

Innhold Vis
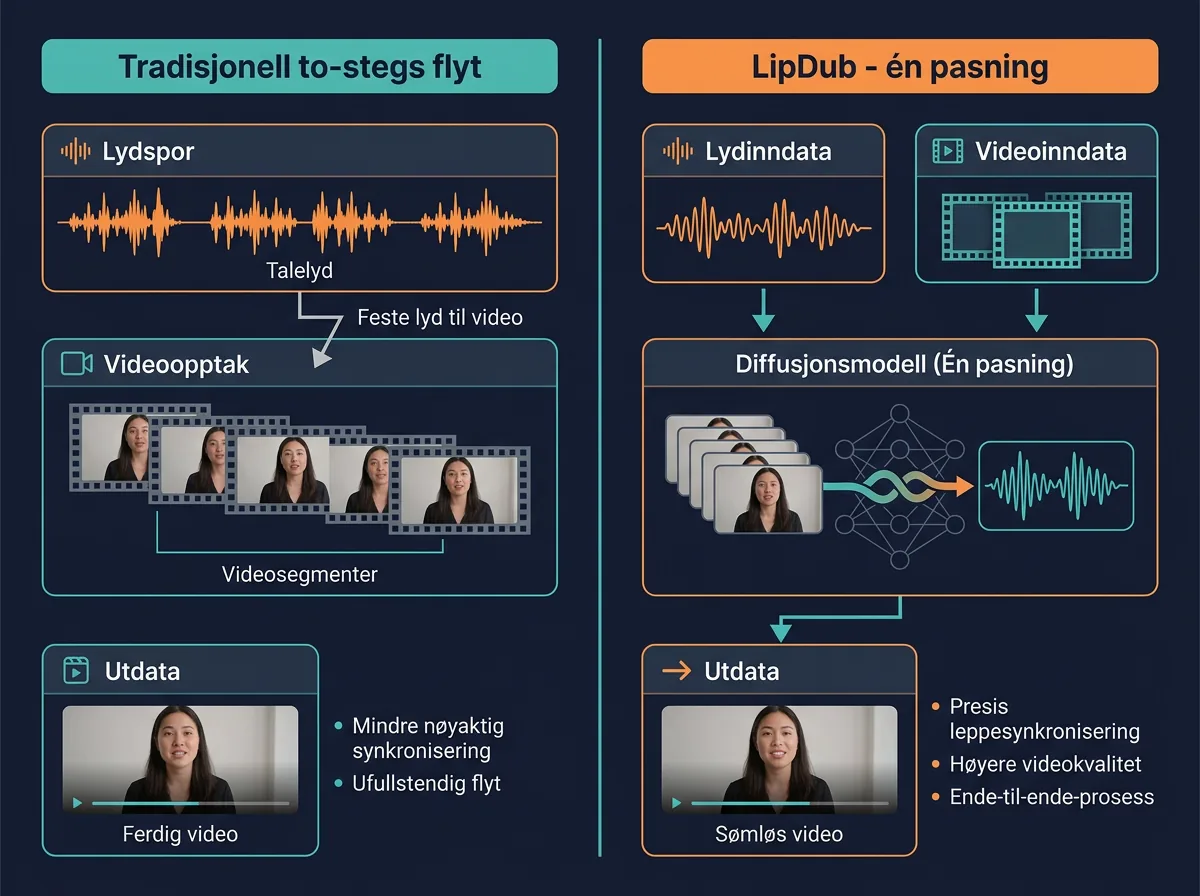
LipDub er et nytt open source-verktøy for lipsync fra Lightricks, bygget direkte på LTX-2.3. I stedet for den vanlige to-stegs-flyten – generer lyd, fest den på etterpå – gjør LipDub begge deler i én enkelt pasning. Du gir det en kildevideo og en ny tekstprompt, og modellen regenererer dialog og leppebevegelser samtidig. Alt annet – ansiktsutseende, stemmekvalitet, tone og mimikk – bevares.
