

Innhold Vis
OpenAI bruker WebRTC og en egenutviklet relay-arkitektur for å levere stemmesvar under 200 millisekunder til over 900 millioner ukentlige brukere. I en detaljert teknisk bloggpost beskriver selskapet hvordan de redesignet hele nettverkslaget for ChatGPT Voice og Realtime API – fra grunnen av.
Det er fascinerende lesning. Ikke fordi det er mystisk, men fordi løsningene de valgte er så elegante. De tok et eksisterende åpent webstandard (WebRTC), fant ut at standardoppsettet ikke skalerte for deres bruk, og bygget noe nytt oppå – uten å endre hva klienten ser.
Her er hva de faktisk gjorde, og hvorfor det betyr noe for alle som bruker eller bygger med AI-stemme.
Hvorfor er lav latens så viktig for stemme-AI?
Stemme er ikke som tekst. Når du sender en melding i ChatGPT og venter et sekund på svar, er det greit. Men i en samtale føles 300 millisekunder forsinkelse som en evig pause. Hjernen vår er dressert til å tolke pauser i samtale som signaler – uenighet, tankevirksomhet, noe galt.
OpenAI setter tre konkrete krav til systemet sitt. Globalt nedslagsfelt for over 900 millioner ukentlige aktive brukere. Rask tilkoblingsoppsett slik at brukeren kan begynne å snakke umiddelbart. Og lav og stabil tur-retur-tid (round-trip time) med lav jitter og pakketap, slik at samtalen oppleves naturlig.
Det siste punktet er det vanskeligste. Nettverksforsinkelse er fysikk – lysets hastighet, antall hopp, hoppenes kvalitet. Men arkitekturvalgene bestemmer om du kjemper mot fysikken eller jobber med den.
Hva er WebRTC, og hvorfor valgte OpenAI det?
WebRTC er en åpen standard for å sende lav-latens lyd, video og data mellom nettlesere, mobilapper og servere. Du kjenner det kanskje fra Google Meet eller Zoom, men det brukes like mye i klient-til-server-systemer.
Standarden håndterer de vanskelige bitene av sanntidsmedia automatisk: ICE for å etablere tilkobling gjennom NAT-er (de nettverksboksene mellom deg og internett), DTLS og SRTP for kryptert transport, kodeknappforhandling for lyd, og klientfunksjoner som ekkanselering og jitter-buffering.
