisk AI. Og nå er historien omtrent den samme igjen.
Det interessante er ikke om V4 er «bedre» enn Claude eller GPT – det er at kvalitetsforskjellen mellom topp-modellene har krympet dramatisk, samtidig som prisgapet er enormt. DeepSeek V4-Flash på $0,14 per million tokens gjør avansert AI tilgjengelig for prosjekter der kostnaden ellers ville vært prohibitiv.
Jeg er personlig skeptisk til kinesiske modeller av åpenbare grunner, og for sensitiv data ville jeg ikke brukt DeepSeek API. Men for kodeoppgaver, automatisering og eksperimentering der dataen ikke er konfidensiell? Tallene er vanskelige å ignorere. Open source-konkurransen driver ned prisene og tvinger frem raskere innovasjon. Det er bra for alle som bruker AI.
Spørsmålet nå er om dette er en fullstendig lansering eller faktisk en forhåndsvisning – DeepSeek kaller det selv en preview. Fullstendig teknisk rapport og endelig prissetting er ventet i løpet av de neste ukene. Hva tenker du – er prisgapet stort nok til å veie opp for skepsisen mot kinesisk AI?








2 kommentarer