Prosjektet er et resultat av samarbeid mellom forskere fra Tel Aviv University og Lightricks, presentert på SIGGRAPH 2026. Koden og modellvektene er publisert som open source under ltx-2-community-license på Hugging Face. Beta-versjonen støtter 1080p Full HD, klipp opptil 8 sekunder og én taler om gangen.
For alle som har eksperimentert med LTX Video 2.3 er dette en direkte utvidelse av det samme rammeverket – nå med ekte lipsync i steden for den separate LatentSync-flyten mange har brukt til nå.
Hva er IC-LoRA, og hvorfor er det smartere enn vanlig lipsync?
IC-LoRA står for Instruction-guided Control LoRA – en lav-rang adapter som legger kontrollerbare instruksjoner oppå en base-modell uten å trene hele modellen på nytt. Det er langt mer effektivt enn full fine-tuning, og det er nettopp derfor LipDub kan distribueres som en kompakt safetensors-fil som lastes inn i LTX-2.3.
Den tekniske tilnærmingen er det interessante her. Tradisjonelle lipsync-verktøy som Wav2Lip og LatentSync tar ett ferdig video-klipp og forsøker å «lime på» ny munndynamikk i etterkant. Det ser sjelden naturlig ut fordi de to lagene – det originale bildet og den nye munnen – ble generert uavhengig av hverandre.
LipDub tar en annen vei: den bruker den innebygde audio-visuelle forståelsen i LTX-2.3 til å regenerere leppe-regionen i én enkelt diffusjonspasning. Lyd og bevegelse genereres simultant, noe som gir mye bedre kohesjon mellom det nye lydspøret og ansiktsbevegelsene. Resultatet skal se ut som om personen faktisk sa den nye replikken – ikke som en etterligning klebet på toppen.
Paperet bak prosjektet – JUST-DUB-IT (arXiv:2601.22143) – beskriver en to-komponents pipeline: en syntetisk datapipeline med «language-switching og counterfactual inpainting», pluss in-context LoRA-trening som utnytter audio-visuelle priors fra base-modellen.
Hva kan du faktisk bruke LipDub til?
De mest åpenbare bruksområdene er dubbing av video til andre språk, korrigering av feil replikker i opptak, og generering av AI-karakterer som snakker ny dialog uten å filme på nytt. Prosjektdemoen viser dubbing til fransk, russisk, spansk og tysk med bevart stemmekvalitet og lipsync.
For innholdsskapere er muligheten til å korrigere en dårlig take uten ny filming interessant. Filmet en instruksjonsvideo og oppdaget en feil? Med LipDub kan du teknisk sett regenerere den setningen med korrekt informasjon, og beholde resten av klippet uendret.
Flerspråklig dubbing er det åpenbart store markedsmessige bruksområdet. I stedet for å leie inn dubbing-skuespillere og matche leppebevegelser manuelt – en prosess som kan koste titusener av kroner per episode – kan en enkelt modell gjøre det automatisk. Betabegrensningene (8 sekunder, én taler) betyr at LipDub ikke er klar for langfilmer enda, men for korte klipp, reklame og YouTube-snuttar er det langt mer håndterbart.