For AI-produkter er den viktigste egenskapen at lyd ankommer som en kontinuerlig strøm. En stemmebassert AI kan begynne å transkribere, tenke, kalle verktøy og generere tale mens brukeren fortsatt snakker – i stedet for å vente på full opplasting. Det er forskjellen mellom en samtale og et push-to-talk-system.
Uten WebRTC måtte OpenAI løst hvert enkelt klientproblem selv: NAT-gjennomkjøring, kryptering, kodeknappforhandling, nettverkstilpasning. Med WebRTC bygger de på et protokollstakk som allerede er implementert i alle nettlesere og mobilplattformer.
Hva er problemet med vanlig WebRTC i Kubernetes?
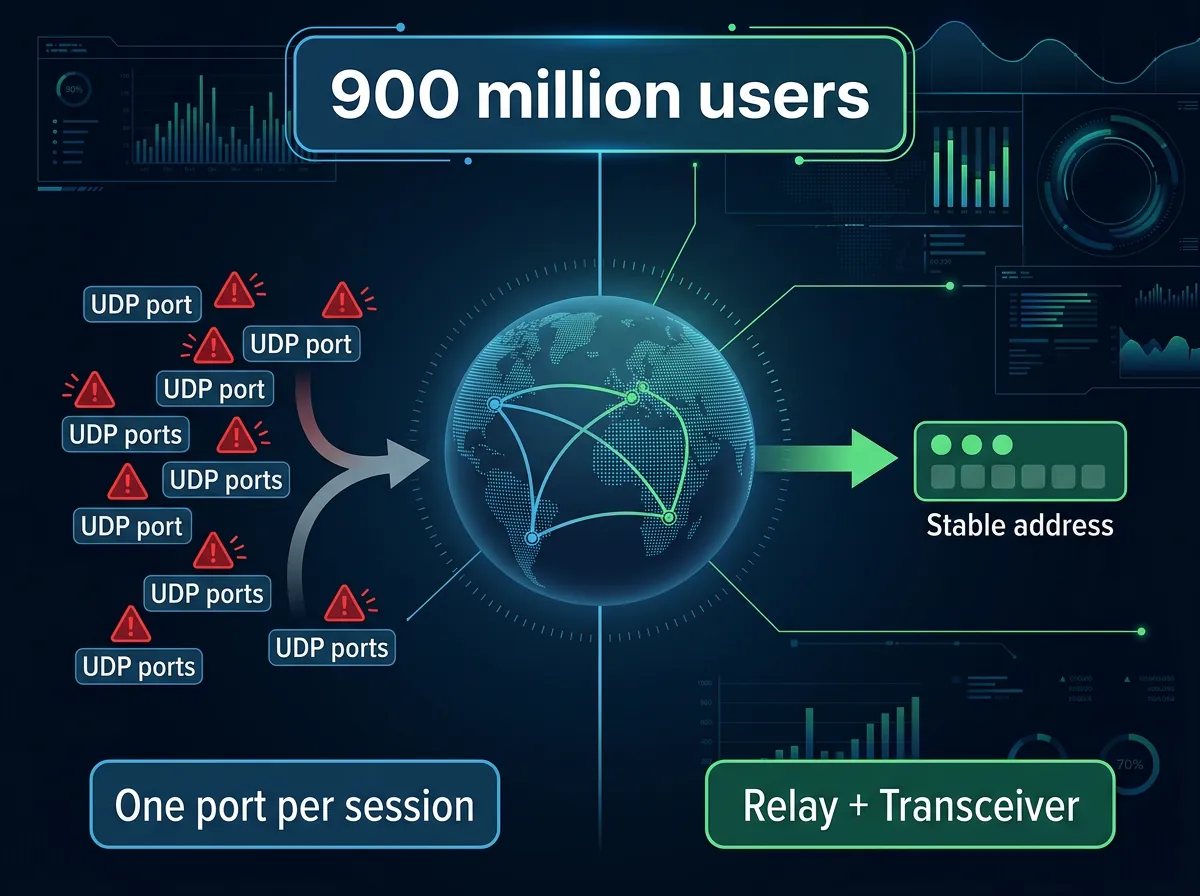
Standard WebRTC-oppsett bruker én UDP-port per sesjon. Det høres uskyldig ut, men ved høy trafikk betyr det å eksponere titusener av UDP-porter offentlig på internett.
Det passer dårlig med moderne skyinfrastruktur av tre grunner. Skytjenestenes lastbalansere og Kubernetes er ikke designet for titusener av UDP-porter per tjeneste. Store UDP-portområder er vanskelige å sikre fordi de utvider angrepsflaten. Og de er en dårlig match for autoskalering – Kubernetes legger til og fjerner pods kontinuerlig, og å kreve at hver pod reserverer og annonserer et stort stabilt portområde gjør den elastisiteten skjør.
Alternativet mange WebRTC-systemer bruker er én UDP-port per server med demultipleksering på applikasjonsnivå bak den porten. Det løser portproblematikken, men introduserer et nytt problem: å bevare eierskapet til hver sesjon på tvers av en serverflåte.
ICE og DTLS er stateful protokoller. Prosessen som opprettet en sesjon må fortsette å motta den sesjonens pakker for å validere tilkoblingskontroller, fullføre DTLS-håndtrykket og dekryptere SRTP. Hvis pakker for samme sesjon lander på en annen prosess, kan oppsett feile eller medier kan bryte.
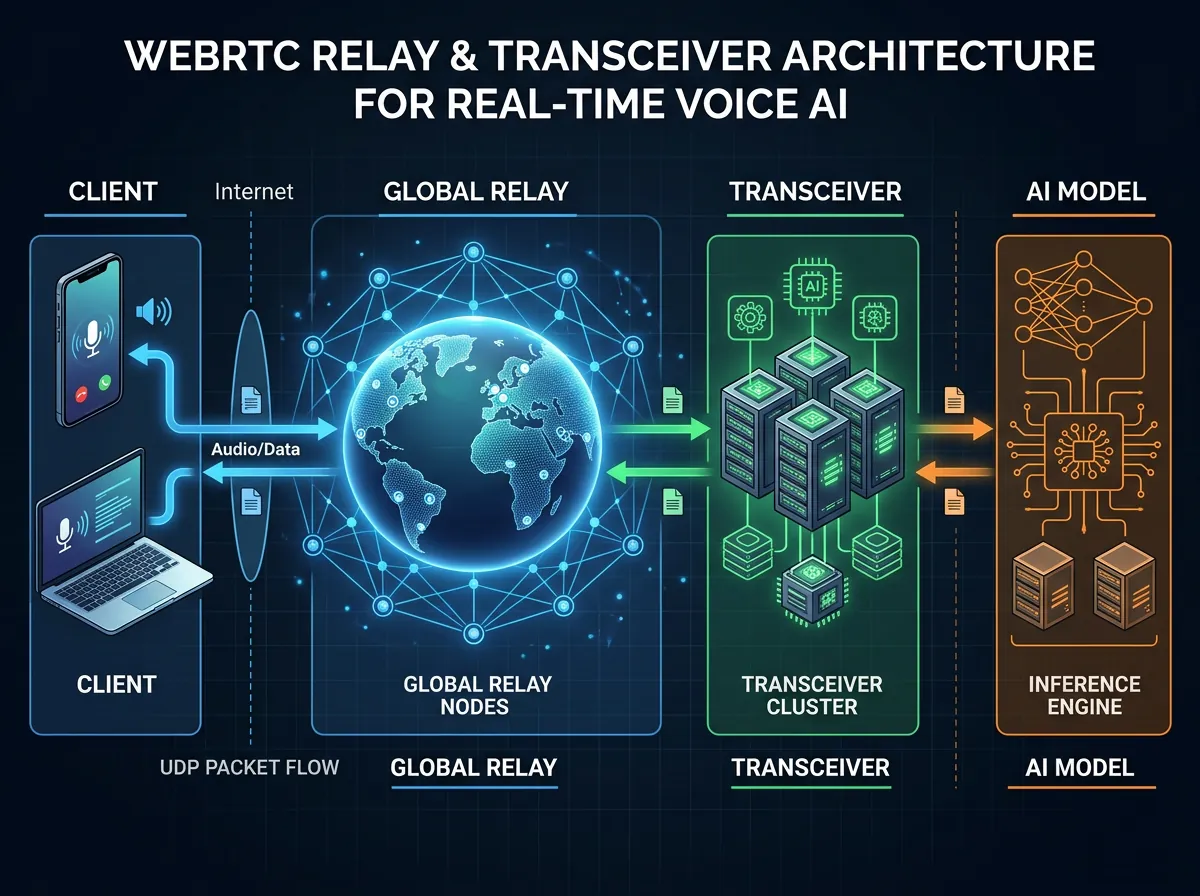
Relay pluss transceiver – OpenAIs løsning
OpenAI valgte det de kaller en «relay pluss transceiver»-arkitektur. Det er enklere enn det høres ut.
En transceiver er den eneste tjenesten som eier WebRTC-sesjonstilstand – ICE-tilkoblingskontroller, DTLS-håndtrykket, SRTP-krypteringsnøkler og sesjonslivssyklus. Klienten ser et fullstendig normalt WebRTC-oppsett. Ingenting endrer seg fra klientens perspektiv.
Releet er et lettvekts UDP-videresendingslag med et lite offentlig fotavtrykk. Det dekrypterer ikke medier, kjører ikke ICE-tilstandsmaskiner og deltar ikke i kodeknappforhandling. Det leser nok pakkemetadata til å velge destinasjon, videresender deretter pakken til transkieiveren som eier sesjonen.
Nøkkelen er første-pakke-ruting. Releet må rute den første pakken fra en klient før noen sesjon eksisterer på pakkebanen. OpenAIs løsning er elegant: de genererer server-siden av ICE username fragment (ufrag) slik at den inneholder nok rutingsmetadata til at releet kan finne riktig transceiver – ved å lese informasjon som allerede er i pakken etter standard WebRTC-protokoll.
Klienten sender pakkene til en enkelt stabil adresse. Releet videresender til riktig transceiver. Transkieiveren eier alt sesjonstilstand. Backend-tjenester skalerer som vanlige tjenester uten å oppføre seg som WebRTC-parter.
Hva er Global Relay, og hvorfor betyr det noe for deg?
Når UDP-overflaten ble redusert til et lite antall stabile adresser og porter, kunne OpenAI distribuere det samme relemønsteret globalt. Global Relay er en flåte av geografisk distribuerte relay-inngangspunkter som alle implementerer samme pakkevidersendingsatferd.
Bred geografisk inngang forkorter det første klient-til-OpenAI-hoppet. En pakke kan entre OpenAIs nettverk ved et rele nær brukeren – i geografi og nettverkstopologi – i stedet for å krysse det offentlige internett til en fjern region.