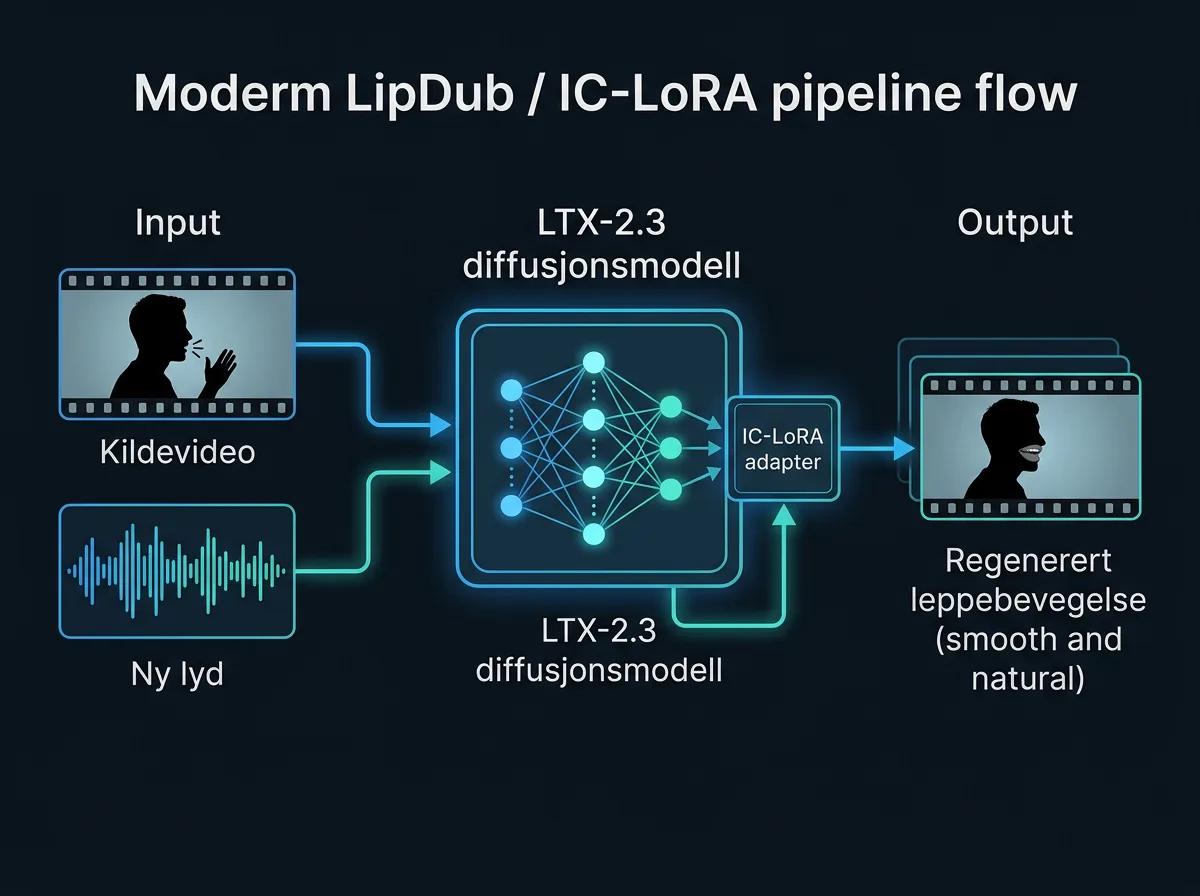
Hvordan installerer og bruker du LipDub?
LipDub er tilgjengelig via Lightricks’ LTX-2-repository på GitHub. Modellvektene lastes ned fra Hugging Face. Selve LipDub-pipelinen installeres som en Python-pakke:
pip install -e packages/ltx-pipelines
Du trenger deretter å laste ned IC-LoRA-vektene (ltx-2.3-22b-ic-lora-lipdub-0.9.safetensors) og plassere dem i modell-mappen. Kjøring skjer via kommandolinje:
python -m ltx_pipelines.lipdub --reference-video original.mp4 --audio-path ny_dialog.wav --lora path/to/lipdub_lora.safetensors
Et viktig teknisk poeng: pipelinen krever den distilled versjonen av LTX-2.3, ikke fullmodellen. Distilled-modellen er optimalisert for færre diffusjonssteg, noe som gir raskere inferens med lavere minnebruk. Oppløsningen på output-klippet hentes automatisk fra kildeklippet, og antall frames justeres til nærmeste 8k+1-format.
For de som foretrekker et visuelt grensesnitt finnes det også en ComfyUI-workflow i Lightricks’ offisielle ComfyUI-LTXVideo-repository. Det er litt enklere å komme i gang med for de som ikke er komfortable med kommandolinje-kjøring. Har du allerede satt opp AI-videogenerering lokalt, er mye av infrastrukturen allerede på plass.