I praksis betyr det lavere latens, mindre jitter og færre tap. For deg som bruker ChatGPT Voice i Norge betyr det at din stemme ikke reiser til USA og tilbake før AI-en begynner å prosessere. Den ankommer et europeisk innganspunkt og tar OpenAIs interne nettverk videre.
OpenAI bruker Cloudflare geo og nærhetsstyring for signalering slik at den innledende HTTP- eller WebSocket-forespørselen når et nærliggende transceiver-kluster. SDP-svaret gir Global Relay-adressen, mens ufrag inneholder nok informasjon til å rute media til riktig kluster og transceiver.
Tekniske detaljer som fortjener oppmerksomhet
Releet er skrevet i Go og holdt bevisst smalt. På Linux mottar kjernens nettverksstakk UDP-pakker og leverer dem til en socket. Releet kjører i userspace – en vanlig Go-prosess leser pakkehoder fra socketen, oppdaterer en liten mengde flyttilstand og videresender pakker uten å terminere WebRTC.
Noen konkrete valg er verdt å nevne. SO_REUSEPORT er et Linux socket-alternativ som lar flere relyarbeidere på samme maskin binde samme UDP-port. Kjernen distribuerer da innkommende pakker på tvers av de arbeiderne, noe som unngår en enkelt lesing-loop-flaskehals. runtime.LockOSThread låser hver UDP-lese-goroutine til en spesifikk OS-tråd – kombinert med SO_REUSEPORT holder det pakker fra samme flyt på samme CPU-kjerne, noe som forbedrer cache-lokalitet og reduserer kontekstbytte.
OpenAI vurderte kernel bypass (å la en userspace-prosess polle nettverkskøer direkte for høyere pakkerate), men trengte det ikke. En smal Go-implementasjon med nøye bruk av SO_REUSEPORT, trådlåsing og lav-allokering-parsing var nok for arbeidsmengden.
For sesjonsrestitusjon bruker de Redis til å lagre mappingen av klient-IP og port til transceiver-IP og port etter at ruten er etablert. Hvis et rele starter på nytt og mister sesjonen, er Redis-cachen der for rask gjenoppretting – uten å vente på neste STUN-pakke.
Hva betyr dette for utviklere som bruker Realtime API?
OpenAIs Realtime API er grunnlaget for alle som bygger stemmeagenter, interaktive talebots eller sanntidstranskripsjonsverktøy. Arkitekturen beskrevet her er infrastrukturen under den API-en.
For utviklere er det gode nyheter på flere måter. Klientsiden endrer seg ikke – standard WebRTC fungerer som det alltid har gjort. Infrastrukturen skalerer uten at du trenger å gjøre noe annerledes. Og geografisk routing skjer automatisk, noe som betyr lavere latens for sluttbrukere uavhengig av deres plassering.
De som har prøvd stemme-AI i verktøy som Claude Code merker forskjellen mellom infrastrukturer som er bygget for lav latens og de som ikke er det. Svartiden er ikke bare et spørsmål om modellhastighet – nettverkslaget bestemmer like mye av opplevelsen.
Det er også verdt å nevne at to ingeniørene bak mye av WebRTC-grunnlaget – Justin Uberti (en av WebRTCs opprinnelige arkitekter) og Sean DuBois (skaperen av Pion, Go-biblioteket OpenAI bruker) – nå jobber direkte for OpenAI. Det forklarer delvis hvorfor de tekniske valgene her er så solide.
Er dette relevant for andre AI-selskaper?
Ja, det er det. Problemene OpenAI løste er ikke unike for dem. Alle som kjører sanntids-AI-interaksjoner ved skala møter de samme utfordringene med UDP-portadministrasjon, sesjonstilstand og geografisk ruting.
Det interessante er at løsningen de valgte – relay pluss transceiver med standard WebRTC for klienten – er en tilnærming andre kan kopiere. De har ikke patentert noe eksotisk. De har tatt velprøvde mønstre (thin forwarding layer, ufrag-basert ruting, SO_REUSEPORT) og kombinert dem smart.
For de som jobber med norsk tale-AI, som NB-Whisper fra Nasjonalbiblioteket, er dette relevant kunnskap om hva som trengs for å skalere fra laboratorium til produksjon. Modellen er bare halve jobben – infrastrukturen under er like viktig.
OpenAIs publisering av denne tekniske detaljgraden er uvanlig åpen for et selskap som normalt holder kortene tett. Det er nyttig for fellesskapet, og det viser at WebRTC som grunnlag for AI-stemme er mer enn et pragmatisk valg – det er et bevisst designpremiss som holder selv ved ekstrem skala.