Er LipDub bedre enn LatentSync og Wav2Lip?
Det er det interessante spørsmålet. De fleste som har jobbet med lipsync på LTX-video tidligere har brukt en to-stegs-flyt: generer videoen med LTX, kjør så LatentSync eller et lignende verktøy for å legge på lippesync i etterkant. Det fungerer, men resultatet er sjelden helt overbevisende fordi de to lagene ikke er integrert.
LipDubs enkelt-pasnings-tilnærming har et klart teoretisk fortrinn: når lyd og bilde genereres simultant i én diffusjonsmodell, vil synkroniseringen mellom dem være bedre. Det er samme prinsipp som gjør at LTX-2 – som genererer audio og video i én pasning – ofte høres mer naturlig ut enn verktøy som legger til lyd i etterkant.
I praksis er dette et beta-verktøy, og begrensningene er reelle. 8 sekunder er kort. En enkelt taler er begrensende. Og de GPU-kravene for 22B-parametermodellen er ikke trivielle. Men det er en solid teknisk start, og Lightricks har vist med LTX-serien at de forbedrer verktøyene sine raskt.
Hva sier SIGGRAPH-forskningen bak LipDub?
JUST-DUB-IT-paperet løser et spesifikt problem som har plaget dubbing-verktøy lenge: det er ekstremt vanskelig å trene en modell til å dubbe video fordi det ikke finnes nok trente sett med originale videoer og dubbede versjoner av dem.
Løsningen er elegant. Forskerne bygget en syntetisk datapipeline som genererer sine egne treningspar via «language-switching og counterfactual inpainting». Det betyr at modellen lærer av data den selv har laget – en tilnærming som ligner på hvordan syntetiske data brukes i andre avanserte AI-modeller i dag.
In-context LoRA-treningen er den andre nøkkelkomponenten. I stedet for å trene en ny modell fra bunnen, utnytter LipDub de audio-visuelle priorene som allerede er innebygd i LTX-2.3 fra dens originale trening. IC-LoRA-adapteren «styrer» disse priorene mot lipsync-oppgaven uten å endre basismodellen. Det er effektivt og gjør distribusjonen langt enklere – du trenger bare LoRA-vektene, ikke en helt ny modell.
Det er verdt å merke seg at dette er forskning presentert på SIGGRAPH 2026 – en av de mest anerkjente konferansene for datagrafikk og interaktive teknikker. Det gir troverdighet til den tekniske tilnærmingen, selv om beta-statusen signaliserer at det fremdeles er forbedringer på vei.
Hva kommer neste versjon til å fikse?
Betabegrensningene er tydelige signaler om hva som er i arbeid. 8 sekunder er sannsynligvis en minnerestriksjon – 22B-modellen er ikke lett, og å generere lange klipp krever enten mer GPU-minne eller smartere chunking av videoen. Flertaler-støtte er et mer komplekst problem som krever at modellen identifiserer hvem som snakker til enhver tid, noe som er et eget problem i seg selv.
Lightricks har vist med LTX-Video-serien – LTX-2 er en av de sterkeste open source video-modellene som finnes – at de tar iterasjon på alvor. LTX Video 2.3 kom med kraftig ytelseshopp over 2.0. Det er rimelig å forvente at LipDub følger samme mønster.
For nå er dette et solid beta-verktøy for eksperimentering. Korte klipp med én taler – det er det meste av YouTube-innhold, de fleste reklamesnutter og mesteparten av instruksjonsvideoer. Innenfor den rammen er LipDub allerede brukbart for seriøse eksperimenter.
Hva tenker du – er lipsync i én pasning noe du vil prøve? Har du brukt LatentSync eller Wav2Lip tidligere, og er du nysgjerrig på om enkelt-pasnings-tilnærmingen faktisk gir bedre resultater? Si gjerne noe i kommentarfeltet.







